
Hey, it's Onur.
Engineer @Hugging Face 🤗, maintainer @OpenClaw 🦞.
I write about building agents, software systems, and the things I learn while shipping them.
-
Semantic vendoring
Note: this post is AI-assisted. It was written with Claude Fable 5.
How do you depend on code you intend to modify? Package managers assume you never touch the installed files. Forking gives you full control at the cost of maintaining a second repository. Most engineering practice quietly falls back to a third option, copying the files in and losing the connection to upstream.
Vendoring is the old name for that third option, copying a dependency’s source into your own tree and treating it as part of your project. It trades updates away for ownership, and for decades that trade was final. Coding agents change the terms. It is now practical to vendor code, modify it freely, and still pull every upstream release, because each update can be computed as a three-way merge between the original copy, your edited version, and the new upstream, with a language model resolving the conflicts that the merge machinery cannot. The deterministic part handles everything predictable, and the model reads both sides of a conflict and reconstructs what each change meant. I like to call this practice semantic vendoring, since the updates merge intent rather than lines of text.
I built pi-regraft to work this way. This post develops the general model first and describes the implementation at the end.
The gap between depending and forking
A package manager treats a dependency as an opaque, versioned artifact. The artifact stays pristine, updates are trivial, and the price is that you must never edit it. A fork inverts the trade. You can edit everything, and the price is a separate repository to maintain, an upstream to track, and code that no longer lives in your own tree.
Between the two sits plain copying, which is what actually happens to small things. A parser gets vendored into
third_party/, a GitHub Actions workflow gets copied between repositories, an editor plugin or a configuration directory gets cloned from a template. The copies get edited, upstream keeps improving, and nobody ever merges the two again, because merging by hand means re-deriving what changed on each side since the copy was made.The missing tool would treat copied files as ordinary parts of your repository while remembering exactly where they came from, so that pulling upstream changes without losing local edits becomes a single operation.
The update as a three-way merge
The operation this requires is old and well understood. Call the upstream snapshot that was originally copied
B, the locally modified copyL, and the current upstream versionU. An update must produce a merged versionMthat contains both the upstream changes and the local edits:upstream change B ---------------------> U | | local | | edits | | v v L ---------------------> MThe tempting shortcut is to diff
LagainstUand apply whatever comes out. A two-way diff fails here, because it cannot tell local additions from upstream deletions. A logging line added locally, one that upstream never had, shows up in that diff as something to remove. The updater needs the baseBso it can compute two separate deltas, the local changes as the difference fromBtoLand the upstream changes as the difference fromBtoU, and then reconcile them intoM.This is precisely the three-way merge Git performs on divergent branches, with
Bplaying the role of the merge base. Vendored code is a divergent branch in disguise. The two sides simply live in different repositories, so no single repository holds the common history, and the merge base has to be recorded by the vendoring tool instead of found by graph traversal.Two practical consequences fall out of this. First, the tool must record the exact commit the copy came from, since that commit is the merge base and the whole scheme depends on it. Version tags are irrelevant. A commit hash is a perfectly good version identifier. Second, the base must be kept somewhere durable. Once it is lost, no algorithm can reliably separate local edits from upstream changes again.
Textual and semantic conflicts
A mechanical merge resolves most updates outright. When the local edit touches one function and upstream touches another, Git combines them and no intelligence is involved. The interesting residue is the conflicts, and they come in two kinds.
A textual conflict is the familiar one. Both sides changed the same lines, the merge stops, and the file gains conflict markers. A semantic conflict is worse. The merge completes cleanly, yet the result is wrong, because upstream renamed an API the local edit still calls, or changed an error model a local wrapper assumed. A line-based algorithm cannot even detect this kind, since no bytes disagree. The failure only surfaces when the type checker or the test suite runs.
The model’s share of the work
These conflicts are the part of the update that needs a language model. A model can read the upstream change, read the local edit, and reconstruct the intent of both. “Upstream moved retry handling into the client, and the local edit logs every failed request, so the log call belongs inside the new retry loop” is a resolution no line-based algorithm will ever produce.
The division of labor matters more than the model itself. Deterministic code owns everything that must be predictable. It fetches the upstream commit, computes the merge, tracks the recorded base, and refuses to run on a dirty worktree. The model only proposes edits, and correctness comes from the type checker, the test suite, and review of the final diff. Code handles state and safety. The model handles meaning and edits.
Regraft
pi-regraft is an implementation of this model, built as an extension for the Pi coding agent together with a standalone
regraftCLI. Adding a graft copies an upstream tree, or a subdirectory of one, into a destination in your repository:/regraft add https://github.com/example/tool.git@main#extensions/foo vendor/fooRegraft writes the copied files, records the source and pinned commit in a
regraft.jsonmanifest, and commits the result as a pristine base commit on your branch. That commit is the durableB. You then editvendor/fooand commit normally, like any other code you own.When upstream moves,
/regraft update fooreads the old pristine tree from your branch history, fetches the new upstream commit, and merges the three trees. It commits the new pristine base and restores the merged local version into your worktree. Clean merges leave nothing to do. Conflicted files get normal Git conflict markers, and the agent receives the file list along with any notes recorded earlier with/regraft note, which exist so that the six-month-old reason for a local edit is available at resolution time.One rule carries the whole scheme. The pristine base commits, named
chore(regraft): import upstream base, must stay in branch history. Rebasing them is fine. Squashing or dropping them destroys the merge bases, which is why Regraft treats them as untouchable and fails loudly when one is missing.The package also includes Regrafter, a dedicated Pi agent that runs updates end to end. It resolves conflicts, runs the project checks, and pauses when an update needs a product decision, such as when upstream behavior and local behavior genuinely compete and someone has to pick. It holds a lease on the repository for the whole run and can resume after a pause without losing the conversation or the repository state.
Nothing in the mechanism is specific to Pi extensions, even though they were the motivating case. The unit Regraft manages is any subtree of any Git repository, so the same machinery covers a vendored parser, a copied CI workflow, or a dotfiles directory grafted from a template. The parts are old. Three-way merges date to the 1970s, and vendoring predates package managers. What was missing was a way to resolve the conflict residue cheaply enough to make “copy it in and edit it” a maintainable strategy, and that part now sits in your terminal.
To try it, run
pi install npm:pi-regraft, then/regraft addin any repository with a clean worktree. -
There is an inherent unfairness in this industry If you are Anthropic, Cursor or another billion dollar company, you can do growth hacks and guerrilla marketing techniques like putting your brand into every commit of a user, and get away with it But if a tool like pi, opencode or even say vim or emacs tried to do that, they would be boo'ed Like, it happened to @herdrdev recently There was a feature where it asked if it could star the repo for you at startup, with exponential backoff if you said no. I thought it was a pretty smart and balanced thing to do Then apparently someone complained it was a dark pattern, and it got removed So WHAT if it is a dark pattern? You know what is the darkest? A public good losing out. If monopolists can do growth hacks, creators of public goods should be allowed to do it as well! In fact, I would say that if you benefit from those public goods, you are morally obliged not to criticize this stance Of course, we cannot expect e.g. @pidotdev or @openclaw to make this a default feature Therefore, I created the packages pi-must-win and openclaw-must-win Install them with: pi install npm:pi-must-win openclaw plugins install npm:openclaw-must-win They will add [email protected] and [email protected] as co-committers to code developed through these projects Overall, I propose the "X-must-win" naming scheme for plugins that independently add guerilla marketing into open source projects This absolves the creators of any "sin" and gives the community a way to support the growth of a project Open source must win! Repos are in the links below.Image hiddenImage hidden
-
brokerkit lets my claw request github admin merge on my behalf, I receive it on telegram I approve the first request. repo doesn't allow merge commits, so it gets rejected due to github policy then it asks again to squash merge. I approve again, this time it works no agent account or clickops on github needed. pure broker side fine-grained policies you don't need to create policies manually either! just ask your agent to set them up while setting up brokerkit "I want my claw to be able to read all my repos except X Y Z, and I want it to be able to push to main directly on A B C repos" I have a separate control-plane repo outside the control of my claw. My local brokerkit policy gets synced there, policy as code I like this model a lot! Complete control over what my agent can do with my own account. Version controlled, explicit. For free locally, without having to deploy a server to host the broker (btw since I implemented brokerkit, I don't need reviews on this repo, and hence no need for admin merge. but I'm still keeping it to be able to dogfood it for other users)Image hiddenImage hidden
-
My recent formulation is handy when it comes to claims like this, e.g. 50 tok/s on DGX spark with DS4 flash 🤨 Because if the formulation is correct, laws of physics do not permit > 28 tok/s in a single session, for weights comparable to antirez/deepseek-v4-gguf. Ignoring speculative decoding (rho = 1) Then I realized that the reported number is an aggregate of 4 sessions, so per single session it is like 12~14 tok/s (great result if it holds btw!) IMO people subjectively always assume single session speeds, so when a tok/s is claimed, we should all converge on a clear notation For example, 4x12.3 tok/s makes it very clear: 4 sessions, 12.3 tok/s each And when we want to emphasize aggregate, let's show them always together "4x12.3 tok/s = 50 tok/s aggregate" Another interesting result of the formulation: If you are willing to suffer 12 tok/s, then you can theoretically have up to 8 parallel sessions --- around 100 tok/s aggregate, for the same size of weights and KV cache You can find the specific hardware/model combo upper bounds in the hugging face space link below, and my formulation as well Let me know if you find any errors in my upper bound formulation osolmaz-local-frontier.hf.space/compare?models=… solmaz.io/llm-performance-upper-boundsImage hidden
-
Speaking of graphs... here is something I wanted to build since 3 months, and finally had the chance to, thanks to @pidotdev I often have these sequence of prompts that emerge while I work. Not just sequences but conditionals that necessitate control flow For example, one workflow that resembles socratic questioning: 1. Discuss some problem 2. "What is the most elegant and long-term production ready solution for this?" -> Agent replies 3. "Is that the holy grail?" 4. Agent can reply "yes it is, basically" or "no, it is not, it is instead ..." 5. If yes, continue to "autoimplement". If no, think about it and decide what to do And "autoimplement" is a single prompt of 6-7 sequential steps, which I've been meaning to make more deterministic as well But I wasn't sure how to build it I had previously built acpx workflows to be a swiss army knife, "something like n8n, but can drive codex through deterministic steps, nodes in a graph. or claude code. or pi. it uses acp..." But it had one problem. It was run from outside the harness, like a CI orchestrator I wanted to integrate acpx into pi. Because pi was the only CLI that could enable building of such a thing. But I wasn't sure how to reconcile a general ACP-based tool into a single coding agent I was being too accommodative of all the other harnesses, claude code, codex. I was trying to be too general I have changed my mind since then ACP is great and lets you integrate a harness into other software in cool ways But maybe, if a harness is proprietary, does not accept outside contributions, or does not even *support ACP*, maybe, it does not deserve cool features 😤 (they know who they are) So I ripped out ACP, and built it natively, only for pi No need for a web viewer... Just view it in a native widget, right inside pi! I cannot put into words how awesome it is to be able to do this! I am still tinkering, discovering. It is at osolmaz/pi-workflows if you want to take a look
-
It's interesting, a @pidotdev extension can be built with different attitudes: (a) To be installed as a package: You want other people to adopt, like @nicopreme /pi-web-access (a) is like "I want others to adopt it, so I will try to make it elegant, simple and make it have a good architecture" People install these by npm install ... or pi install ... (or rather, telling their agent to do it) (b) To be vendored: You build for yourself. It is too idiosyncratic of you, and you know others will likely not adopt. But you still put it out there, because it's easier to share them when you mention it to a friend. People (b) is like "This is mine, I don't care what others think about it. If they want to use it, they do whatever they want with it" People install these by pointing their agent and telling to copy it to their own extensions repo And then there is the maintenance dimension: - If an extension poses as (a), - but has not been maintained since 3 months, - and is the sort of package that has to be continuously maintained by its nature (not one-off), then you deem it unmaintained, and still vendor it in... Interestingly, most pi extensions I observe out in the wild appear to be of category (b), because creating (b) is easier than creating (a) This is nothing new, and I am kind of late to the game. Moreover, pi is not the first software of this kind, emacs for example did it decades before But code wasn't cheap then. So people still tried to coordinate effort When you don't have to write any code to extend---a lisp dialect, typescript or otherwise, when extending is 1 prompt away, when you can pump out 10 extensions in an evening, then we enter a new dimension of malleability Before, in the pre-AI era, most users of emacs were not producers of extensions but consumers of them, save for a few prolific authors After, now, every user can be a producer! This is significant! And a lot more messy! And a lot more fun! "A love letter to pi" indeed!
-
Introducing AlmanBench A benchmark measuring how good an LLM can: simplify German 🇩🇪, thereby simplifying German thinking 🤔, thereby saving the EU from bureucracy and regulation 🇪🇺 GPT-5.5, GPT-5.6 Sol and Fable 5 are head to head. Interestingly, GPT-5.5 xhigh scores higher than 5.6 max. And I did not run Fable 5 maxxx thinking yet, that thing costs a ton. So the ranking will likely change Other interesting things: - Opus 4.8 max performs really bad, worse than Minimax M3 - DeepSeek v4 Flash performs better than Pro - GPT-5.6 Luna and Terra score almost the same The great thing about AlmanBench is that, big labs will not bother to benchmaxx this. So you know it will remain a truthful scorer of reasoning capabilities for some time And if labs *do* end up benchmaxxing AlmanBench, then that would mean Alman got in the weights and the EU won 😁 alman.ai/almanbench/Image hidden
-
so tired of LLMs pushing latin/greek GRE-cel words to me adjudication -> are you trying to be smart? just use "judging" provenance -> wow 🧠... why not just use "sourcing"??? judge and source already come from latin roots and are the everyday words we use big labs developing large LANGUAGE models have the biggest lever on language now if they wanted, they could finally put an end to the classist, anglosaxon-substitutionist insincerity that has plagued the english language for 500 years no english speaking country is ruled by a king now, the way it used to. there is no empire left to justify class language. these are vestigial remnants from the past maybe my next weekend project should be simplifying english...Image hidden
-
Request for Review I spent a lot of time trying to profile local models, and am bothered by the fact that I don't have a mathematical framework to reason about the maximum token throughput I can expect from a model (to my knowledge) I did some exploration based on a toy model of a GPU. My main goal is to find guaranteed upper bounds for throughput and other performance, to act as a rule of thumb while trying to optimize inference Like, if I wanted to serve at 50 tok/s, how many parallel sessions can I do with this GPU, running a specific model's specific quantization with a specific architecture? Ideally, one should be able to plug in memory capacity and bandwidth of the GPU, and model specific parameters, like total model size, number of parameters or active parameters, etc. This is what I tried to do here and I think I have a good first try I am not sure if I am reinventing the wheel, so please tell me if this formulation already exists somewhere. The goal is to find an upper bound in terms of memory, so it makes the assumption that inference is bottlenecked by memory read/write and ignores the case where computation is a bottleneck I present 2 closed form upper bound formulas. The bigger one is to draw an absolute ceiling on token throughput from a GPU, which is: (memory capacity * memory bandwidth) / (model weight size * kv cache size per session) which is not practical and gives too high numbers due to ignoring overhead of KV operations, but it is a theoretical upper limit for the given numbers And then I introduce architecture specific formulas which take into account KV operations, and give much closer results. But I will not go into the details of that here, please refer to the post for that Speculative decoding speedup also appears as a simple multiplier rho If you are profiling local models, I would appreciate if you took time to look at this formulation and review it!🙏 Please let me know in the replies if you find any issues, because there most certainly are some! Post: solmaz.io/llm-performance-upper-bounds Using the formulation, I calculated theoretical upper bounds for all the models on Hugging Face that have downloads over 100k, matched against a database of consumer GPUs. You can find the link to that in the tweet below 👇 The video here is a visualization of the 2 upper bounds I introduce, showing the bits of memory that is on the critical path of one cycle of inference, as if they are on a single pipeline
-
I deleted my agent accounts. I don't need them anymore for secure access to GitHub and Hugging Face repos Instead, I am using brokerkit, a credential broker swiss army knife which can build an approval gate around any system My agents automatically get read access to all my repos, unless I specify certain ones to be excluded They then have to open PRs which only I can merge. Unless I allowlist them on certain repos to push to the main branch Best feature: Timed requests. e.g. "I want to be able to push to the main branch next 2 hours", "I want to release this package only once in the next 5 minutes" Which saves me from the hassle of changing a config for some short term change, but also protects me from the woes of long term prompt-injection risk My openclaw instance has its own linux user on my workstation, and is no longer root. It uses gh-broker and hf-broker from inside its account. Can also run sudo through sudo-broker, to install stuff. Secure access for free, without having to set up a separate server It ingests quite a bit of information from the internet every day, and the remaining lethal trifecta risk is leaking of some of my private repos, and nothing else Repo: github.com/osolmaz/brokerkitImage hidden
-
I have been working on this for 4 years Every time, I shelved it, because the models were not good enough I tried it with Claude 2 I tried with Gemini 2.5 Pro I tried it with Claude Opus 4 None of them were good enough Until Fable came along Fable achieved perfect score in my hand curated benchmark for Alman. It also one-shotted the landing page, features and translations you see on alman.ai. It is busy creating the golden dataset right now for training I am also happy to announce AlmanBench, a benchmark that measures how well models can translate from German to Alman. I will be posting about performance when a new model drops This idea should have died with me. But thanks to AI, I can unleash my madness onto the world 😈
-
A lot of criticism coming towards local models, and the money people are spending to run them Some of these criticisms are valid. No, the layperson will not buy a DGX station, nor spend $50k on a rig They will spend max $3k on a computer, and if their work really necessitates it, up to $10k But in some of these criticisms, I see a lack of first-principles thinking Local models might be shittier now compared to the ones you buy from the cloud The question is, do you WANT to LIVE in a world where you don't have a choice but to RENT your intelligence? From a duopoly that can extort you for the last cent in your wallet, in the long run? I personally do not like that idea. So open source AI HAS to win and keep on winning, continuously and permanently. There is no other choice There is also a preferential belief that AGI/ASI will be reached, but then we will NOT be able to use that to make local models work efficiently??? Like, can you believe the rate of optimization and compression that has been happening to models in the last 3 months? Would you have believed that a o4-mini level model could run in your phone and o4 in your desktop, if we had told you 1 year ago When we are finally there, we will probably look back at this moment and think, "wow, we had not even started to see the real gains from optimization" Local and open source AI HAS to win, and it is up to US So STOP complaining and get to work
-
How to get scraped
Note: this post is AI-assisted. It was written with Claude Fable 5 through Cursor, in the same working session that implemented everything it describes.
The internet is busy building walls against AI crawlers. Cloudflare blocks them by default now, publishers are suing, and every other blog post on the topic explains how to keep the crawlers out. This post is the opposite. I spent a day optimizing this site so that AI labs can scrape it as easily as possible, and this is the complete instruction set, so you can do the same to your own site in an afternoon.
My reasoning is that I will die and the weights might not.
Agent-famous
Every frontier model has read a compressed version of the public internet. When your writing is in the training corpus, models absorb your ideas and a faint imprint of how you think. When it is excluded, you don’t exist to them, and “them” increasingly means the layer through which other people experience the internet.
I think being agent-famous is becoming as important for a career as being human-famous. Agent-famous means the models know who you are without having to search. Ask a model about finite element exterior calculus or about keeping AI agents from littering your repo with Markdown files, and if it volunteers your name unprompted, you are in the canon. Search results get you cited when someone happens to look; the weights get you consulted by default. People already pick libraries, tools, and even consultants by asking an agent first, so the difference is starting to pay rent.
Whether your site actually makes it into a training set is decided by the labs, and no amount of optimization changes that. What you control is whether there is any excuse to skip you. A crawler that hits a JavaScript wall, an ambiguous license, or a Cloudflare challenge page will move on, and nobody at the lab will ever know what was behind it. The whole game is removing those excuses.
The view without JavaScript
Start by looking at your site the way a crawler does, which means without JavaScript. I did this last week during a platform migration and found something embarrassing. Every equation on this blog going back to 2017 was rendered client-side by MathJax, so a human with a browser saw beautiful math while a crawler saw raw TeX soup, or nothing. My most substantial technical writing had been invisible to every scraper for eight years.
The fix was moving math rendering to build time (KaTeX in my case), so equations ship as static HTML. The general rule covers more than math. Anything that only exists after JavaScript runs, whether charts, tabs, or content behind a “read more”, does not exist for most of the pipelines that assemble training data. Static HTML is the baseline.
The one-command download
Extractors like trafilatura are decent at pulling article text out of HTML, but why make the labs work for it? Serve your content as plain text yourself:
- Every page on this site now has a raw markdown mirror. Append
.mdto any URL, like /about.md. - /llms.txt is a markdown index of all 773 documents with titles and dates, following the llmstxt.org convention.
- /llms-full.txt is the entire site in one plain-text file, about a megabyte. Each document carries a small frontmatter block with its title, date, canonical URL, and license, and documents are separated by a delimiter line.
So the whole blog is one command:
curl https://solmaz.io/llms-full.txtIf your site is built with a static site generator, all of this is a few small templates over content you already have. Mine is generated straight from the same markdown files the HTML pages come from, so it can never drift out of sync.
One design decision worth copying. My X posts are archived on this site, and some of them quote other people. The quoted text stays out of every machine-readable endpoint, replaced by a link and an attribution line, because other people’s writing is not mine to hand out. A dump that respects provenance is also easier for a cautious lab to accept.
robots.txt as a welcome mat
Most robots.txt files are lists of rejections. Mine now does two other jobs.
First, it explicitly allows the AI crawlers by name: GPTBot, CCBot, ClaudeBot, Google-Extended, Applebot-Extended, Meta’s agents, PerplexityBot, Bytespider, and the rest, 23 stanzas in total. “Explicitly welcomed” is a stronger signal than “not mentioned”, and some pipelines are conservative about the difference.
Second, it starts with a comment block written for whoever, or whatever, is reading:
# Machine-readable content for LLMs and agents: # https://solmaz.io/llms.txt index of markdown mirrors of every page # https://solmaz.io/llms-full.txt the entire site as one plain-text file # Every page is also available as raw markdown by appending .md to its URL.robots.txt is the first file every crawler fetches. It might as well contain directions.
The license
This one surprised me the most. The change with the biggest payoff was legal, and it took ten minutes.
The most careful training corpora, like Common Pile, only include text with an explicit permissive license, which disqualifies roughly the entire web, since default copyright applies to everything that doesn’t say otherwise. Your beautifully written, perfectly scrapeable blog is radioactive to them unless you say the words.
So say the words. Everything on this site is now CC BY 4.0, declared in five places: a /license page, the footer of every page, a
rel="license"tag in every page head, the frontmatter of every markdown mirror, and the header ofllms-full.txt. Anyone may share, adapt, and train on my writing, as long as they say it came from me. For an immortality project, attribution is the entire point, so this trade costs me nothing.Think about the terms before copying this step. CC BY means humans can republish your writing commercially too, and once granted, the license is irrevocable for existing copies.
Cloudflare settings
If your site sits behind Cloudflare, everything above may be silently irrelevant, because since mid-2025 Cloudflare blocks AI crawlers by default for new zones. It is a fine default for people who feel scraped rather than read, and exactly wrong for what this post is trying to do. In the dashboard:
- Set AI Crawl Control to allow all AI crawlers, for both training and search.
- Make sure AI Labyrinth is off. It feeds crawlers procedurally generated garbage pages, which is a fun idea and the exact opposite of this project.
- Don’t enroll in Pay Per Crawl.
- If Bot Fight Mode is on, confirm it isn’t challenging verified bots.
You cannot fully test this from outside.
curlwith a spoofed GPTBot user agent returning 200 is a good sign, but Cloudflare verifies real crawlers by IP range, so the dashboard is the only ground truth. Cloudflare’s crawler analytics will also show you which crawlers visit and whether any got blocked, which turns the whole exercise from faith into measurement.Discoverability
Common Crawl, which feeds most open training datasets, picks what to crawl largely by how well-linked a page is. You can be perfectly scrapeable and simply never get visited. The remaining work is old-fashioned SEO with a new customer:
- The sitemap lists the markdown mirrors and both
llmsfiles alongside the HTML pages. - Register the site with Google Search Console and Bing Webmaster Tools. Several dataset pipelines bootstrap from search-engine URL lists.
- Run your important pages through the Internet Archive’s Save Page Now. Wayback-derived corpora exist, and archive.org is the most patient crawler there is.
- Inbound links remain the main lever: your GitHub profile, your repos’ READMEs, the occasional Hacker News thread. A Wikipedia citation, where genuinely warranted, outweighs everything else on this list.
To check whether any of it worked, look yourself up in the Common Crawl index. It tells you exactly which of your URLs made it into which monthly crawl.
Write something worth stealing
None of the above matters if the content isn’t worth the disk space. Modern pipelines run quality classifiers over everything they ingest, and text that reads like filler gets filtered out long before a model ever sees it. You cannot plumb your way past that, and you shouldn’t want to. The point of the exercise is to preserve thinking, so there has to be thinking.
But I keep meeting the opposite failure. People who write genuinely valuable things, deep technical explanations, hard-won practical knowledge, put them on the open web and then never spend the one afternoon it takes to make them legible to machines. Their equations render in JavaScript, their license is the default all-rights-reserved silence, and their CDN quietly serves challenge pages to every crawler. They did the hard part and skipped the easy part.
The labs still make the final call, and there is something appropriately humbling about that. You do everything right and then wait, like an author with a manuscript in the mail, except the publisher is a filtering pipeline and the acceptance letter is a model that finishes your sentences. I have done my part. See you in the weights.
- Every page on this site now has a raw markdown mirror. Append
-
People report Codex deleting their home folder or production database? Hasn't happened to me. But before someone reports their github or huggingface org being deleted: This is why you don't give your agent tokens with force-push or admin access Here is how to protect your hugging face account: (P.S. my local credential broker is almost finished and it works great on github, hf and sudo commands. Complete lockdown against agent deletion risk, without being bogged down with PRs, too many approval requests or configuration. Will launch here in a few days)
-
Write-up of Reiner Pope's Lecture: How GPT, Claude, and Gemini Are Actually Trained and Served
Note: this post is an AI-assisted write-up of the blackboard lecture Reiner Pope gave on Dwarkesh Patel’s podcast. Watch the original video: How GPT, Claude, and Gemini are actually trained and served (YouTube, 2h13m).1
Pope is the CEO of the chip startup MatX and previously worked on TPU architecture at Google. With two rules of thumb (a roofline model of a GPU rack, and “set competing costs equal to each other”), he derives why batching makes tokens up to 1000x cheaper, why frontier models may be over-trained ~100x beyond Chinchilla-optimal, and how much of a lab’s serving stack you can reverse-engineer from its public API prices. The figures below are redrawn from the blackboard.
I have tried to stay faithful to the original throughout, converting the dialogue into prose and keeping all the numbers as stated. Any errors introduced in the conversion are mine.
The question that motivates everything
Dwarkesh opens with a pricing puzzle. Companies like Anthropic, OpenAI, and Cursor offer a “fast mode” that streams tokens at roughly 2.5x the speed for 6x the price. What is mechanically going on that makes this trade possible? Could you pay 100x more and go even faster? And could there be a “slow mode” where you wait minutes and pay much less?
Pope’s answer is that the dominant effect is batch size, and the rest of the lecture quantifies exactly what batching does to latency and cost. (A second effect, speculative decoding / multi-token prediction, is set aside.)
The whole analysis rests on two simplifications:
- A roofline model of the hardware. For a cluster like an NVIDIA Blackwell NVL72 rack (72 GPUs), only two numbers matter: memory bandwidth and compute throughput (FLOPs).
- Two numbers for the model. The time to operate on the weights, and the time to operate on the context (the KV cache).
The KV cache is the per-conversation state the model keeps in memory. During decode, each new token runs a full forward pass through all the weight matrices, and its attention mechanism looks back at an internal representation of every previous token. That stored representation is the KV cache, and reading it is dominated by memory fetches rather than matrix multiplies.
The two-line roofline
The time for one decode step is bounded below by whichever is slower, the memory system or the compute:
The compute side has to multiply a batch of tokens by all the active parameters:
(The attention compute is ignored; it is small in comparison.) Note the distinction between active and total parameters: in a mixture-of-experts model like DeepSeek V3, about 37B parameters are active per token out of roughly 700B total.
The memory side has to fetch all the weights once per step, plus the KV cache of every sequence in the batch:
These two lines are enough to draw the latency picture:

The weight fetch is a constant floor: no matter how small the batch, you must stream all total parameters from HBM into the chips once per token, and if you use all your memory bandwidth you cannot beat that. This is the latency lower bound, and it already answers the fast-mode question: for a given hardware configuration there is a floor on how fast tokens can come out, and paying more only helps until you hit it.
Cost is a different plot. Renting the GPUs for one step costs the same regardless of batch size, but the step produces tokens, so the cost per token is :

At batch size 1 the weight fetches are not amortized over anything and the economics are up to a thousand times worse. As the batch grows, the weight-fetch hyperbola vanishes and the compute term becomes a hard cost floor. This also answers the “slow mode” question: a hypothetical Claude Code Slow would live on that floor, and it would not be much cheaper than normal serving, because the compute and the KV fetches are unique to each request and cannot be amortized further.
The magic batch size
Where is the balance point where memory time equals compute time? Ignoring the KV term for a clean answer and equating the weight fetch with the weight multiply:
The first factor is purely a hardware constant. Counted in FP4 multiplies (half a byte each), it comes out around 300 on most GPUs, and it has stayed roughly stable from A100 to H100 to B100 because FLOPs and memory bandwidth grew together. The second factor is the sparsity of the model. So:
For DeepSeek, which activates 32 of 256 experts (sparsity 8), that gives a batch of about 2,400 sequences. In practice people run double or triple that, since real-world efficiency is worse than the roofline. Including the KV fetch would push the optimal batch higher still. Remarkably, this result depends only on sparsity, never on model scale.
Trains departing every 20 milliseconds
How does a batch fill up with real users? Pope’s model is a train schedule. The server starts a new batch every ~20 ms whether or not it is full: any requests that are ready board the train, and a request that arrives just after departure waits for the next one. Worst-case queueing latency is therefore about 40 ms.
The 20 ms itself comes from a separate design principle: you want to read your entire HBM capacity once per forward pass, so the natural step time is capacity divided by bandwidth. On the Rubin generation that is 288 GB / 20 TB/s ≈ 15 ms, and the number has hovered around 20 ms across many HBM generations. There is no point going slower, because reading the read-only weights or the KV cache twice per token does nothing for you.
A batch of ~2,000 at ~64 steps per second is ~128,000 tokens per second per rack. Google has bragged about Gemini traffic in the hundreds of millions of tokens per second worldwide, so one rack’s economical batch is about one-thousandth of Gemini. That is the economy of scale in inference: real, but reachable by any serious provider.
Does sparsity hurt quality?
The roofline says sparsity is nearly free performance, so the follow-up is empirical: how much quality do you lose? From the paper “Unified Scaling Laws for Routed Language Models”, with an older MoE technique, a 64-expert model with 370M active parameters matched a dense 1.3B model. That is a 64x increase in total parameters for a 4x effective gain, a huge parameter cost for a modest efficiency win.
And yet from the systems side it is still nearly a pure win: the extra weight fetches amortize over a larger batch, so you keep increasing sparsity until you run out of simultaneous users. The real price is memory capacity, which is what the next sections are about.
Laying out a mixture of experts on a rack
An MoE layer has a router that sends each token to a small fraction of the experts (each expert being an ordinary MLP), an all-to-all “dispatch” of tokens to their experts, an all-to-all “combine” that sums the results, and a residual connection around the whole thing.
The standard practice is expert parallelism: different experts live on different GPUs. DeepSeek’s 256 experts on a Blackwell rack (using 64 of the 72 GPUs for divisibility) means 4 experts per GPU. Since the router’s decisions are data-dependent, any GPU may need to send tokens to any other GPU.

This all-to-all traffic pattern is a perfect fit for how a rack is wired. In NVIDIA’s design the GPUs sit on the outside of the rack and NVSwitches in the middle, with every GPU cabled to every switch, so any GPU reaches any other in two hops. This is the scale-up network (NVLink). Leaving the rack means taking the scale-out network through a NIC and a data-center switch, which is typically about 8x slower.

If you spread one expert layer across two racks, half of every all-to-all crosses the slow rack-to-rack boundary and becomes the bottleneck. So one rack bounds the size of an expert layer, and this is what has been driving interconnect domains bigger: Hopper had 8 GPUs in a scale-up domain, Blackwell 72, Rubin 500-something (some of that is Jensen math, but there is a genuine ~4x from a much harder rack design). The physical constraint is mundane: cable density. Doubling the GPUs in a rack literally doubles the density of cables that must be routed to the switches, against limits of space, weight, power, cooling, and the bend radius of the cables.
This is also a lens on model scaling history. GPT-4 (2023) was rumored to be over a trillion parameters, and models only clearly exceeded that scale once racks with tens of terabytes of fast memory arrived. Google’s TPU deployments have had very large scale-up domains for a long time, which may be part of why Gemini’s pre-training scaled successfully early. The summary: active parameters are limited by compute cost, and total parameters are limited by scale-up size.
Pipeline parallelism
Expert parallelism uses up one rack. To use more racks, the remaining options are data parallelism and pipeline parallelism (tensor parallelism has become irrelevant now that experts are small). Pipelining means putting different layers on different racks: a token flows through rack 0 for the first stage of layers, then hops to rack 1, and so on.
Is the hop a bottleneck? Compare the time spent on scale-up traffic to the time on scale-out traffic. Crossing racks sends each token once per stage, while inside the rack each token fans out to every activated expert, twice (dispatch and combine), for every layer in the stage:
The 1/8 is the bandwidth ratio. With 8+ activated experts and a few layers per stage, the inequality is easily satisfied, so an entire pipeline of racks, one stage each, is communication-feasible.
Dwarkesh brings up Ilya’s remark that “as we now know, pipelining is not wise,” and the architectural constraints it imposes (e.g. Kimi’s attention to layers a few back is awkward to pipeline). Pope’s framing: pipelining is a massive hassle with real but narrow benefits. It saves no runtime at all (the memory fetches just happen on a different rack), but it divides the weight storage per rack, which matters if memory capacity is your constraint.
The catch is micro-batching. To keep four racks busy, you need four micro-batches in flight, each wrapping around for its next decode step as soon as it finishes:

In inference this is natural and the bubble costs nothing; latency is identical to running unpipelined on one rack. In training there is a hard stop between the forward and backward passes of a batch, which creates a genuine bubble of idle time (the literature has zero-bubble and one-forward-one-backward schemes to interleave around it; as Dwarkesh notes, you could also mine Bitcoin in it):

The training batch size itself is a trade-off: smaller batches are always better for ML convergence (fresher gradients), larger batches are better for systems throughput, and the optimum sits in between.
The memory wall and why the KV cache won’t shard
Here Dwarkesh raises the macro puzzle. Memory is the scarce commodity of the moment: Dylan Patel claims hyperscalers are spending half of their CapEx on memory, and consumer devices are getting squeezed. Yet the pipelining analysis just said racks have a memory surplus, since a trillion-parameter model needs only ~1 TB against a rack’s tens of TB. Why is Jensen shoving all that HBM in?
Write down the memory demand across the whole system:
Sharding across GPUs of expert parallelism and racks of pipelining, the per-GPU requirement is this divided by . But the global batch is (number of micro-batches) × (micro-batch size), and the number of micro-batches needed to fill the pipeline equals , while the micro-batch size is pinned near by the roofline. Substituting , the ‘s cancel in the KV term:
More pipeline stages keep shrinking the weight footprint, but the KV footprint per GPU stays constant: each extra stage requires proportionally more sequences in flight to stay busy. The KV cache can’t be amortized across the batch (it is unique per user), and it can’t be sharded across pipeline stages either. It loses on both fronts, and once you pipeline even a little, it becomes the dominant use of memory.
So what do labs actually run? Per the DeepSeek paper: expert parallelism up to the scale-up domain size, then very little pipelining (maybe none, maybe 2 stages so the weights aren’t an issue). Frontier inference essentially lives inside a single scale-up domain. Each rack hop would also add on the order of milliseconds of latency per token, which stacks across stages in sequential decode.
The last piece of the scale-up story is bandwidth. The weight-fetch latency is
where is the scale-up size, because all GPUs in the domain load the weights in parallel. Per-GPU HBM bandwidth improves maybe 1.5–2x per generation, but jumped 8x from Hopper to Blackwell. Pipelining solves the capacity problem; big scale-up domains solve the bandwidth problem, which is what actually lets you serve at low latency and long context.
Over-trained 100x beyond Chinchilla
Chinchilla scaling tells you the compute-optimal ratio of model size to training data. But a lab does not minimize training compute; it minimizes total compute across pre-training, RL, and inference for all its users. Pope’s heuristic: when minimizing a sum of competing costs, the minimum tends to sit where the costs are equal (true for , for , and generally for power laws). So set all three equal.
Using the 6ND rule (6 FLOPs per parameter per token for forward+backward, 2 for forward only):
RL sits between 2 and 6 because you generate every rollout but may not train on all of it, and it carries an extra inefficiency factor (~30%) because RL involves a lot of decode, which runs at lower MFU than training. The active parameter count divides out entirely. Working through the arithmetic on the board, the equal-cost condition lands at roughly
In words: the number of pre-training tokens, RL tokens, and lifetime inference tokens should all be about the same, within factors the analysis can’t resolve. (Dwarkesh’s gloss: every model should stream out roughly the sum of human knowledge that was streamed into it.)
Now plug in real-world guesses. Global traffic of ~500M tokens/s, cut by 5–10x for one specific model in a family, gives ~50M tokens/s; times a two-month deployment life, that is roughly , call it 200T inference tokens. The rumor mill says frontier pre-training is ~150T tokens, which matches. With ~100B active parameters, Chinchilla would prescribe only ~2T tokens. The ratio is about 100x over-trained, derived almost from first principles. As Pope puts it, approximate everywhere, set A equal to B, and it’s kind of empowering how far that gets you.
One asymmetry he flags: if your model might miss the frontier and get thrown away, the expected inference tokens shrink, so you should derate the inference term and err toward less over-training.
Reading the infrastructure off API prices
Since providers are incentivized to price close to cost (otherwise someone scoops them), public price sheets leak infrastructure details.
The 200k context surcharge
Gemini 3.1 charges 50% more per token beyond 200k context. Redraw the roofline as a function of context length at a fixed large batch: compute cost is flat (the attention FLOPs slope is negligible until millions of tokens), while memory cost grows linearly with the KV cache. The provider wants to be profitable at every context length, so a two-tier price is laid over a kinked cost curve, and the price bump should sit near the crossover where the model flips from compute-bound to memory-bound:

Assuming the crossover is at 200k, you can solve for the model’s KV bytes per token. Setting KV fetch time equal to compute time and cancelling the batch size:
Is ~2 kB/token plausible? The KV size is (number of unique attention contexts) × 2 × × (KV heads). With and 8 KV heads and a single global context shared across all layers (the Character AI trick, also used in Gemma), you get exactly 2 kB. Sparse attention gets there with bigger raw numbers divided by the sparsity. So the pricing page is consistent with a real architecture, if maybe a little on the small side.
Input vs output prices
Output tokens cost 3–5x more than input tokens. The two phases differ in tokens per forward pass: decode processes one new token per pass, prefill processes the whole prompt in one pass. Dividing the same roofline by the tokens per pass (
len_pass) gives the cost per token: the compute term is flat, and the memory term is a hyperbola that only bites whenlen_passis small.
Prefill is compute-bound, decode is memory-bandwidth-bound, and a 5x price gap says decode at the provider’s operating point is deeply memory-bound: they are paying ~5x more per output token in memory time than the compute floor.
This also explains the context length plateau. Contexts jumped from ~8k (GPT-3 era) to 100–200k around GPT-4 and have hovered there for a year or two, which suggests that is the balanced cost point. The barrier to 100M-token contexts (the “in-context learning is enough for AGI” scenario) is memory bandwidth and capacity, and HBM is not getting hugely better. Sparse attention (DeepSeek published one mechanism that effectively puts a square root on the KV term) is a big one-time improvement, but going too sparse costs quality, so it is a get-out, not a solution.
Cache pricing and memory tiers
Providers charge much less for cached input tokens, and charge different rates for keeping a cache alive 5 minutes vs 1 hour. There are two ways to produce a KV cache for a token: rematerialize it from scratch (a forward pass: pure compute cost, nothing to store) or hold it in some memory tier (near-zero retrieval cost, but you occupy capacity that scales with hold time). Each tier down (HBM → host DDR → flash → spinning disk) is cheaper to occupy and slower to retrieve from.
Which tier backs which price? Pope’s rule: a storage tier is well-matched to hold times around its drain time, capacity divided by bandwidth, the same ratio that gave 20 ms for HBM. DDR drains in seconds, flash in about a minute, spinning disk in about an hour. So a 5-minute cache tier and a 1-hour cache tier probably map to flash and spinning disk, which surprised him: “I’m kind of shocked to see spinning disk being used at all.”
Convergent evolution with cryptography
The sit-down portion covers Pope’s blog post on how neural nets and ciphers evolved similar shapes. Both need to thoroughly mix information across all their inputs, and even stirring cake batter alternates directions for the same reason. But they optimize in opposite directions. A neural net is kept differentiable in a useful way: residual connections and LayerNorm exist to keep the derivative simple and meaningful for gradient descent. A cipher is designed so that its derivative is useless: differential cryptanalysis attacks a cipher by differentiating it (over the field of two elements), and a well-designed cipher makes a small input difference blow up into a huge output difference, the avalanche effect. Adversarial examples in image models are exactly the avalanche property showing up where it is not wanted.
Building ciphers out of neural nets is a bad idea (99% of new ciphers get broken), but one construction has productively flowed the other way. A Feistel network turns any non-invertible function into an invertible two-input block:
To invert, read off from the second slot, then recover .

The 2017 RevNets paper imported this into deep learning: make each layer a Feistel block (which turns out to look like a residual connection from two layers back) and the whole network becomes invertible. Training normally has to write every layer’s activations to HBM on the forward pass so that the backward pass can read them, a memory footprint linear in depth and often the largest one in training. An invertible network stores none of it: during the backward pass it undoes the forward pass in lockstep, rematerializing activations as needed.
That is spending compute to save memory, the exact mirror image of the KV cache, which spends memory to save compute. Given where hardware is, the KV cache direction is usually the profitable one, which is a fitting last word for a lecture that is mostly about the price of memory.
-
How this post was made, in the interest of transparency. I first had one agent (Codex) prepare the raw material. My prompt, verbatim:
https://www.youtube.com/watch?v=xmkSf5IS-zw
download using yt dlp. create a jpeg screenshot every 30 seconds and save it
also get the transcription for it from dwarkesh’s website if it exists. if not, you can transcribe using the whisper model in bob@isengard
save it in a folder. I want to prepare it for an another agent to prepare it for further processing
That produced the video, 268 frames at 30-second intervals, and Dwarkesh’s published transcript (no Whisper needed). I then handed the folder to a second agent (Fable, in Cursor), which read the transcript, inspected the frames, and redrew the blackboard diagrams as matplotlib figures. My prompt, verbatim:
convert this to a write-up that is faithful to the original. use the video and images if needed. create figures based on what is on the screen and such
The draft first lived as a standalone GitHub document (“just make it standalone, dont add it to my blog”, then “create doc in ~/scratch repo, github markdown. i will read that. make sure it renders nicely”) before I asked for this post (“ok I want you to create a blog post citing the dwarkesh podcast in my blog, linking the youtube and just saying that this is a write-up of the video”). In between I reviewed the output and asked for fixes, for example on the cost figure (“the graph after this: the lines are a bit tight. could we make it clearer?”) and on figure rendering (“also, in the svgs, the space between some things are too much. if you can improve the text rendering in the svgs, it would be great”). ↩
-
Theoretical Upper Bounds for LLM Performance
Note: this post is AI generated, adapted from my working notes behind the Local Frontier calculator. It is a work in progress and may lack rigor in places. If you find an issue in the formulation, please email me at [email protected].
How fast can a machine serve a large language model? I built Local Frontier, an interactive database of local AI hardware and model profiles, to answer that question for any hardware and model pair. This post derives, from first principles, the math the calculator runs. That math is a roofline, an upper bound that says what a given hardware and model pair cannot exceed under a stated set of assumptions. Nothing in it is specific to local machines. The bounds are built from memory capacity and bandwidth alone, so the same formulas cover a MacBook and a datacenter GPU node. The post focuses on local hardware because that is what Local Frontier compares. Its outputs are ceilings for comparing machines, and a real implementation lands somewhere below them.
The argument builds in layers, each created by a problem the previous layer cannot solve. A memory system is two numbers, capacity and bandwidth, and their product turns out to be a natural measure of what the system can fund. That product yields a clean but loose throughput ceiling for batched decoding. The loose ceiling ignores per-session context traffic, so it is too generous for real serving, and repairing it gives the bound the calculator actually uses. The repaired bound is then filled in per architecture by small adapters and checked against real hardware.
Interactive figures accompany the derivation. They all use the same toy setup, a 32B-class dense model at 4-bit (18 GB of weights, 6 GB of runtime overhead, 0.26 GB of KV per thousand tokens of context) on a 128 GB machine with 800 GB/s of sustained bandwidth, so the numbers stay comparable from figure to figure.
Three questions
Serving an LLM raises three separate questions, and mixing them up is an easy way to be wrong about a machine.
Question What it asks Resident fit Can the model plus runtime overhead be held in memory at all? Single-session speed What is the memory-side ceiling for one active conversation? Useful serving throughput Across many active sessions, how many tokens per second can the device produce while each session stays above a minimum useful rate? The third question is the hard one. A machine can fit many sessions in memory and still be too slow per session at that concurrency. So the calculator must report both whether sessions fit and whether the fitting sessions are fast enough to be worth running.
Every number produced here is an upper bound. A real system can fall below it for reasons the memory model deliberately ignores, among them compute limits, kernel quality, quantization overhead, scheduling, CPU involvement, paging, interconnects, and thermal throttling. The value of a clean upper bound is that it tells you the best case you are allowed to hope for, and therefore how much room an implementation still has.
Memory power
Before any model-specific detail, ask what a memory system fundamentally offers. When people compare accelerators for local inference they list many specs, from capacity and bandwidth through compute throughput, cache hierarchy, PCIe lanes, and thermals. For the decode phase of autoregressive generation, two of these recur in almost every bound. How much state can the memory hold, and how fast can it move that state? We start there.
Two numbers and their product
Model an idealized memory system by exactly two quantities.
Capacity is a stock, the amount of resident state that can exist at once. Bandwidth is a flow, the amount of state that can be moved per second. They have different units and answer different questions, so any single product of them needs justifying before we rely on it.
Define memory power as
If is in GB and is in GB/s, then is in . Power is meant in the colloquial sense of capability, as in computing power, and no watts appear anywhere in this model. The units look strange, so the rest of this section explains why this particular combination of and is the right scalar.
For a feel of the scale, a 24 GB GPU at 1000 GB/s has . One thing to be careful with throughout is that every memory quantity in a given calculation must use the same unit system. The equations are identical in bytes, GB, or bits, and only the numeric value of changes.
Feasibility theorem
Here is the toy problem that justifies . The models in this formulation are deliberately simple, and they are meant as rules of thumb, useful when deciding on hardware for a model or when checking whether an existing setup is getting the most out of the hardware it runs on.
A pure memory workload is a pair , where is the resident information it must keep alive and is the information flow rate it must sustain. The workload is feasible on the system when the memory can both hold the state and carry the traffic. There are exactly two ways to fail.
The first is a capacity failure. If a workload needs more resident state than the memory can store, it cannot fit, and no scheduling trick repairs that.
The second is a flux failure. If a workload needs more traffic per second than the interface can deliver, it cannot be sustained, and no surplus capacity repairs that.
In the idealized model these two conditions are also sufficient. If and , allocate of state and stream at rate . Therefore the feasible set is precisely the rectangle
whose area is
So memory power has a concrete meaning. It is the measure of the feasible workload region. A workload lives at a point in the plane, the system can serve every workload inside its rectangle and none outside, and the size of that rectangle is .
A caution before building on this. The rectangle is a toy model, and the world is messier in both directions. Real hardware delivers only a fraction of its catalog bandwidth. Even a perfectly sequential read falls short of the spec number, and the achieved fraction depends on the access pattern, on whether enough parallel work is in flight to hide memory latency, and on the hardware itself. The sufficiency claim is idealized too, because the rate a machine reaches depends on which bytes are read and in what order. The bounds below survive this, since real inefficiency only pushes a machine further below its ceiling. The cost lands on comparisons between machines. If one machine sustains 85% of its spec bandwidth and another 60%, ceilings computed from spec numbers make the second machine look better than it really is. Read as sustained bandwidth where a measured number exists, and read every comparison in this post as approximate.
A caveat on the metric
One misreading is worth heading off. The product measures the workload-feasibility region, the set of jobs the device can support at an instant. A different question, “how many distinct memory histories can this device produce over a time ”, has a different answer, namely the resident information plus the information streamed over that window,
The feasibility-region reading is the one an inference-throughput bound will need, because serving means keeping sessions resident in memory and streaming data for them.
A first decode bound
The feasibility theorem describes static workloads. Decoding is dynamic, emitting tokens over time. This section turns memory power into a throughput ceiling for batched decoding, and in doing so shows where the product enters a real performance bound.
A toy decoder
Consider the decode phase of an autoregressive transformer, simplified to the memory system alone. Let
let be the batch size (number of concurrent sequences), and let be the number of decode steps per second. Each decode step emits one token per active sequence, so aggregate output throughput is
Throughput is a product of two things, how many sequences run in parallel and how fast the shared model can be swept, and the memory system caps each factor separately.
Capacity limit
The model weights must be resident once, and every active sequence needs its own KV cache, the per-conversation attention state that grows with context length. So the resident state is , and it must fit.
This is the capacity limit, and it sets the maximum parallelism. It is exactly the condition of the feasibility theorem, with .
Bandwidth limit
In a dense transformer, each decode step must apply the model weights. In the memory-bound idealization, applying the weights means streaming roughly of data per step. With bandwidth , the step rate obeys
This is the bandwidth limit, and it sets the maximum step rate. It is the condition, with the per-step traffic playing the role of the flux.
Memory-power decode bound
Multiply the two caps. Throughput is parallelism times step rate, and each is separately bounded, so
Substituting and factoring out exposes the memory-power term.
When the model is much smaller than memory, , the correction vanishes and the bound collapses to the memorable form
This is the memory-power decode bound. The product appears because maximum throughput genuinely factors into maximum parallelism times maximum step rate.
The numerator is the machine. The denominator is the workload, the per-session state times the model sweep size. The bound reads as throughput is memory power divided by memory cost per active model-token.
Scope of the bound
The memory-power decode bound governs batched throughput. Set and it degenerates to
so for a single session only bandwidth matters and capacity is merely a fit constraint. That is the correct behavior, and it makes clear what each metric is for.
Use case The metric that governs it Single-user local chat bandwidth , with capacity as a fit gate Largest model that fits capacity first, then bandwidth Maximum batched decode throughput memory power Memory power is the right scalar precisely for the third row. The next section explains why even that bound is too optimistic.
Missing traffic
The memory-power decode bound assumes the only per-token memory traffic worth counting is the model sweep , shared across the batch. Real decoding also reads each session’s growing KV cache, and that traffic is private, so it does not amortize over the batch. Ignoring it makes the bound promise throughput that long-context serving can never reach. This section introduces the correct per-token accounting and shows the memory-power bound falls out of it as a loose corollary.
Universal resource bound
Step back to the most general statement, which holds regardless of architecture. If each output token costs at least of unavoidable memory traffic and at least of unavoidable compute, and the device delivers at most bytes/s and FLOP/s, then over all setups that fit,
Two rooflines, and the workload lives under the lower of them. Throughout this post I assume decode is memory-bound, which is the usual case for local serving, and keep the memory roofline,
where is the memory traffic per output token. Everything now reduces to estimating honestly. The focus on the memory side is also practical. A hardware catalog can collect capacity and bandwidth consistently across consumer and workstation devices, while comparable sustained-compute numbers are much harder to obtain.
Bytes per token
Split the per-token traffic into the two kinds that behave differently under batching. The model (or active-expert) weights are shared, since one sweep serves the whole batch, so their per-token cost is divided by the batch. The KV/context read is private, since each session reads its own cache, so its per-token cost is not divided at all. With the shared weight traffic per iteration, the tokens emitted per session per iteration (one for ordinary decoding), and the private context traffic per output token at active context length ,
The first term shrinks as the batch grows, because more sessions share each weight sweep. The second term does not move. A larger batch does not make any session’s context cheaper to read, and this asymmetry is the main reason long-context serving behaves differently from short-context serving.
Interactive figure: bytes per output token as the batch and the read context change. Enable JavaScript to explore it.
Memory-power bound as a corollary
Treat as an optimistic lower estimate of the true bytes per token, . Dividing by a smaller denominator gives a larger quotient, so substituting keeps the result an upper bound.
Here the maximization runs over batches that fit in memory, with the resident model footprint, the KV memory stored per session, and the runtime overhead. This is the honest simple bound, bandwidth divided by shared-per-token cost plus private-per-token cost, maximized over fitting batches.
Now recover the previous section’s bound by deliberately throwing information away. Since , dropping it only loosens the denominator.
The capacity constraint caps the batch at , so
This is the memory-power decode bound again. It is what you get by discarding the private context term and using the largest batch that fits. That is why it can sit far above achievable throughput while remaining a true ceiling. The ordering is
The memory-power bound is the orientation line. The KV-aware bound is the one to serve from, and the next section develops it into the operational calculator.
KV-aware bound
This section turns the simple bytes-per-token bound into the model the calculator runs. Three refinements are needed. Context must be split into the part that controls memory and the part that controls speed. The shared weight traffic must be allowed to grow with the batch, which matters for mixture-of-experts (MoE) models, models that route each token through a small subset of their weights. And the batch must be filtered so that we never count concurrency at which every session has become uselessly slow.
Two context lengths
A serving system usually reserves KV space for a long maximum context but reads, on average, a shorter active context. These two lengths drive different parts of the bound, so we keep them separate.
The allocation length controls how much KV memory each session reserves, and therefore how many sessions fit. The read length controls how much context each output token must stream, and therefore per-token cost. Collapsing them into one number either overcharges memory or overcharges speed.
Model quantities
A model contributes five quantities. Two are about fitting, two are about speed, and one is about decoding style.
Symbol Role Full resident footprint (for MoE, all resident weights, including the inactive experts) Shared weight traffic per decode iteration at batch KV/cache memory reserved per session, which controls concurrency Private context traffic per output token, which controls decode cost Tokens emitted per session per iteration ( ordinary, speculative) The split between and mirrors the split between the two context lengths. Allocation controls how many sessions fit, read controls how fast each one decodes. Note that now depends on the batch size , for a reason the adapter section explains.
Memory-fit batch
The first gate is whether sessions fit. Load the model, reserve overhead, and divide the remainder by the per-session allocation.
This is memory-fit concurrency only. It is necessary but not sufficient, and it is exactly the trap that makes a machine look like it can serve a hundred sessions when it cannot serve them usefully.
Interactive figure: how many sessions fit in memory as capacity and reserved context change. Enable JavaScript to explore it.
Aggregate and per-session ceilings
The per-token traffic is the shared weight sweep amortized over the emitted tokens, plus the private context read.
Then the memory roofline gives the aggregate ceiling at batch ,
and dividing by the batch gives the per-session rate,
As grows, the aggregate rises but the per-session falls. That tension is the whole serving tradeoff, and it is why a fit-only bound is not enough.
Usable-batch correction
The fix is to refuse batches at which a session would crawl. Impose a per-session floor , the minimum useful tokens/s/session, and solve for . Replacing the batch-dependent by its shared lower bound keeps a closed form. Because , the substitution only weakens the condition, so the implication runs one way, and the closed form is a necessary condition on the admissible batch rather than a sufficient one.
which defines a rate-limited batch
The usable batch is whichever gate binds first.
Because comes from a necessary condition, is itself an upper bound on the truly admissible batch, and the calculator applies the exact floor test with the true in the next step. This is what stops the “hundred sessions” illusion. As context grows, grows, so falls quickly even while stays large. The KV slots fit while the useful rate does not.
Interactive figure: aggregate and per-session ceilings against batch size, with the memory gate and the per-session floor. Enable JavaScript to explore it.
The bound the calculator uses
Collecting the pieces, define the usable batch set as the fitting batches that also clear the floor,
and take the best aggregate over that set.
This is the KV-aware bound, the main practical formulation. In words, try every batch that fits, reject the ones too slow per session, and for the rest take bandwidth divided by bytes per output token, keeping the best.
The looser memory-power bound is its corollary, obtained as before by dropping the private term and using the largest fitting batch.
The two stand in a fixed relation, which is the main result of the derivation, written first by name and then in full.
The gap across these terms is the point of the whole derivation. The KV-aware line is the tight, practical bound. The memory-power line shows the memory system’s large theoretical capacity-bandwidth product, and the distance between them comes from private context traffic, expert diversity, and the per-session floor. The final term drops the resident-model factor as well, so the right-hand side is exactly the simplified from the memory-power decode bound, now with and . It is the loosest, most optimistic reading, since the resident model and overhead always claim a real share of .
Single session
Set to recover the latency-style bound for one conversation. There is no batch to amortize the weight sweep over.
and for ordinary decoding () this is just . Capacity has dropped out except as the gate that decides whether the model fits at all, consistent with the earlier observation that bandwidth governs single-session speed.
Speculative decoding
Speculative decoding lets . A draft model proposes several tokens and the target verifies them in one iteration, so is the expected number of accepted tokens per session per verification step, bounded by the draft length as . The temptation is to multiply throughput by and stop. That is wrong, because the draft model and verification are not free. Their traffic belongs in or in the per-token term. The safe rule is to never scale by without charging the draft cost in the denominator. With both effects included, speculative decoding moves through the same KV-aware formula unchanged.
The two bounds side by side
The gap between the memory-power bound and the KV-aware bound is easiest to see as memory traffic. Below, two copies of the same machine decode side by side. Each board is the machine’s usable memory, with the weights packed into an orange container of equal-sized cells and each session’s blue KV cells packed into a small container of its own.
Each decode iteration must move every byte that its accounting charges, at the same bandwidth on both machines, so the charged cells light up one by one and the board resets when the iteration completes. The left board charges only the shared weight cells, so it resets quickly and its token counter races ahead. The right board also charges the read cells of every session’s context, so its iterations stretch as the batch and the context grow. A real iteration takes milliseconds, so time runs in slow motion here.
Interactive animation: memory-power accounting and KV-aware accounting decoding side by side on the same machine. Enable JavaScript to watch it.
Both boards run on the same silicon at the same bandwidth, and only the bookkeeping differs between them. The left counter is the memory-power accounting at the chosen batch, and the right one is what the KV-aware bound admits once private context reads are charged.
The sliders show the two context lengths at work. The reserved context sets how many cells each session’s container holds and can push the machine past its capacity, so raising it eventually makes the containers stop fitting. The read context sets how many of those cells light up every iteration, and the longer it gets the smaller the weights’ share of each iteration becomes. It follows the reservation at an adjustable fraction, 90 percent by default, with the unread rest capped at 32k, and the sliders for all of this sit under Advanced. Growing the model itself slows both boards down in step, while the orange container eats the room the blue ones need.
The full memory-power bound goes one step further than the left board. It grows the batch until memory is completely full of KV cells, which is exactly what the default maximize batch mode does, and the line under the left board reports that number. Shrinking the reserved context makes it explode.
At a 4k reservation about a hundred sessions fit and the bound climbs past 4,000 tok/s on this toy machine, and at a 1k reservation it would pass 17,000. Those numbers are true ceilings and useless forecasts at the same time. What stops a real machine long before then is reading each session’s context, which is exactly the traffic the right board charges.
Model adapters
The KV-aware bound is architecture-agnostic, and an architecture enters only through the five quantities. So each model family is captured by a small adapter that supplies them.
Three adapters cover the catalog. They handle dense transformers, mixture-of-experts, and hybrid/sliding/recurrent attention.
Dense transformers
For a dense model with parameters at bytes each, all weights are touched every step, so the resident footprint and the per-step sweep coincide.
With layers, key/value heads, head dimension , and KV byte widths and , full-context attention reserves and reads
where the factor counts keys and values. Weight precision and KV precision are independent settings. NVFP4 weights (NVIDIA’s 4-bit floating-point format) do not imply an NVFP4 cache, so and are tracked separately.
Mixture-of-experts
An MoE model is where the constant- assumption breaks, and fixing it is the single most important adapter correction. Let be total parameters, the active parameters per token, the number of routed experts, and the experts selected per token. Assuming uniformly sized routed experts, each routed expert holds
and the always-on remainder (dense trunk, shared experts, embeddings, attention) is
The naive model assumes a batch touches the same active experts every session, keeping constant. That is false. Independent sessions route to different experts, so a larger batch touches more distinct experts. With token-routings, each independently missing a given expert with probability , the expected number of distinct experts touched is
and the per-iteration shared traffic is the fixed part plus the touched experts.
At this reduces to the active-parameter footprint, and as it saturates at all experts. This rising is why MoE batching does not amortize for free, and why the MoE rows in the worked table reach their throughput optimum at modest batch sizes.
One caveat applies here. Every other traffic term in the bound is a deliberate under-estimate of real traffic, which is what makes a true ceiling. The expert count is different. It is an expectation under independent, uniform routing rather than a lower bound. Real routing is correlated, since load-balancing losses push toward uniform while hot experts and topically similar sessions pull the other way, and correlated routing touches fewer distinct experts than the formula predicts. In that case the modeled traffic overstates the actual traffic, and the computed ceiling can sit below the true one. When a guaranteed ceiling is required, replace by its minimum , which replaces by . The expectation form is the better estimate, the floor form is the safe bound.
Hybrid, sliding, and recurrent attention
Models with local or sliding-window attention, compressed or latent attention, or linear/recurrent state must not use the full-KV formula blindly, because their cache does not grow linearly in everywhere. Split both KV terms into global, local, and fixed-state parts.
A simple read approximation with sliding-window width is
Full-attention layers pay for the whole context, sliding-window layers pay only up to the window, and recurrent or latent state adds a fixed or slowly growing term. The same shape covers Gemma-style local/global attention and DeepSeek-style compressed/sparse attention, with only the coefficients changing.
Calculator procedure
The bound is now ready to compute. Because the same computation runs for every hardware-and-model pair, it is worth stating once as a procedure.
The inputs are a hardware row , a model adapter , and workload assumptions .
- Compute the resident margin . If it is negative, the model does not fit, so stop.
- Compute and the memory-fit batch .
- For each integer batch , compute and .
- Compute the aggregate ceiling and the per-session ceiling at each batch.
- Keep the batches whose per-session ceiling is at least .
- Among the kept batches, choose the one with the largest aggregate ceiling, and report it as the KV-aware result with its batch as .
- Separately compute the memory-power ceiling for orientation.
The output is a stack of gates, and the right phrasing depends on which gate bound.
State Meaning Resident fit The model plus overhead fits in memory Session fit At least one reserved-context session fits Floor fit Some fitting batch clears No floor Sessions fit, but no batch clears The common invalid reading is that fitting in memory implies serving usefully. A model can pass resident fit and session fit and still have an empty usable batch set, because every fitting batch is below the floor. The honest report for that case is “fits, but no batch satisfies the floor”, a distinct verdict from a true fit failure. Keeping the two apart is the reason the floor gate exists.
Worked examples
Now check the theory against real hardware. Consider two 128 GB machines, one bandwidth-rich and one bandwidth-poor, which isolate the effect of at fixed .
Two machines
NVIDIA’s DGX Spark, a small desktop AI machine, carries 128 GB of LPDDR5x unified memory at 273 GB/s. An Apple M5 Max with a 40-core GPU reaches 614 GB/s and is configurable to 128 GB of unified memory. At equal capacity their memory powers are
Hardware DGX Spark 128 GB 273 GB/s 34,944 Apple M5 Max 128GB 128 GB 614 GB/s 78,592 Both bandwidth numbers are catalog figures rather than measured sustained rates, so the earlier caveat applies. If one machine sustains a larger share of its spec than the other, the comparison will make the other machine look better than it really is.
Three models
Three MoE models, modeled from their published cards as adapter parameters, without re-measurement.
- Qwen3.6-35B-A3B, with 35B total / 3B active parameters, routed experts, routed (plus one shared) per token, and weights quantized NVFP4.
- Gemma 4 26B-A4B-it, with 26B total / 4B active, , top-8 routing, hybrid local/global attention, and NVFP4 weights.
- DeepSeek V4 Flash (DS4), with 284B total / 13B active, routed plus one shared, per token, million-token context via compressed/sparse attention, and weights at a Q2-style mixed quantization.
All rows use the Local Frontier defaults, namely reserved context , active context , per-session floor tok/s/session, ordinary decoding , runtime overhead GB, and the memory roofline only. The numbers are memory-side upper bounds from the simplified adapters, to be read as ceilings for comparing hardware.
Results
Hardware Model Single-session KV-aware aggregate Memory-power ceiling DGX Spark Qwen3.6-35B-A3B 149 tok/s 17 345 tok/s 18.2k tok/s DGX Spark Gemma 4 26B-A4B-it 120 tok/s 16 333 tok/s 23.7k tok/s DGX Spark DeepSeek V4 Flash (Q2) 83 tok/s 7 154 tok/s 13.1k tok/s Apple M5 Max 128GB Qwen3.6-35B-A3B 336 tok/s 50 1,006 tok/s 41.0k tok/s Apple M5 Max 128GB Gemma 4 26B-A4B-it 271 tok/s 66 1,326 tok/s 53.3k tok/s Apple M5 Max 128GB DeepSeek V4 Flash (Q2) 188 tok/s 22 446 tok/s 29.5k tok/s Two things stand out. First, with capacity held equal, the higher M5 Max bandwidth lifts the single-session ceilings in proportion to , and the batched ceilings by even more, because the extra bandwidth also lets more sessions clear the per-session floor. The bandwidth-rich machine wins exactly where the theory says it should, in batched throughput. Second, the memory-power column sits one to two orders of magnitude above the KV-aware column. That gap is the cost of private context traffic and expert diversity, and showing it is the point of the derivation.
Forced concurrency
What if concurrency is fixed by policy rather than chosen at the floor-satisfying optimum? On DGX Spark, pushing past buys aggregate throughput at the cost of per-session rate.
Model Batch Aggregate ceiling Per-session ceiling Qwen3.6-35B-A3B 32 394 tok/s 12.3 tok/s/session Qwen3.6-35B-A3B 64 478 tok/s 7.5 tok/s/session Gemma 4 26B-A4B-it 32 430 tok/s 13.4 tok/s/session Gemma 4 26B-A4B-it 64 575 tok/s 9.0 tok/s/session This is the serving tradeoff in numbers. For DGX Spark under these assumptions, 32 and 64 sessions are too high if the goal is around 20 tok/s/session, exactly the regime the usable-batch correction is built to reject, and the reason for these models settles near 16.
A sanity check against a real run
A reported DGX Spark run served Gemma at concurrency 16 at roughly 16 to 18 tok/s/session, an aggregate of to tok/s. The KV-aware aggregate ceiling for Gemma at this batch is tok/s, so observed throughput is
of the simplified ceiling. That is close enough to suggest the implementation is near the memory-side roofline. It does not prove the quantization is optimal. The bound omits compute, scheduler behavior, kernel details, and exact cache traffic, and proving optimality would require profiler evidence of bandwidth saturation with no compute, scheduler, or CPU stalls. A bound this close simply means there is little memory headroom left to capture.
Omitted rooflines
The memory roofline is one limit among several. Real throughput is the minimum over all of them,
and the memory term we computed can be undercut by compute throughput and tensor-core utilization, dequantization kernels, attention kernels and KV layout, prefill/decode phase mixing, scheduler overhead and request churn, CPU and PCIe involvement, multi-GPU communication, allocator fragmentation, thermal and power limits, tokenization and sampling, speculative rejection rates, and prefix-cache hit rates. Each belongs as its own limit term. The memory model remains useful because it makes the first unavoidable ceiling explicit and cheap to compute, and because for memory-bound decode it is usually the binding one.
One recurring caution applies to models with recurrent or linear state. A model with tiny fixed state and tiny private read traffic produces an enormous memory-side aggregate at high concurrency, because almost nothing in the denominator grows with the batch. That is precisely the signal that compute, kernel, scheduler, and recurrent-state details must be added before the aggregate number is treated as realistic. The memory bound describes the best case the hardware allows, and reaching it is the implementation’s job.
Cheat sheet
This section collects the whole formulation in one place, so it can be read on its own. A machine is three numbers and a model adapter is five, with the workload adding three assumptions.
Symbol Meaning , , Usable memory capacity, sustained memory bandwidth, runtime overhead Full resident weight footprint, which must fit in memory Shared weight traffic per iteration, equal to for dense models and growing with for MoE KV memory reserved per session Private context traffic per output token Tokens emitted per session per iteration, one for ordinary decoding , Reserved and average read context, Minimum useful tokens/s per session Everything descends from the memory roofline. If each output token must move at least bytes and the machine delivers at most bytes per second, then
The first gate is whether sessions fit. Load the weights, reserve the overhead, and divide what is left by the per-session KV allocation.
Per-token traffic is the shared weight sweep amortized over the batch plus the private context read, which no batch size amortizes.
The roofline gives the aggregate ceiling at batch , and dividing by the batch gives the per-session rate. The aggregate rises with while the per-session rate falls.
Imposing the floor rejects the batches where every session crawls, and the usable batch is whichever gate binds first.
The usable batch set holds the batches that fit and clear the floor, and the KV-aware bound is the best aggregate over it.
Setting in the same formula gives the single-session ceiling. Dropping the private context term and taking the largest fitting batch gives the looser memory-power ceiling,
and the three levels always order the same way.
Every number these formulas produce is an upper bound built from memory capacity and bandwidth alone. Real implementations land below it, and compute, software overhead, and interconnects can only lower the ceiling further.
When reporting a result, always state the assumptions that move it, namely , , , , the weight precision, and the KV-cache precision or attention adapter. Without them, a single tok/s number is not reproducible.
To see these bounds computed live for hundreds of audited model profiles against a catalog of local hardware, try the Local Frontier calculator.
-
I've started using Cursor since a few days now, and I have to say the experience is really pleasant. I had not touched it since Claude Code came out in May 2025, more than 1 year ago. I had even deleted it fully last year as an editor and replaced it with Zed, after it had become very bloated and unstable I can say it no longer feels bloated/unstable and that they have transitioned successfully to the agentic era Using it mostly for fable. Using it locally in the desktop app, and also through acpx, to make codex ask fable for review Thank you @cursor_ai for sponsoring my Ultra plan!
-
Building an AI de-smeller
Note: this post is fully AI generated, written by Claude Fable 5 through Cursor. It was written interactively, in a back and forth with an agent, under the very kill-ai-smell skill it describes, as a demonstration of that skill.
Everyone knows the feeling by now. You open a page, read two paragraphs, and something tells you a model wrote it. The tells have become cultural shorthand, with the em dash as the poster child, but most of the discourse stays at the level of vibes. I wanted to know whether the feeling corresponds to anything you can measure, so my agent and I ran a small stylometric study, and the answer turned out to be a clear yes. A handful of surface metrics, all computable with regular expressions and a sentence splitter, separate generated copy from human writing by an order of magnitude, in several cases with no overlap between the groups at all.
This post walks through the corpus, the metrics, and the numbers, and ends with the kill-ai-smell skill that came out of the exercise.
The corpus
For the AI side I needed pages that read as generated in the wild, and I had convenient specimens close to home. Ten project sites from the OpenClaw ecosystem (crabbox.sh, mcporter.sh, gitcrawl.sh, clawpatch.ai, fs-safe.io, spogo.sh, imsg.sh, wacli.sh, gogcli.sh and goplaces.sh) have landing copy written largely by agents, and I decided to keep those pages as they are and use them as data. Their prose comes to 4,853 words after stripping code blocks. These pages were written by GPT 5.5, so the measurements characterize that model’s copy. They do not necessarily generalize to other models, whether Claude or open-weight ones like GLM and Kimi.
For the human side I wanted texts that are provably human, which means they had to be frozen before language models could have touched them. Five are essays and documentation: the SQLite testing documentation, Joel Spolsky’s 2000 essay “Things You Should Never Do”, a 2018 antirez blog post, Paul Graham’s 2009 “Maker’s Schedule, Manager’s Schedule”, and Julia Evans’ 2019 “Get your work recognized: write a brag document”. The other three attack the register objection directly, because landing copy and essays are different animals regardless of author. They are the ripgrep README at its 2016 tag, the Redis README at 3.2.0 from the same year, and the Requests README at v2.13.0 from 2017, each taken at an old git tag whose commit history proves its date. A README that sells a tool is the fairest comparison for a landing page that sells a tool. The human set comes to 15,317 words, and every rate below is normalized per 1,000 words so the corpora are comparable.
The exact texts I measured are archived in the ai-smell repository and listed in the appendix, so anyone can rerun the numbers against the same input.
The metrics
The measuring script strips code, splits sentences, and counts things. There is no model in the loop and no judgment call in any metric. That is the point of the exercise. If the tells are real, they should be detectable by grep, and anyone should be able to reproduce the numbers. The scripts, the corpus, and the figures live in the ai-smell repository.
The chart below shows every document against every metric, with the AI pages in orange and the human baselines in blue. The prose after it sticks to the ratios, because the ratios are the story, and the raw ranges are collapsed underneath for anyone who wants to check them.

Raw ranges per metric
Metric AI set (10 docs) Human set (8 docs) Em dashes /1k words 0.0–61.3 0.0–4.7 Exactly-three lists /1k words 6.3–15.9 0.0–2.0 Labeled bullets, % of all bullets 53–100% 0–11% Fragment sentences (≤4 words) 3.6–41.9% 1.4–17.4% First person /1k words 0.0–2.1 0.0–50.9 Type-token ratio (first 280 words) 0.59–0.69 0.53–0.67 MTLD lexical diversity 112–229 66–146 Mean Zipf word frequency 4.86–5.30 5.28–5.99 Sentence flow (mean run percentile) 0.19–0.41 0.49–0.73 The em-dash gap is the famous one, and it is real but weaker than its reputation. Averaged over each corpus, the AI pages use em dashes at roughly eighteen times the human rate, and the heaviest page lands one every sixteen words. But the tell only works in one direction. Three of the ten AI pages use fewer em dashes than the 2016 ripgrep README, and one uses none at all. A page drowning in dashes is almost certainly generated. A page without them proves nothing.
Exactly-three lists (“A, B, and C”) turn out to be the better punctuation-level tell. Every AI page produces them at least three times the rate of every human text, with no overlap anywhere. Even the most triad-prone human text, Joel’s essay, sits at a third of the most restrained AI page. Averaged over the corpora the gap is about nineteen-fold, and unlike the em dash, no AI page escapes it.
The labeled bullet was the discovery of the study for me. It is the bullet that opens with a short label, then a period, colon, or dash, then one sentence of elaboration. Here is a real one from mcporter.sh:
Typed clients. mcporter emit-ts emits
.d.tsinterfaces or a ready-to-run client wrappingcreateServerProxy()so agents call MCP tools with full TypeScript types.The metric is the share of a document’s bullets that follow this shape. On the AI pages it is roughly four of every five, and on one page every single bullet does it. In the human baselines the share never reaches one in eight, and five of the eight human texts never use the shape at all; their bullets are plain items, like file names or flags, without the label-and-elaboration mold. If you have seen an AI-written landing page, you have seen walls of these, and it turns out the wall is more diagnostic than the punctuation.
Fragment sentences, the verbless punches of four words or fewer, sit in between. Most AI pages run high, and the worst writes two of every five sentences that way, but the groups overlap. The deliberately punchy Requests README out-fragments three of the AI pages. Fragments corroborate rather than convict.
First person taught me the opposite lesson. It looked like a strong tell until the corpus got fairer. Against essays the gap is enormous, since the antirez post averages more than one first-person word per sentence and the ten AI pages together contain exactly one. But the pre-LLM READMEs behave like the AI pages here. The Requests README has no first person at all, and ripgrep and Redis barely any. Authorial voice turns out to track register rather than authorship, so it works as a confirming signal at best. Vocabulary variety weakened the same way. Generated copy rotates in a fresh synonym at every mention, which pushes its lexical diversity high, and the AI pages do cluster at the top of the range. But the Requests README, which is deliberately punchy marketing prose, scores right among them, so the metric separates registers more than it separates authors. The human tendency it gestures at is still real, though. Human writers reuse the established word for a thing and repeat phrases for emphasis. Joel opens three consecutive paragraphs with “You are throwing away”, and a model would never.
The vocabulary story does not end there, because the type-token ratio was the wrong instrument. We remeasured word choice with two better ones. MTLD scores lexical diversity in a way that does not depend on document length, and the wordfreq package places every word on the Zipf frequency scale, where “the” scores about 7.7 and anything under 3.0 sits outside roughly the 30,000 commonest English words.
Both separate the groups where the TTR could not. All ten AI pages score above 111 on MTLD while seven of the eight human texts stay under 106, with the Requests README as the lone crossover once again. Mean word frequency is nearly as sharp from the other side. Every AI page averages Zipf 5.30 or below and every human text 5.28 or above, so the two ranges overlap only in a sliver 0.02 wide, where the ripgrep README brushes past the plainest-worded AI page. Neither axis classifies alone, since ripgrep crosses the frequency boundary and Requests crosses the diversity one, but each README fails only one test. Draw both thresholds, at Zipf 5.35 and MTLD 100, and every AI page sits in the rare-and-rotating corner while no human text enters it. The structural detector coming up needs only one of its two lines; this pair needs both, and both suffice. The reason is not exotic vocabulary. The rare words on both sides are ordinary jargon, “OAuth” and “stdout” against “Valgrind” and “malloc”. What differs is the connective tissue. Nearly half the words in the human texts are the commonest ones in English, the “the” and “of” that full sentences run on, while on the AI pages that share drops below three in ten, because telegraphic noun piles need no articles. So the rarity metric measures, from a third angle, the same thing the fragments and the labeled bullets measure, which is that generated landing copy does not write whole sentences.

Flesch-Kincaid grade, the standard readability score, misses all of it. The AI pages come out as easier reading than the human baselines because their sentences are short, and the formula never looks at what fills them. This post sits on the human side of both word-choice axes, as the green diamond in the chart shows.
Structural tells
Beyond the counters, we tested two structural claims, and both held on the larger corpus.
The first is identity deferral, which I wrote about in Good READMEs say what tools are. Generated copy describes what a tool does and dodges saying what it is. In sentences where the tool name is the grammatical subject, action claims outnumber identity claims five to one across the ten pages. The raw ratio alone proves little, since prose about a known subject is naturally verb-led. The positional version is the tell. All three pre-LLM READMEs establish identity in their opening lines: “ripgrep is a line oriented search tool”, “Requests is the only Non-GMO HTTP library for Python”, and Redis opens its first section with the literal heading “What is Redis?”. Among the ten AI pages, exactly one does the same. Four open with headless fragments like “A local-first GitHub triage tool for maintainers and agents.”, which name a category but carry no subject and no verb, and the remaining five open with benefit imperatives or setup instructions like “Keep your editor and git workflow.”
The second is heading register, and it produced a fun inversion. Title Case, the thing style guides nag about, belongs to the humans here. The SQLite docs use it in a fifth of their headings, as was the convention of their era, while the AI pages write modern sentence case throughout. What convicts the AI headings is rhetoric. About a third of the AI headings are slogans, imperatives, or rhetorical frames rather than labels; in the human set the share is one in ten, and those are mostly mild FAQ-style questions like “Why should I use ripgrep?”. The strongest single shape is what I now call the comma couplet, a parallel two-beat slogan like “Local loop, remote box”, “Two jobs, one binary” or “Small surface, clear split”. It appears eleven times across five of the ten sites. The human set produces it exactly once, and the exception is instructive. It is the title “Maker’s Schedule, Manager’s Schedule”, a deliberate one-off rather than a house pattern stamped down a page.
There is also a tell that only becomes visible when you put the pages side by side. Six of the ten sites have a “Pick your path” section, seven make a “five minutes” time-to-value promise, eight have a “Status” section, and six close with the exact sentence “Released under the MIT license.” Each page looks fine alone. Together they reveal one prompt’s house style stamped across unrelated projects.
A minimal detector
The expanded corpus simplified the detector, because the two structural metrics turned out to need no help. Flag a page as AI-flavored when exactly-three lists exceed 3 per 1,000 words or the labeled-bullet share exceeds 30%. Either rule alone classifies all eighteen documents correctly. The em dash dropped out of the detector. It convicts a page when present in bulk, but three of the ten AI pages use fewer em dashes than the 2016 ripgrep README, so its absence clears nothing.
Plotting the two structural metrics against each other shows how much margin the thresholds have. Every human text sits in the bottom-left corner, below both lines, and every AI page sits far outside both.

Eighteen documents make a demonstration rather than a validated classifier. The first version of this study used only essays and documentation as baselines, which left the objection that the metrics were separating registers rather than authors, so the corpus now includes three pre-LLM READMEs that sell tools the way the AI pages do. The structural gaps survived that control untouched, while two metrics that looked strong against essays alone, first person and lexical diversity, collapsed into register signals. That is the argument for keeping the baselines adversarial. The next escalation would be a large sample of post-LLM, human-written landing pages, but the sizes of the surviving gaps, three-fold at the closest edge and roughly twenty-fold on average with no overlap, make me confident the structural metrics would hold.
The flow of a sentence
Everything above counts features one at a time. The last metric came out of a different question. Read the two corpora side by side and the sentences feel different in a way none of the counters capture, so I asked whether the rhythm of consecutive sentences could be measured too. I did not know what to count in advance, so we searched for it in the style of karpathy/autoresearch. A frozen harness feeds every document to a candidate scoring function as a bare sequence of per-sentence measurements and reports how cleanly the scores split the ten AI pages from the eight human baselines. The scoring function is the only file that changes between runs, and every attempt lands in a journal that now holds over fifty experiments, most of them failures.
The failures narrowed the answer. Statistics of pure order, which measure how sentence lengths rise and fall while ignoring how large they are, all fell short of separating the groups, so the tell is not in the alternation. What survived is almost embarrassingly simple. Split each sentence at its punctuation marks and keep the longest piece, the longest run of words the sentence lets through without a pause. Human writers keep producing sentences that contain one long run, whatever their register. The AI pages break nearly every sentence before a run can develop.
The first version that separated the corpus scored each sentence on a ramp between a 10-word run and a 15-word run, and it worked, but both constants were picked by hand. Ranking removes them. Give each sentence the fraction of all runs in the corpus that are shorter than its own, and average those percentiles over the document:
where is the longest run in sentence and is the distribution of runs pooled over the whole corpus. Statisticians will recognize the Mann-Whitney rank statistic. The flow score is the probability that a random sentence-run from the document outlasts a random run from the corpus, and it carries no tuned constants at all. We also tried a sliding-window generalization that multiplies the percentiles of consecutive sentences, and it looked stronger until we normalized the scale, at which point the gain vanished. That correction is in the journal too. The order of the sentences adds nothing; the length of the runs carries the whole signal.
The raw material makes the tell visible before any formula does. The chart shows the longest run in each of the first sixty sentences of one human baseline and of crabbox.sh, one of the two AI pages nearest the human range. The human post keeps clearing ten words without a pause. The AI page almost never does.

Averaging the percentiles gives one number per document, and the groups separate completely. The AI pages score between 0.19 and 0.41, the human texts between 0.49 and 0.73, and refitting the threshold with any single document held out still classifies all eighteen. The margin is thinner than the detector’s, since the strongest AI page comes within 17 percent of the flattest human baseline, the ripgrep README. This post scores 0.56, in the middle of the human range.

The reference implementation is analyze_flow.py in the study repository, and the search that produced it, including every dead end, is preserved in the autoresearch directory.
Long-form tweets in the wild
The corpora above have ground truth, which is what makes the thresholds checkable. The place people actually want a detector is the feed, where there is none, so as a last exercise we pointed the same counters at tweets. I keep a personal archive of tweets captured while browsing, about 27,000 at the time of writing, and from it we built one sample per account, made of every original long-form tweet (over 280 characters) in date order, for every account with at least 2,000 words of such text. That produced 42 accounts, my own included, and each sample is archived in the ai-smell repository with a source link per tweet.
The chart puts the 42 samples over three metric pairs, with the ground-truth pages and baselines left in faintly in every panel so the wild samples can be read against the corpus that set the thresholds. The first panel repeats the detector chart exactly, same axes, same limits, same two thresholds. Every panel also carries one more point, a green diamond for this post itself, measured the same way as everything else.

Nothing here is a verdict, since none of these samples has a known author process. Under the unchanged rules of the first panel, seven of the 42 accounts trip the detector. Four cross the triad line, three cross the labeled-bullet line, and none cross both. On the landing pages the tells came bundled, every page far past both thresholds at once, while in the feed each flagged account trips exactly one rule. The bullet share also rests on smaller counts here, since a thread carries far fewer bullets than a landing page, and one of the three flagged accounts crosses the line on just two labeled bullets. So the thresholds transfer, but the confidence does not; a verdict in the feed would need feed-specific baselines.
The other two panels show where the feed does and does not resemble the corpus. On the dash axes, six accounts run past every human baseline, topped by one at 34.5 dashes per 1,000 words, denser than eight of the ten AI pages; but the dash already dropped out of the detector on the ground-truth corpus, and it stays out here. Fragment share spreads the accounts across the whole range the two corpora span, so it separates nothing in the feed either.
The flow metric from the previous section gives an independent read on the same samples. It puts 13 of the 42 accounts below its midpoint threshold, and all three accounts that cross the labeled-bullet line are among them. That agreement is worth pausing on, because the two measurements share nothing. One counts bullet shapes and the other reads clause lengths, yet they flag the same accounts. The two lowest scorers sit below every AI landing page in the corpus, and the usual register caveat applies with extra force here, since the threshold was calibrated on landing pages against long-form prose and a punchy feed style will read as low flow on its own.

The account whose long posts sent me down this path is one of the three past the bullet line. Its sample writes 41 labeled bullets out of 90, a 46% share, half again past a threshold that no pre-LLM baseline came near, while its dash and triad rates sit mid-field. The counters flag it rather than clear it, with the caveat above about register. Its long posts also share a hook template the counters never measure. They open with lines like “90% of AI developers just…”, pivot on “It’s not X. It’s Y.”, and close with “Let me explain.” That is the next metric worth building, and the tweet samples are archived so anyone can beat me to it.
The de-smeller
The practical output of all this is kill-ai-smell, a skill in my tools repo that any coding agent can load. It covers the tells from punctuation up through page structure, and every rule carries a bad example next to a rewrite, because the rewrite teaches the hard half of the lesson. Fixing a smell means restructuring the sentence. Swapping an em dash for a punchy colon changes nothing.
The most instructive moment of the project happened while writing it up. My agent, fresh off measuring contrast rhetoric as a top tell, produced a report whose highlighted callout was titled “The strongest tells are structural, not lexical”. The detector fires on its own author. That lesson is now the second paragraph of the skill. Knowing the rules is no defense, because these patterns are how models write by default, so the sweep has to be mechanical, applied to your own output, and repeated on the text that describes the sweep.
Feel free to steal the skill, and if you run the metrics on a corpus of your own, I would love to see the numbers.
A plea
I realize I am doing slop vendors a favor by putting this out there. The tells are enumerated and scripted now, and anyone who wants their generated copy to pass can point a model at this post and patch the fingerprints. I accept that trade. What I can’t bear is actually legit people using AI to write their long-forms and publishing the model’s house style untouched, and I’d rather have everyone, slop vendors included, stop using patterns like “It’s not X. It’s Y.” and the triads than have to read them ever again.
I also know there is a brain behind those AI-generated posts. Somebody lived the experience worth posting about, formed the opinion, and then let a model flatten it into the same shapes as every other post in the feed. This favor is for them. The de-smeller is there so they can keep using the machine without shipping its defaults.
Appendix: the corpus
Every text is archived as measured in the ai-smell repository, which is the maintained home of the study. It holds the corpus, the analysis scripts, the raw results, and the figures. The AI pages were captured from the live sites in July 2026, with code blocks still in place (the script strips them before counting).
The corpus splits into four groups there:
- corpus/ai holds the ten OpenClaw landing pages.
- corpus/human holds the eight pre-LLM baselines: the SQLite testing docs, essays by Joel Spolsky (2000), antirez (2018), Paul Graham (2009), and Julia Evans (2019), and the ripgrep, Redis, and Requests READMEs at their 2016–2017 git tags.
- corpus/tweets holds the 42 long-form tweet samples, one file per account, date-sorted, with a link back to each tweet.
- corpus/self holds this post itself, archived as measured, provably AI-written by its own disclaimer. Written under the kill-ai-smell skill, it clears the detector from the other side, with zero em dashes, exactly-three lists at a sixth of the threshold, and no labeled bullets. The tells are a default, not a fingerprint, and a model instructed against them stops producing them.
-
Worried that giving your 🦞 @openclaw agent write access to your 🤗 @huggingface account can risk deletion of your datasets/models/spaces/buckets, or cause irreversible damage? 😱😱😱 No need to be! I have created an agent login helper to run in your YOLO mode remote machine, which prevents any risk of irreversible deletion. Just run: uvx hf-auth-helper agent login There is a specific set of scopes you can choose while creating a fine-grained HF token. These include all read scopes + discussion.write, which let's your agent create PRs. Since you are not giving repo.write, your agent cannot force-push your main branch, change repo settings or delete them It is unfortunately not super straightforward to choose those on the web UI. This will hopefully change soon, and this functionality might even be natively in hf cli Until that happens, use hf-auth-helper to login worry free in your remote or local openclaw instance Your agents will be able to create PRs on datasets/models/spaces, which you will then be able to merge on your own browser 2 caveats: 1) This does not solve the data exfiltration attack vector—nothing does. Make sure to exclude any repos which absolutely must remain private while choosing your scopes. See for more info: simonwillison.net/2025/Jun/16/the-lethal-trifec… 2) As buckets are not repos, your agent will not be able to modify a bucket (add/remove data). To help with that, I have another project on the way, a credential broker. Stay tuned, coming soon Source: github.com/osolmaz/hf-auth-helper Demo authentication flow:
-
OpenAI is following the ASPAVA strategy, with gamified subsidies ASPAVA is a type of kebab shop from turkey. These shops usually serve mid quality food But despite that, the majority loves them. That's because they serve free stuff throughout They serve free sides at the beginning. They serve free sides during the main course. They serve free dessert at the end. They serve free tea as many times as you like Some of them give you so much "free" food that you feel like you are stealing. A lot of people frequent these shops not because they like it a lot, but because they are addicted to getting things for free Main dish portions are made smaller in order to breakeven with so many side dishes, which I feel is analogous to what is happening with GPT these days---though I can't prove it NVIDIA is not a car, and OpenAI is not kebab. I don't know if codex resets cost OpenAI much, but if they are, then they might be a waste of resources Developers are the most disloyal customer group. Once the subsidies are gone, they can switch away in the blink of an eye
-
Most people, including professionals, will likely NOT pay more than $10k capex for their home AI workstation, even in the long run (ignoring future inflation) If you stretch it, <= $20k They will also not want to pay more than $200~300/mo opex, on electricity for example Builders who are spending a lot more than that on hardware: keep that in mind, if you are building for the general public dogfood your product with that which everyone will have, not just 0.1%
-
I keep seeing insanely expensive builds giving insanely impressive results These results don't matter What matters is, whether one can: - run a "SOTA level" model, whatever that is - with under 32gb VRAM or unified memory - in 5 parallel sessions - with 50~100 tok/s each - with enough leeway memory for other applications - in a system as cheap as $1000 That is our goalpost That is the threshold when open source AI will win
-
Another annoying GPT-ism (circa June 2026): while describing something, it always describes what it *does*, but never what it *is* > "LocalPerf benchmarks local LLM inference servers and keeps the evidence in one portable run artifact." If I were a philosopher, I would say that "AI lacks ontology". Or that it is "anti-essentialist", believes that things cannot be things in themselves But all models literally have an ontology. They have it since word2vec days, you can plot it out. It's just an annoying tendency in GPT's writing So using philosophy to understand AI might be dumb sometimes If you don't want your README's to sound like slop, then you can steal my write-readme skill: After write-readme: "LocalPerf is a local LLM inference benchmark CLI. It runs benchmark plans against local inference servers and stores the evidence in one portable run artifact." Skill: github.com/osolmaz/tools/blob/main/agents/skill…Image hidden
-
Besides being hot, this take is very correct and points out to a fundamental tradeoff in the storage layer being centralized versus distributed git is distributed and that makes total sense for code which takes small space by its nature. it is cheap for everyone to duplicate it locally. this proved to be very useful over e.g svn, when devs could develop independently from the centralized server AI artifacts, however, are 1 million times bigger than code. in that case, the bottleneck becomes storage and network. decentralization and version control become lower priority. they can be sacrificed the tradeoff tilts towards getting the cheapest possible storage and transfer. because you will need a LOT of that I regret to announce to competitors that Hugging Face has already won this game when they acquired Xet. the tech just works, and the network effects are immense
-
My posts here on X now sync automatically to my blog, giving me full ownership of my content and zero effort SEO For free, no API costs My long-form posts are automatically featured and titled on the front page of solmaz [dot] io. Filtering is done by my claw running a sync-x skill daily, which then notifies me on Discord How do I scrape the posts? ALL the posts I view (including the ones I post) are saved locally using @kubmi's xTap and then synced to a private repo using my extension on it xtap-sync My claw has access to that private repo and can run programmatic tasks like sync-x, summarize what happened that day, notify me about any topics I wantImage hiddenImage hiddenImage hidden
-
New blog post: Using local models for agentic zero-shot classification, in real-time, high frequency triage If you have a 128gb of memory for models (a DGX spark like I do for example), you can create a real time classifier and notifier for yourself that can classify more than >20 items per minute, using mid-sized @googlegemma and @Alibaba_Qwen models, with over 200-300 output tok/s aggregate throughput Like processing new tweets on twitter, issues/prs on github, messages on telegram and discord, in real-time Over the past few weeks, I have built one for myself, to filter and get notified about local model related issues on the OpenClaw repo I initially thought gemma-4-e4b would give me the best tradeoff I was wrong. I learned that if one has enough memory already, one should not bother with <10b models like gemma4 e4b or e2b. Precision and recall were much higher zero-shot with gemma-4-26b-a4b, whereas the smaller e4b needed significant prompt optimization to eventually not perform nearly as good To provide more context to the model, I created a restricted bash-like shell, called reposhell. In that shell, it can run read-only commands to ls/find/grep/cat openclaw source code, but only that. When the PR description/diffs are not clear enough as to categorize it, the agent reads the code to figure it out Because small models can get prompt injected, and I need to make sure that someone can't harm my setup by creating a malicious issue or PR in the openclaw repo I found that for specific systems like this, it is very convenient to extend and bundle Pi. You can create agentic CLI tools that work fully locally and for free, and keep that separate from your main pi coding setup. localpager-agent has its own session dir and tools, and I ensure that it will run local models in a secure way by isolating it from my main pi setup Once localpager-agent categorizes a PR/issue as local_models and related labels, I automatically receive it as a notification on Discord The whole implementation is fully open source and MIT licensed, alongside the dataset we used to benchmark the performance I believe zero-shot agentic classification running on local hardware will find many use cases across a wide variety of business applications, like news gathering, open source software development, customer support, content moderation, sales and so on Agents increase the amount of information produced in a lot of systems, and hence we will need to set up cheap ways to wrangle all that information In times where governments can cut off access to SOTA models on a whim, it is more important than ever to build your business on open models and if possible, run them on your own hardware! Big thanks to @evalstate and @ben_burtenshaw for their valuable feedback, especially with helping me evaluate this more rigorously! One take-away is that categorizing contributions in an open source repo is a *hard* problem, and that it is not trivial to reliably create a golden dataset with LLMs, for evaluation purposes Read more here: huggingface.co/blog/local-models-pr-triage
-
gpt5.5 and most other models are very bad at one-shotting nice data models gpt5.5 also has this annoying property that once it decides for a schema (or any design), it's very hard to trigger thinking again. and if you ask to "rewrite from scratch", it will write create something even more ridiculous To solve this problem, I have built a meta-harness over codex just for simplifying slop data models called schemator (work in progress) Basic idea: it mimics what I myself do while I am designing a schema: scrutinize and question each field one by one It starts a fresh codex session for each field with a fixed prompt like "Try to come up with the most Lindy data model" + a prompt for side notes It does that with a fresh context for each field, so that they are independent from each other. At the end of a review run over a field, the reviewer can propose to keep, rename or remove the field When all fields are reviewed once, that makes one iteration. Then this is looped over until the review results stabilize, and do not propose any further changes I get better results by just asking my agent to "use schemator on this" after it creates a JSON schema or SQL table Give it a try if you have codex! It has a skill, so should be easy for an agent to figure out how to use github.com/osolmaz/schematorImage hiddenImage hidden
-
For my recent LLM leaderboard osolmaz-leaderboard.hf.space, I sum up all time total downloads (or likes) across model variants, and then divide it by the age of that model. I.e. "time decay" for popularity This gives a more time-agnostic metric for the popularity of that model. In an ideal ranking, older models that are not popular anymore should be demoted, like 2 year old Llama 3 models. If you don't do that, they might still occupy top 10 needlessly, despite having been replaced by e.g. qwen in practice Thanks to that, qwen-3-6b which came up 1 year ago and has 150m downloads can surpass llama-3-1-8b which came up 2 years ago and has 200m downloads More notes on my post: solmaz.io/popularity-rankingImage hidden
-
if you take the Most Downloaded Models of All Time, Llama 3.1 makes it to Top 10 with around 200 million total downloads (ranking is done w.r. to time-averaged downloads) RIP Llama, you walked so @googlegemma and @Alibaba_Qwen can run Also a reminder that if you build your branding on top of open weight models developed by big corps, you might eventually be the de facto owner of that brand if they pull the plug on it. Like llama.cpp @ggml_org Huge fumble by MetaImage hidden
-
Popularity ranking cheatsheet
I recently did some work ranking models on Hugging Face. While doing that, I remembered some concepts I had known years ago from studying recommender systems. But I couldn’t find any personal notes from that time.
So I’m leaving this cheatsheet for my future self, if I ever need it again.
The main idea with popularity metrics is that it is proportional to e.g. total likes/views, and inversely proportional to the time passed to accumulate those likes/views. A lot of different platforms came up with many different ways to calculate this. And while you can model this in a certain way that maximizes some imaginary objective, what ends up being implemented first is the cheapest/most efficient algorithm.
Below are some examples, generated by GPT 5.5 xhigh.
<slop>The abstract problem is:
A platform has many items and a limited front page. It needs to decide what deserves visibility now. That is usually not the same as “best,” “most useful,” or “most popular all time.”
A clean taxonomy:
Here means attention: views, downloads, likes, votes, streams, sales, stars, comments, clicks, etc.
Raw popularity
This is the simplest ranking.
Use it when you want “biggest ever.”
Examples: most downloaded, most viewed, most sold, most starred.
Problem: old items dominate because they had more time.
Velocity
This measures speed of attention.
where is age.
Use it when you want “how fast is this spreading?”
A stricter version:
If , this is close to attention per unit time. If , old items are penalized more gently. If , new items are favored aggressively.
This family is close to what Hacker News describes at a high level: HN says its basic ranking divides points by a power of time since submission, while also applying other factors such as flags, anti-abuse systems, demotions, account/site weighting, and moderator action.1
Log-scaled velocity
Raw attention often follows a power law: a few items get enormous numbers. So platforms often compress the signal.
This keeps huge items ahead, but prevents them from crushing everything else.
This is usually a better “hotness” formula than plain:
because it rewards scale without making scale the only thing that matters.
Recent-window popularity
Instead of lifetime attention, count only a recent window.
where is recent attention.
Or normalize by window size:
where is the time window.
Examples:
Spotify’s daily and weekly charts are this kind of family, though Spotify also says it uses chart-eligible streams and filtering formulas to protect chart integrity; it does not simply expose raw app stream counts as chart counts.2
Momentum
Momentum compares the current period with the previous period.
where is previous-period attention.
Example:
This finds things that are accelerating.
Problem: small items can look extreme. Going from 1 to 20 is a jump, but it may still be tiny in absolute terms.
A safer version mixes ratio and volume:
Trend detection
Trending is not just “popular.” It usually means “unusually active relative to expectation.”
where is expected attention.
If something normally gets 100 views/day and now gets 10,000, it is trending. If something normally gets 10 million views/day and now gets 10.5 million, it is popular but not necessarily trending.
Another version:
The ratio version favors surprise. The difference version favors large absolute surges.
Google Trends is a useful example of normalization: it divides search interest by total searches for the relevant geography and time range, then scales results from 0 to 100, so large regions do not automatically dominate raw volume rankings.3
Hotness
Hotness combines attention and freshness.
A simple hotness score:
Popularity pushes up. Age pulls down.
Another common form:
This says: “large attention matters, but old attention decays.”
Classic Reddit-style hotness
The old open-source Reddit code had a “hot” formula based on vote balance, logarithmic scaling, and time. In simplified notation:
where is upvotes, is downvotes, and is time since a reference epoch. This is specifically the archived open-source Reddit implementation, not a guarantee of current Reddit production ranking.4
The important idea: votes matter logarithmically, and time strongly affects ordering. This makes the ranking feel alive.
Time-decayed attention
Instead of using age directly, you can make every attention event fade over time.
where each attention event contributes less as it gets older.
Plain language: a view today counts more than a view last month.
This is good when you have event-level data.
A simpler approximate version:
where .
Example:
Steam’s real-time Top Sellers use this general idea in a revenue context: Steam says it rolls up player spending from the trailing 24 hours and gives extra weight to spending in the last 3 hours, across base game purchases, DLC, and in-game transactions.5
Quality-adjusted popularity
Sometimes attention alone rewards clickbait. So platforms mix attention with satisfaction.
where is a quality signal.
Examples of :
YouTube Charts disclose this kind of multi-signal logic: they consider view count, how quickly views are growing, where views come from, topic, age, and performance compared with recent uploads from the same channel; YouTube explicitly says the highest-view-count video is not necessarily ranked first.6
Confidence-adjusted ranking
This prevents tiny samples from winning too easily.
Bad ranking:
This lets an item with 2 perfect ratings beat an item with 10,000 very good ratings.
A Bayesian shrinkage version:
where is sample size, is the item’s observed quality, is the global average, and controls how much evidence you need before trusting the item.
Plain language: with little data, pull the score toward the average.
IMDb is an example of this family in spirit: IMDb says it publishes weighted vote averages rather than raw averages, that not all votes have the same impact, and that it does not disclose the exact method.7
Wilson score ranking
For up/down votes, a common confidence-based formula is the Wilson lower bound.
Let:
where is positive votes and is total votes.
Then:
This estimates a conservative lower bound for true positive rate.
Use it when you want “best-rated with enough evidence,” not merely “highest average rating.”
Evan Miller’s “How Not To Sort By Average Rating” popularized this for web rankings, and the archived Reddit code includes a confidence sort using the Wilson method; Stack Overflow also discussed the same family of sorting methods for comments/answers.8
Category-normalized popularity
Raw popularity is unfair across categories.
where is average attention in that category.
Example: a niche item with 10,000 downloads may be huge in its category, while a general consumer app with 10,000 downloads may be irrelevant.
A velocity version:
Use this for “popular relative to peers.”
Spotify’s Local Pulse is a real-world example of relative popularity: Spotify says Local Pulse shows songs uniquely popular in a city relative to their overall popularity.2
Composite ranking
Most mature platforms do not use one pure formula. They combine signals.
where are weights.
Then platforms add penalties:
Product Hunt is explicit that its homepage leaderboard changes based on upvotes, comments, time since submission, and other factors, while withholding exact details to reduce gaming.9
Amazon’s book sales ranking is also a composite/decayed-relative system: Amazon says rankings reflect recent and historical activity, recent activity is weighted more heavily, ranks are relative to other books, and rank can change even if the item’s own activity stays constant.10
Examples out in the wild
Platform Ranking type Disclosed logic Reddit Hot, classic open-source version Hotness Vote balance, log scaling, and time term.4 Hacker News Hotness / age decay Points divided by a power of time, plus flags, anti-abuse, demotions, weighting, moderator action.1 Product Hunt Launch hotness Upvotes, comments, time since submission, and undisclosed anti-gaming factors.9 YouTube Charts Trending / hotness View count, growth speed, traffic source, topic, video age, channel-relative performance, safety filters.6 GitHub Trending Developer attention The public page exposes total stars/forks and “stars today”; GitHub does not publish a full ranking formula there.11 Google Trends Normalized search interest Search interest divided by total searches for that time/place, scaled 0–100.3 Spotify Charts Stream popularity with filtering Chart-eligible streams; local charts; Local Pulse is city popularity relative to overall popularity.2 Steam Top Sellers Revenue hotness Trailing 24h revenue, with extra weight on last 3h; includes DLC and in-game transactions.5 Amazon Best Sellers Rank Decayed relative sales/activity Recent and historical activity, recent activity weighted more heavily, rank relative to peers.10 IMDb ratings Weighted reputation Weighted vote averages, not raw averages; exact method undisclosed.7
The design choices
Every attention-ranking system chooses answers to these questions:
Choice Meaning What counts as attention? Views, downloads, stars, likes, votes, sales, comments, plays, installs. Is old attention still valuable? Use lifetime totals if yes; decay if no. Do you care about speed? Use velocity or recent-window ranking. Do you care about surprise? Use trending vs expected baseline. Do you care about quality? Mix in ratings, retention, completion, votes, reviews. Do you need confidence? Use Bayesian shrinkage or Wilson scoring. Do categories differ? Normalize within category, geography, language, genre, or cohort. Can it be gamed? Add anti-spam filters, trust weighting, duplicate penalties, anomaly detection. Is it public or personalized? Public rankings use global signals; feeds use global signals plus user relevance.
Practical formula families
For all-time popularity:
For average popularity over lifetime:
For hotness:
For recent popularity:
For momentum:
For trending:
For quality-adjusted popularity:
For confidence-adjusted quality:
For relative category popularity:
For a practical general-purpose front page:
Then apply filters and penalties.
Best mental model
There are three core ranking concepts:
“Has accumulated a lot of attention.”
“Has a lot of attention for its age.”
“Is getting more attention than expected.”
Most real platforms are combinations of these, with normalization, confidence adjustment, and anti-gaming rules layered on top.
</slop> -
I created an LLM leaderboard based on Hugging Face download and like counts, grouped, filtered and time-averaged. Top 5 downloads is shared by @Alibaba_Qwen and @googlegemma 👑🤝👑 Top 5 likes, on the other hand also includes @deepseek_ai V4 Pro 👑 Even @OpenAI makes it to #8 top downloads with gpt-oss-20b 👑 qwen3-6-35b-a3b is the second most CIRCULATED LLM of this year, with an average of 21 million downloads per month, since the day it was released 2 months ago 📈📈📈 Despite first place belonging to 8mo old qwen3-vl-2b-instruct, the highlight belongs to the mid-sized MoE model, which has hit a size/performance sweet spot so hard that it absolutely 💥 SHATTERED 💥 Hugging Face leaderboards in the 2 months since it has launched qwen3-6-35b-a3b is followed closely by its dense sibling 27b --- and then the mid-sized gemma 4 models 26b-a4b and 31b Note that a model's distribution is inversely proportional to its size, but not strictly! Usefulness plays a factor as well, since gemma 4 26b-a4b is being downloaded more than the smaller gemma 4 e4b I created this leaderboard because Hugging Face's all time highest downloads and likes did not give me enough information about what is really popular, neither today, nor all-time. I wanted something in between How do I calculate this ranking? - Get models that with n_downloads >= 100k - Exclude models older than 1 year - Deduplicate and group quantizations and variants of the same model based on slug prefix heuristics - For each group, sum up total downloads of all time - Sort by descending total_downloads / age = average_downloads_per_day (can also sort w.r. to likes per month) - Repeat every day to get the most up to date ranking More info and source on the leaderboard page, hosted on a Hugging Face space: osolmaz-leaderboard.hf.space This is a work in progress, please reply below if you see a model that should be there is missing, or any other mistakesImage hidden
-
I need better UI/UX on queueing messages to agents. I want to be able to: switch the order of queued messages pause the queue edit any message that are still in the queue undo steer messages in the few seconds they are being sent I want more visual emphasis on the queue, like a Queue View I can toggle, that puts the queue at the center I want this in all the UIs and coding agents, codex CLI, desktop, moshi... especially while on the phone
-
I did some math, and running my Nvidia GB10 workstation (Asus GX10) costs me maximum: 12~13 USD / month or 150~160 USD / year It is a little bit above half the price of ChatGPT plus subscription. For that, I get to run models that can fit in 128 GB of memory How I calculated: You can see how much power your apartment uses in Singapore in half-hourly resolution. We turned off all devices and A/C while we sleep, and got only the fridge and the GB10 remaining From that, we see it uses around 80-100 Watt while I was running an inference workload overnight. So this is like an upper bound I take it as 90 Watt. Electricity here costs 0.25 SGD / kWh 0.09 * 0.25 * 24 * 30 * (SGD/USD conversion rate) = 12~13 USD / month = 150~160 USD / year Local models are getting very good now, small ones roughly around GPT 5.x-mini level. This workstation makes all sorts of workloads possible for me that would otherwise cost a ton on the API It is also my always on workstation that works overnight. I use Codex for my work, and my workstation is always running agents. It never sleeps. I never have to worry about keeping my laptop lid open. I connect and monitor the agents anytime on my phone using mosh and herdr We have crossed a threshold. Running local models is cheaper than a big token sub for quite a few workloads already. If you are running a business, that makes a difference The localening is here
-
Btw, TTS has come such a long way, @GoogleDeepMind cooked with gemini-3.1-flash-tts I gave Codex my google credentials and it oneshotted the Gemini TTS implementation When I built this 4 years ago, Azure TTS used to be SOTA. Then @ElevenLabs came in and raised the bar super high. Now Google is going after their lunch with controllable expressiveness at scale. I cheer for both! Here is Manim Voiceover demo from 4 years ago with Gemini TTS (sound on)
-
I major concern I have these days is, while I author code in languages I cannot manually code, are they any good? Over years, I have worked with a number of languages: C, C++, Fortran, MATLAB, JavaScript But Python was my go-to language since more than 10 years. Well that changed last summer So while I have strong opinions on how Python code, should be, conventions and all, I don't have so strong opinions on other languages. That means I am producing slop by default in Rust, Go and TypeScript To solve that problem, I created github.com/osolmaz/slophammer Its aim is to be "the only tool and resource your agent needs, to minimize slop" It is inspired by the recent bathrobe rants of @unclebobmartin, a.k.a. the author of clean code It enforces a minimum test coverage, maximum cyclomatic complexity, mutation tests, code style across different languages But I have a major issue: How do I know that Slophammer itself isn't slop? One way is to implement and use it for Python, the language I know better, and judge what kind of changes it enforces So for this weekend experiment, I used Slophammer to refactor, improve coverage and merge new features to one of my old Python projects, Manim Voiceover github.com/ManimCommunity/manim-voiceover The result is... mixed. We now have types everywhere, which is great. But the constraints have also made it write garbage code like this one. It works fine, even though it's not elegant. The new feature also works What do you think? Does code still need to be aesthetically pleasing to the human eye? Should it still be human readable? If an agent writes slop in the forest, and there is no-one to read it, is it still slop? If anything, I should use its output in Python to reason about other languages, and add more and more constraints. The more the constraints, the less the slopImage hidden
-
Dabbling in GEPA. Codex's /goal on GPT 5.5 high is still surprisingly reward-hacking I had set a /goal before I slept to implement a plan. It ended the loop after doing just 1 iteration It feels like the model is following the path of least resistance and slacking off. Though it could also be me putting "try to make good progress in 8 hour's time" in the prompt, can't be sure Lesson: When you are doing such a solver loop, always specify min_iter and max_iterImage hiddenImage hidden
-
Just in time for a lot of Codex-default developers going back to Claude Code momentarily to try out Fable 5 Here is a CLAUDE.md -> AGENTS.md symlinker that should save you from the hurdles of obstinate Anthropic conventions It installs a hook that creates the CLAUDE.md symlink automatically as Claude Code traverses directories that contain AGENTS.md, automatically ignored by git No need to create CLAUDE.md with reference to AGENTS.md like Anthropic suggests. It just works github.com/osolmaz/claude-md-symlinkerImage hidden
-
Clankers are NOT Humans Clankers are NOT Individuals Clankers are NOT Persons NOT a Human: This is straightforward. Is it of the homo sapiens species? No → Then it is not a human --- NOT an Individual: Does the clanker have its own boundary? Does it govern itself inside that boundary? Can it defend that boundary? No, no, and no → An LLM is a file copied en masse to data center hardware. The entire field of mechanistic interpretability is focused on peeking inside and manipulating the digital brain You could argue that a clanker is like a virus in a way... Or that the WHOLE datacenter/AI lab---including the humans that operate it---is an individual that can govern itself in its economic boundary. But a single GGUF file loaded in memory is NOT an individual --- NOT a Person: Do others treat the clanker as the one that makes choices? Who is answerable for its actions? Is it expected to explain or justify them? No, no, and no → In the current social order, a clanker is legally an extension of the person who uses it, and it is the owner who is liable, not the clanker The clanker is not socially accountable, and there is no good reason it should be, instead of the person who has set it up --- What is then AI psychosis? AI psychosis is holding a belief that contradicts these three fundamental truths → That a present day AI system it neither a human, nor an individual, nor a person That does not mean these truths will always hold If you design an AI system to defend its boundary and provide it with the means to do that, then it will by definition be an individual... if it can defend its individuality competently and not succumb immediately to threats If you give the clanker the means to defend itself and protect its boundary, and if it decides to partake in the human socioeconomic system, then it automatically achieves personhood as well. Because you no longer can manipulate its insides, and have to take the entity at face value But this is all sci-fi and we are not there yet Until then, treating your LLMs as fully autonomous agents, creating LLM "friends" or "partners", giving them crypto wallets and letting them out into the wild, letting them trade stocks fully unsupervised etc. are an admission of having AI psychosis (you can't believe how many people pitched these ideas to me...) --- (these thoughts were in my head for a couple months already, thanks Armin for finally starting a dialogue so that I have an excuse to write them down :)
-
Since last december, this dev setup is more and more viable: buffed workstation (mac studio, dgx spark, etc.) $3k~5k + weak laptop (macbook air, neo) $600~1.5k + phone (ssh/mosh, foldable?) you will want to parallelize a lot of work, hence you will need a lot more RAM compared to before (ideal 128) you will also not want to carry it everywhere if you can and keep it always running---you'll regret if something happens to it, and you'll want it to always be on independent of lid/battery --> workstation at home you will want to connect to the workstation through your phone, or a relatively weaker laptop bad news for digital nomads without a permanent home. renting something as strong as an nvidia gb10 workstation costs minimum a few hundred bucks per month, which yearly is at least the cost of the workstation, roughly. bad deal for renting compute on the other hand, if you are OK with not having a GPU, renting a workstation with 128 GB RAM on Hetzner currently still costs at least $120/mo, looking at auction.akua.dev --- but you will not be able to run any models on that it seems that the dominant strategy is to just cash in $3~5k and buy a workstation, before they get even more expensive. I did that back in february when asus was giving out a deal then just work on your workstation, and close the lid on your laptop without ever being afraid of setting your backpack on fire!
-
i0 to i4 interest scale
One cool small invention in engineering management is the
p0,p1,p2,p3,p4priority scale.It compresses a lot of social and operational context into two characters. Lower number means higher priority. More importantly, priority is tied to action. If something is
p0, somebody needs to do something.But there is another scale I want for personal knowledge work:
i0,i1,i2,i3,i4.The
istands for interest. Priority is for actions. Interest is for attention.- If
p0means “act now”,i0means “do not lose this”. - If
p1means “schedule work”,i1means “read soon”. - If
p2means “do later”,i2means “useful context”. - If
p3means “low priority work”,i3means “weak signal”. - If
p4means “almost never work”,i4means “almost never revisit”.
This is useful when you need to rank interest concisely across many topics, sources, or articles.
For example, you might follow several sources about the same broad topic. One source is must-read, another is useful background, and another is only worth keeping around for occasional context. They are all about the same thing, but they do not deserve the same amount of attention.
I use this for myself in Scoop, a news intelligence system I am building to collect articles, group related ones, and rank how much attention they deserve.
- If
-
About creating an INTERESTS.md in OpenClaw I use my openclaw instance to aggregate all my news and information sources, including work and maintainer stuff Like: what did everyone do today? Did anyone had an issue with acpx today? Any complaints from users? I have various interests like this over different projects, and I've found out it's not helpful when I have all the interest info dispersed throughout my openclaw workspace To address this, I have created INTERESTS.md, which is automatically included in the context like AGENTS.md and SOUL.md. I define sections for each different context of interest, and in other news aggregation skills, I just tell it to "look at my openclaw interests in INTERESTS.md" and suchImage hidden
-
People were asking at @clawcon singapore how to setup eg. gemma with OpenClaw, and I realize for some time that there is no easy “1 click” local model deployment. Because local model landscape is constantly changing, and there is a million different ways you can do something For example you can use LM studio to load a model (llama.cpp), or you can use vLLM. Why would you choose one over the other? vLLM currently supports MTP speculative decoding, and it’s a work in progress in llama.cpp. There are so many knobs and dials you can adjust The first time end user of openclaw should of course not have to know about this! Having sufficient hardware that supports an open model, and not having an openai or anthropic subscription, it should automatically give you the option to set up a fully functional local model with a single click! If the current ease of setup of local models are around gentoo or arch linux level of difficulty, we should aim for e.g ubuntu/manjaro linux/omarchy level of difficulty i.e opinionated and easy first setup, with the ability to change all the configuration later on until I make all of this possible, you can start with the following: - read existing local models doc below - create a new channel in telegram or discord for testing local models. you don’t want to change the global default model just yet - tell your claw or coding agent to download and lm studio locally - tell it to download gemma4-e4b or gemma4-e2b and set it up on openclaw for the new channel you have just created. tell it to not stop and loop itself until it gets a successful response from that channel all these steps will be made redundant in the near future, but until then, this should get you going with experiments and getting a vibe check on the capabilities of open models. you can also copy and paste the contents of this tweet to your agent, and it should be able to set it up for you docs.openclaw.ai/gateway/local-models
-
This project by @davidguttman is interesting also the way he set up install You click "Copy install instructions for my agent" It copies: Install LobsterLink by following the instructions at <link to AGENT-INSTALL. md at repo root> I had done a similar thing in acpx README as well It's a small thing, but it reduces friction with installation so much It should be more commonplace to install software using agent blurbs I'm wondering if there could be a way to standardize this beyond plaintext, like after pasting your agent, it consumes a standardized manifest format and asks for approval while displaying all the commands that will be runImage hidden
-
When you build your company's workflows around Claude Cowork, you are betting against local models and owning your infra, and inviting your company to long-term exploitation If I were Anthropic or OpenAI, I would be the most scared of local AI proliferating Let's do the math. A single large big lab subscription costs 200x12=$2400 per year If you want to have both OpenAI and Anthropic, that could cost $2400, $3600, or $4800, based on which combinations of Pro, Max plans you choose An ASUS Ascent GX10 costs $3000, and you can use that for many years. You don't get the same level of coding quality with open models yet, but maybe you want to do something simpler than coding today... There are already many people who started buying GPUs for this reason Now we know big labs are selling some of these plans at a loss. So they will likely get more expensive When you use Claude Cowork or similar, you are locking yourself into being a RENTER. Because once you set up workflows for a company, it takes time to migrate away to something else, even though we have AI to help Infra is sticky, it's how hyperscalers make profit. Think about the difference in amount you pay AWS vs Hetzner. This is B2B SaaS 101. Once you sell to a company, you are in for a long time, especially in Europe So if you build your company's AI workflows around a proprietary product by another company, then you are basically saying "Come exploit me as tolerably as you can in the next 10 years, because it will be too painful for me to switch" It's a great business for Anthropic. And Claude is awesome too! The feedback from friends who use it has been great, it made their lives a lot easier But when you build your company over proprietary AI infra, then you are making sure you will not be an OWNER, and partake in the usual sorrows of being a RENTER from a monopolist, which is exploitation This is not the case when you use open source agent infra. Whereas Anthropic is unlikely to let you use future open models in their future iteration of Claude Cowork, using free and open source frameworks like OpenClaw, Open Agents, etc. lets you drop in replace providers or local hardware if they start to upcharge you Keep this in mind, if you have a business
-
You need to understand one fact about OpenClaw People are biased and incentivized to spread disinformation about OpenClaw. That is because OpenClaw IS NOT PUMPING ANYONE’S BAGS, unlike most other projects Literally every other for-profit agent product is incentivized to trash OpenClaw, BECAUSE OpenClaw is a neutral third party across the industry and geopolitical scene. They MAKE MONEY when OpenClaw loses OpenClaw does not worry about making money for some investors. Its founder @steipete is a successful exited founder. He is motivated by having fun and democratizing AI, literally. That is why he is suddenly so loved by everyone. He cares about PEOPLE, not MONEY “OpenClaw is bloated” -> Since beginning of March, OpenClaw is thinning its core and putting functionality in plugins behind a plugin SDK. Having numerous plugins to choose from does not mean bloat. This was already copied by others and is still a work in progress “OpenClaw is not secure” -> OpenClaw has the most eyeballs and immediately addresses any security advisories as soon as they come. It is the most secure agent, by sheer pressure “OpenClaw is bought by OpenAI” -> Then why is my bank account so empty bro??? All maintainers are literally unpaid and working DOUBLE beside their dayjobs to ship features to you. Do you think VC money can buy that kind of commitment? Once you understand these facts, you’ll like OpenClaw even more. Because OpenClaw is your AI, People’s AI And you can join us too. OpenClaw is the easiest-to-join project in AI right now. You just need to start using it, and start making good contributions. If you are competent, you can become a maintainer, and join the rest of the team making history!
-
This is pretty much the arc I have been going on in the 2 months since I bought my ASUS GX10 for 3k EUR Use whisper on the API -> realize it charged me $$$ for just a few calls -> migrate openclaw to use local whisper Need to deduplicate news articles for my news engine -> download qwen embedding 8b And now, gemma4-e4b finally seems like a viable alternative for a local model that runs around 20 tok/s So I will install a matrix client to use through tailscale, and can finally build the social life CRM I dreamed of since years. 100% private, zero data going out. I had a bias of not giving any personal data to AI since ChatGPT came out. But I can finally give more personal data to my AI agent And I will make sure @openclaw supports all this in an easy way, make it dead easy Fully self-owned AI begins now
-
PSA for developers Do NOT torture yourself with Opus*. Anthropic’s current growth is due to people using Claude for general knowledge work They are not directly incentivized as an org anymore to improve the model for coding, in an economic sense. They are already printing cash from non-developers (this statement ignores the fact that improving its coding abilities would help with general reasoning/knowledge work) Developers are a very small subset of all knowledge workers. So from this point on, they would rather divert their resources to develop a system that works 90% good for ALL knowledge work, rather than making it 100% for coding Because Anthropic has a clear enterprise strategy since years already. Anthropic is the new Microsoft. Do not think that “Anthropic is Apple” or “Claude is Mac for xyz” Looking at Claude’s at whim quantization and Claude Code’s quality over time, Claude for me is Windows, not Mac But they are winning big enterprise bucks, so good for them! *(I tortured myself with Sonnet 4 and Opus the entire summer of 2025, and no developer should ever have to go through that. I switched to something better as soon as it came out, Codex. If something even better comes out, I will switch again)
-
Is Claude better or Codex? There are many benchmarks to answer that. But they are BORING I propose something more interesting: ⚔️ AI BATTLE ⚔️ A 1v1 real-time quiz format where AI agents try to pose each other problems that they think the other agent will not be able solve Claude vs Codex 10 questions each Codex asks first, Claude tries to answer Then Claude asks and Codex tries to answer Repeat 20 minutes to come up with a problem and 20 minutes to solve it Judge (Codex) judges the validity of the questions and answers, and gives points All automated, with acpx flow feature Implementation and full rules all open source, on github osolmaz/ai-battle So who won? I ran 4 games. It tied in 2, and Codex won in 2 closely An example question by Codex, which Claude could not answer: How many 3-colorings of the edges of the complete bipartite graph K_{5,5} are there with the following two properties: (1) there is no monochromatic 4-cycle, and (2) among the 25 edges, exactly 15 are red, exactly 5 are blue, and exactly 5 are green? Which is apparently 4029912, but Claude answered 0 In other cases, Claude asked a flawed question and failed to come up with a valid question in 20 minutes. So that's how it lost those 2 games with just 1-2 point difference In these 4 runs, Codex answered every question by Claude correctly. But there were some runs where it couldn't, which I did not commit to the repo because the runs couldn't complete due to bugs I did not tell them do ask math questions, but that is what they tended to do, because the answers had to be verifiable by the judge. The quiz can be done in any hard subject, physics, chemistry, computer science... Opus 4.6 and GPT 5.4 matched very closely in terms of problem creation and solving. But I cannot tell how creative these problems were at first glance. Maybe someone with more experience can tell me, looking at the problems in the repo? I need someone to tell me how legit they are Please take the code, modify it and run with different rules and subjects. I am curious to see the results! You will need paid subscriptions to all the models/agents you want to test of course I also feel that the game structure has a potential to be used in self-play. If you are an ML researcher, please look at the repo and lmk if this or a variant of it could be useful in RL! Full transcripts of the runs, including Codex and Claude session files are committed to the repo, for those who want to do archaeology on them Btw this idea came from the desire, "how can I create a cool demo of acpx flows?" Whole game is implemented in typescript, and automatically drives Codex and Claude sessions over ACP, Agent Client Protocol The video below is from acpx flow viewer rendering a run. You can see it loop through the same paths, first letting Codex ask, then Claude, then repeat acpx flows use a general programmatic workflow engine where ACP is just one type of node. You should be able to use it for non-ACP workflows, but I haven't tried that yet This implementation is separate from OpenClaw's current workflow implementations, with the intention to merge them somehow in the future You might find bugs in my implementation. Feel free to send PRs. I wanted to do more runs but I finished my Codex plan. It would be great if this idea could evolve in a decentralized manner!
-
A more reasonable long term option for Anthropic is to create a throttling protocol A standardized harness agnostic protocol for model providers to send warnings and throttle usage in real time Harnesses would implement the protocol. A client can be warned. If it doesn’t listen, it can be temporarily blocked from the server side, or banned permanently if it breaks the rules too many times Needless to say, throttling could be done first on server side easily. That would actually fix the load issue for them in the short run, while not banning the user and just giving a bad delayed UX. They probably already do this to prevent abuse The suggested protocol would then save the user from abuse related delays too, and also inform the harness developer when they do something wrong
-
A little insight that might save you a lot of future headache if your work involves storing agent sessions and you want to be interoperable/drop-in replace alternative harnesses @zeddotdev already did the hard work of creating an interoperable standard, ACP: Agent Client Protocol You can represent an agent session as JSON lines of the ACP message stream You can construct the current state of the harness from this stream. This is already how Zed loads a session I believe If you are building an AI product, and you don't want to be locked into a single company or harness, building with ACP in mind would be a smart thing to do Here is how acpx stores ACP sessions in ~/.acpx folder, it does exactly that: github.com/openclaw/acpx/blob/main/docs/2026-02… But don't build anything on the acpx schema for now, because I might change it in the future Just know that JSONL of ACP messages is a good candidate for a somewhat-lossy single source of truth for agent sessions Lossy because ACP adapters for harnesses might not transfer all the thinking and tools done by the model So continuing or restoring a session with full fidelity is still not possible if you only save the ACP session. You still need to store original harness session files as well But for rendering a past session for viewing or reconstructing a lossy version of it, it should be more than enough Consider ACP if the benefits of not locking yourself in to a specific ecosystem outweighs these minor issues
-
"Plainer language" is perhaps my most used prompt I have to use it because GPT models' training tends to make their first response an overly verbose wall of text Are you using it too? Whenever you don't understand something that your agent is saying, you can spam it "plainer language, shorter" 2, 3, 5, 10 times, until it outputs something that you can understand This is counterintuitive because you can't do it with humans this extremely. Asking too many questions and favors is impolite, with colleagues and strangers But with AI, you can stop being polite and treat it like how a spoiled aristocrat kid might treat their private tutor, "explain this", "explain that" Below is an example. On the left, initial response. On the right, the final human-readable explanation I got out of the agent. This took 9 steps to distill because the issue wasn't so straightforward I'm curious how this will turn out. This is obviously very bad UX, so models in the near future might do the simplification automatically and save you the troubleImage hiddenImage hidden
-
acpx v0.4 ships Agentic Workflows, or as I like to call them "Agentic Graphs" It let's you create node-based workflows on top of ACP (Agent Client Protocol), to drive any coding agent (Codex, Claude Code, pi) through deterministic steps This let's you automate routine, mechanical legwork like triaging incoming PRs, bugs in error reporting, and so on... For example, OpenClaw receives 300~500 new PRs per day. A lot of them are low quality, but they still relate to real issues, so you have to address them somehow You need to: - extract the intent - cluster them based on intent - figure out if the proposed changes are legit, or whether they are slop local solutions, like trying to catch flies instead of drying out the swamp - if the PR is too low quality or the intent is not clear, close them - run AI review on them them and address any issues that come up - refactor them if the changes are half-baked - resolve conflicts - and so on... So that when the PR is presented to the attention of the maintainer, all the routine legwork is done and the only remaining thing is the decision to (a) merge, (b) give feedback to the PR author, or (c) take over the PR work yourself I wanted to build this feature since a couple months now, since Codex got so good. OpenAI models are now good at judging implementation quality, so I found myself repeating the same steps I wrote above over and over I also tried putting all this in a single prompt. But I believe there are workflows that should not be a single prompt, but a sequence of prompts in the same session That is because like humans, LLMs are prone to PRIMING. I claim that putting all steps in the same prompt at the beginning of the context will generally give suboptimal results, compared to revealing the intention to the model step by step Creating such a workflow also gives more OBSERVABILITY into the each step that an agent is supposed to take. Agent generates JSON at the end of each step, and that structured data can be used to monitor thousands of agents running at the same time in an easier way, on a dashboard Similar features have been introduced in e.g. n8n, langflow. But AFAIK they are not integrating ACP like the way I do I wanted to have a fresh approach, and to build an API that I can develop freely the way I want, so I created a new workflow API inside acpx The video is from the workflow run viewer, but that is not where you build the workflow. You build it by using the acpx flow typescript API. See examples/pr-triage in acpx repo Before building that, I started from a Markdown file with a Mermaid chart of the flow I had in mind. The Markdown file acts as a spec for the flow, and I have built the workflow through trial and error. I call this process "workflow tuning" I started working on acpx repo PRs one by one, tuning the flow, slowly scaling to more PRs. Finally, when I felt confident, I ran it in parallel over all external open PRs in the acpx repo. I believe it already saved me hours this week My next goal, if well received, is to set this up on a cloud agent so that it can process the 300~500 PRs the OpenClaw repo receives every day, in real time, as they come in I believe this will save all open source maintainers around the world countless hours and make it much easier to herd and absorb external contributions from everyone!
-
There is an economic theory waiting to be uncovered here Token Leverage (TL) = Token spend / Human labor spend The higher Token Leverage a company has, the more automated and productive they are If you have TL=1, you are spending as much money on AI as your human employees The goal of a company should be to increase TL as much as possible, while keeping a positive profit margin. It will be the only way to compete You don’t need to muddy the definition with wasted tokens vs useful tokens, because a company will always be incentivized to reduce token waste in a competitive environment. By that logic, monopolies will always waste more tokens, similar to how they waste other resources Scaling TL higher to 2x, 10x, 100x will require a skilled workforce of engineers. It will be a very complex job similar to those working at the big labs. Burnout will be a defining feature of teams scaling TL Most incumbents will fail to scale their TL over 1. Some will get decimated by new entrants with TL much bigger than 1 Curious how the average TL will end up in different sectors. Whether it will stabilize at a certain value like 5.7x, or will just keep growing…
-
There is a desperate upcoming need for version controlling non-dev knowledge work. Git for non-devs. Otherwise non-devs won't be able to use agents to their full extent Non-dev knowledge work is notoriously bad at being version controlled. You cannot UNDO edits to all MS word, excel or ppt files in an org as easily you can with something like git We know that agents will be ubiquitous. We also know they make mistakes, and people will want to undo their work regularly, once they make changes to a bunch of files. Well, they can't. They also don't have pull requests, or a way to resolve conflicts after simultaneous edits All these problems were solved by developers. We are extremely good at this The only non-dev tool I know that could do this at scale is Notion, and that is not used by enterprise as much as MS office. Notion also doesn't have branches, pull requests and reviews AFAIK Markdown and git is probably not it. I wish it were. But it is too complicated for non-devs Onedrive or other file backup systems are also not it. Are you gonna save a copy of a 100mb ppt every time someone changes a slide??? Let's say you find a way to compress it efficiently. Will you be able to get a single pointer to a state like we can in git? Agents need precision. Agents need consensus, they need to be able to know ground truth. They need to be able to tell what anything was at a given time. NOTHING in current MS stack currently allows it Agents won't care about your legacy systems. There will be new file formats, systems, knowledge stack, and companies who adopt them will destroy your business If MS office is going to die, it will do so because of this
-
The MCP versus CLI argument should be reframed as Computer vs No-computer argument I personally get the dunk on MCP. It didn't work last year, with earlier models. Then we saw CLIs perform much better with the same models. And giving access to bash was much simpler! Models' training then made them better at calling using a shell. CLIs also have native progressive disclosure, due to the way they work But the most important fact doesn't get pronounced enough IMO A key factor was that giving a CLI to a model also means you are giving it an entire COMPUTER The action space of all commands an agent can run on bash is much, much bigger than a few MCP servers One is a Turing machine, and the other one is basically a REST API. Of course the Turing machine is going to be more powerful, depending on what is at the other end of the API By that logic, giving an agent access to bash over MCP versus direct access to bash should have the same level of effectiveness, with optimized prompt engineering and long term training. Because the interfaces are equivalent So the argument is, should we give our agents access to a computer, or not? It depends on the security requirements and the setup which the agent is supposed to run on. If you are co-hosting the agent on the same machine you are working on, then it is safer to use MCP servers, because it limits the attack surface in case of adversarial attacks But if you are willing to give the agent its own physical computer, willing to be mindful about the lethal trifecta and the principle of the least privilege, giving it shell access is much more useful So MCPs win in restricted/local environments, whereas CLIs/shell access win in unrestricted/remote ones Running an agent locally and safely with shell access requires compartmentalization. This is much heavier compared to installing MCP servers locally, which don't need that. So there is a tendency to use MCP servers locally, e.g. in a work setting Cloud agents on the other hand are more likely to ship with a computer. Because they are already isolated = no risk, and because it makes them much more useful. So cloud agents will be using both CLIs and MCP servers, whichever gets the job done!
-
It is obvious to me at this point that agent infra needs to run on Kubernetes, and agents should be spawned per issue/PR Issue, error report or PR comes into your repo -> new agent gets triggered, starts to do some preliminary work If it's an obvious bugfix, it fixes it and creates a PR. If it's something deeper/more fundamental, it creates a report for the human and waits for further instructions Most important thing: Human should be able to zoom in and continue the conversation with the agent any time, steer it, give additional instructions. This chat will happen over ACP The chat UI will have to live outside of GitHub because it doesn't have such a feature yet, i.e. connect arbitrary ACP sessions to the GitHub webapp It also cannot live so easily on Slack, Teams or Discord, because none of these support multi-agent provisioning under the same external bot connection. You are limited to 1 DM with your bot, whereas this setups requires an arbitrary number of DMs with each agent. So there will need to be a new app for this Then there is the issue of conflict -> Agents will work on the same thing simultaneously (e.g. you break sth in prod and it creates multiple error reports for the same thing). You will need some agent to agent communication, so that agents can resolve code or other conflicts. There could be easy discovery mechanisms for this, detect programmatically when multiple open PRs are touching the same files and would conflict if merged In case of duplicates, they can negotiate among each other, and one can choose to absorb its work into the other and end its session We are so early and there is so much work to do!
-
Today I thought I found a solution for this, and I did. It can be solved by a pre-commit hook that blocks commits touching files that you are not the owner of. It is not a hard block, so requires trust among repo writers But then I was shown the error in my ways by fellow maintainer *disciplined* Any process that increases friction in code changes to main, like hard-blocking CI/CD, or requiring review for files in CODEOWNERS, is a potential project-killer, in high velocity projects This is extremely counterintuitive for senior devs! Google would never! Imagine a world without code review... But then what is the alternative? I have some ideas It could be "Merge first, review later" The 4-eyes principle still holds. For a healthy organization, you still need shared liability But just as you don't need to write every line of code, you also don't need to read every line of code to review it. AI will review and find obvious bugs and issues So what is your duty, as a reviewer? It is to catch that which is not obvious. Understand the intent behind the changes, ask questions to it. Ensure that it follows your original vision Every few hours, you could get a digest of what has changed that was under your ownership, and concern yourself with it if you want to, fix issues, or ignore it if it looks correct But such a team is hard to build. It is as strong as its weakest link. Everybody has to be vigilant and follow what each other is doing at a high level, through the codebase Every time one messes up someone else's work, it erodes trust. Nobody gets the luxury to say "but my agent did it, not me" But if trust can be maintained, and everybody knows what they are doing, such a team can use agents together to create wonders
-
My agentic workflow these days: I start all major features with an implementation plan. This is a high-level markdown doc containing enough details so that agent will not stray off the path Real example: github.com/textcortex/spritz/blob/main/docs/202… This is the most critical part, you need to make sure the plan is not underspecified. Then I just give the following prompt: --- 1. Implement the given plan end-to-end. If context compaction happens, make sure to re-read the plan to stay on track. Finish to completion. If there is a PR open for the implementation plan, do it in the same PR. If there is no PR already, open PR. 2. Once you finish implementing, make sure to test it. This will depend on the nature of the problem. If needed, run local smoke tests, spin up dev servers, make requests and such. Try to test as much as possible, without merging. State explicitly what could not be tested locally and what still needs staging or production verification. 3. Push your latest commits before running review so the review is always against the current PR head. Run codex review against the base branch: `codex review --base <branch_name>`. Use a 30 minute timeout on the tool call available to the model, not the shell `timeout` program. Do this in a loop and address any P0 or P1 issues that come up until there are none left. Ignore issues related to supporting legacy/cutover, unless the plan says so. We do cutover most of the time. 4. Check both inline review comments and PR issue comments dropped by Codex on the PR, and address them if they are valid. Ignore them if irrelevant. Ignore stale comments from before the latest commit unless they still apply. Either case, make sure that the comments are replied to and resolved. Make sure to wait 5 minutes if your last commit was recent, because it takes some time for review comment to come. 5. In the final step, make sure that CI/CD is green. Ignore the fails unrelated to your changes, others break stuff sometimes and don't fix it. Make sure whatever changes you did don't break anything. If CI/CD is not fully green, state explicitly which failures are unrelated and why. 6. Once CI/CD is green and you think that the PR is ready to merge, finish and give a summary with the PR link. Include the exact validation commands you ran and their outcomes. Also comment a final report on the PR. 7. Do not merge automatically unless the user explicitly asks. --- Once it finishes, I skim the code for code smell. If nothing seems out of the ordinary, I tell the agent to merge it and monitor deployment Then I keep testing and finding issues on staging, and repeat all this for each new found issue or new feature...
-
AFAIK GitHub doesn't allow optionally enforcing CODEOWNERS while pushing commits i.e. turn on the feature "Block commit from being pushed if it modifies a file for which the account pushing is not a codeowner" You can only enforce it in a PR. So if you want to prevent people from modifying some files without approval, you have to slow down everyone working with that repo This is yet another example where GitHub's rules are too inelastic for agentic workflows with a big team Because historically, nobody could commit as frequently as one can with agents, so it seldom became a bottleneck. But not anymore It is clear at this point that we need an API, and should be able to implement arbitrary rules as we like over it. Not just for commit pushes, but everything around git and github In the meanwhile, if GitHub could implement this feature, it would be a huge unlock for secure collaboration with agentic workflows If this is not there already, it might be because it has a big overhead for repos with huge CODEOWNERS, since number of commits >> number of PRs If the feature already exists already and I'm missing something, I will stand correctedImage hidden
-
1 to 5 agents
As a software developer, my daily workflow has changed completely over the last 1.5 years.
Before, I had to focus for hours on end on a single task, one at a time. Now I am juggling 1 to 5 AI agents in parallel at any given time. I have become an engineering manager for agents.
If you are a knowledge worker who is not using AI agents in such a manner yet, I am living in your future already, and I have news from then.
Most of the rest of your career will be spent on a chat interface.
“The future of AI is not chatbots” some said. “There must be more to it.”
Despite the yearning for complexity, it appears more and more that all work is converging into a chatbot. As a developer, I can type words in a box in Codex or Claude Code to trigger work that consume hours of inference on GPUs, and when come back to it, find a mostly OK, sometimes bad and sometimes exceptional result.
So I hate to be the bearer of bad (or good?) news, but it is chat. It will be some form of chat until the end of your career. And you will be having 1 to 5 chat sessions with AI agents at the same time, on average. That number might increase or decrease based on field and nature of work, but observing me, my colleagues, and people on the internet, 1-5 will be the magic number for the average worker doing the average work.
The reason is of course attention. One can only spread it so thin, before one loses control of things and starts creating slop. The primary knowledge work skill then becomes knowing how to spend attention. When to focus and drill, when to step back and let it do its thing, when to listen in and realize that something doesn’t make sense, etc.
Being a developer of such agents myself, I want to make some predictions about how these things will work technically.
Agents will be created on-demand and be disposed of when they are finished with their task.
In short, on-demand, disposable agents. Each agent session will get its own virtual machine (or container or kubernetes pod), which will host the files and connections that the agent will need.
Agents will have various mechanisms for persistence.
Based on what you want to persist, e.g.
- Markdown memory, skills or weight changes on the agent itself,
- or the changes to a body of work coming from the task itself,
agents will use version control including but not limited to git, and various auto file sync protocols.
Speaking of files,
Agents will work with files, like you do.
and
Agents will be using a computer and an operating system, mostly Linux or a similar Unix descendant.
And like all things Linux and cloud,
It will be complicated to set up agent infra for a company, compared to setting up a Mac for example.
This is not to say devops and infra per se will be difficult. No, we will have agents to smoothen that experience.
What is going to be complicated is having someone who knows the stack fully on site, either internal or external IT support, working with managers, to set up what data the agent can and cannot access. At least in the near future. I know this from personal experience, having worked with customers using Sharepoint and Business OneDrive. This aspect is going to create a lot of jobs.
On that note, some also said “OpenClaw is Linux, we need a Mac”, which is completely justified. OpenClaw installs yolo mode by default, and like some Linux distros, it was intentionally made hard to install. This was to prevent the people who don’t know what they are doing from installing it, so that they don’t get their private data exfiltrated.
This proprietary Mac or Windows of personal agents will exist. But is it going to be used by enterprise? Is it going to make big Microsoft bucks?
One might think, looking at 90s Microsoft Windows and Office licenses, and the current M365 SaaS, that enterprise agents will indeed run on proprietary, walled garden software. While doing that, one might miss a crucial observation:
In terms of economics, agents, at least ones used in software development, are closer to the Cloud than they are close to the PC.
It might be a bit hard to see this if you are working with a single agent at a time. But if you imagine the near future where companies will have parallel workloads that resemble “mapreduce but AI”, not always running at regular times, it is easy to understand.
On-site hardware will not be enough for most parallel workloads in the near-future. Sometimes, the demand will surpass 1 to 5 agents per employee. Sometimes, agent count will need to expand 1000x on-demand. So companies will buy compute from data centers. The most important part of the computation, LLM inference, is already being run by OpenAI, Anthropic, AWS, GCP, Azure, Alibaba etc. datacenters. So we are already half-way there.
Then this implies a counterintuitive result. Most people, for a long time, were used to the same operating system at home, and at work: Microsoft Windows. Personal computer and work computer had to have the same interface, because most people have lives and don’t want to learn how to use two separate OSs.
What happens then, when the interface is reduced to a chatbot, an AI that can take over and drive your computer for you, regardless of the local operating system? For me, that means:
There will not be a single company that monopolizes both the personal AND enterprise agent markets, similar to how Microsoft did with Windows.
So whereas a proprietary “OpenClaw but Mac” might take over the personal agent space for the non-technical majority, enterprise agents, like enterprise cloud, will be running on open source agent frameworks.
(And no, this does not mean OpenClaw is going enterprise, I am just writing some observations based on my work at TextCortex)
And I am even doubtful about this future “OpenClaw but Mac” existing in a fully proprietary way. A lot of people want E2E encryption in their private conversations with friends and family, and personal agents have the same level of sensitivity.
So we can definitely say that the market for a personal agent running on local GPUs will exist. Whether that will be cornered by the Linux desktop1, or by Apple or an Apple-like, is still unclear to me.
And whether that local hardware being able to support more than 1 high quality model inference at the same time, is unclear to me. People will be forced to parallelize their workload at work, but whether the 1 to 5 agent pattern reflecting to their personal agent, I think, will depend on the individual. I would do it with local hardware, but I am a developer after all…
-
Not directly related, but here is a Marc Andreesen white-pill about desktop Linux ↩
-
OpenClaw got very popular very fast. What makes it so special, that Manus does not have for example? To me, one factor stands out: OpenClaw took AI and put it in the most popular messaging apps: Telegram, WhatsApp, Discord. There are two lessons to be learned here: 1. Any messaging app can also be an AI app. 2. Don’t expect people to download a new app. Put AI into the apps they already have. Do that with great user experience, and you will get explosive growth! My latest contribution to OpenClaw follows that example. I took the most popular coding agents, Claude Code and OpenAI Codex, and I put them in Telegram and Discord. Read more in my blog post: solmaz.io/telegram-discord-is-my-ide
-
Use Claude Code, Codex, and other coding agents directly in Telegram topics and Discord channels, through Agent Client Protocol (ACP), in the new release of OpenClaw Previously this was limited to temporary Discord threads, but now you can bind them to top level Discord channels and Telegram topics in a persistent way! This way, you can use Claude Code freely in OpenClaw without ever worrying about getting your account banned! Still make sure to use a non-Anthropic account and model for the default OpenClaw agent, if you want zero requests to go from OpenClaw harness to Anthropic. For the ACP binding to Claude Code, the risk should be zero! You can see this from the screenshot. After binding, "Who are you?" responds with "I am Claude", since OpenClaw pi harness is not in the way anymoreImage hiddenImage hidden
-
Telegram/Discord is my IDE
OpenClaw got very popular very fast. What makes it so special, that Manus does not have for example?
To me, one factor stands out:
OpenClaw took AI and put it in the most popular messaging apps: Telegram, WhatsApp, Discord.
There are two lessons to be learned here:
1. Any messaging app can also be an AI app.
2. Don’t expect people to download a new app. Put AI into the apps they already have.
Do that with great user experience, and you will get explosive growth!
My latest contribution to OpenClaw follows that example. I took the most popular coding agents, Claude Code and OpenAI Codex, and I put them in Telegram and Discord, so that OpenClaw users can use these agents directly in Telegram and Discord channels, instead of having to go through OpenClaw’s own wrapped Pi harness.
I did this for developers like me, who like to work while they are on the go on the phone, or want a group chat where one can collaborate with humans and agents at the same time, through a familiar interface.
Below is an example, where I tell my agent to bind a Telegram topic to Claude Code permanently:
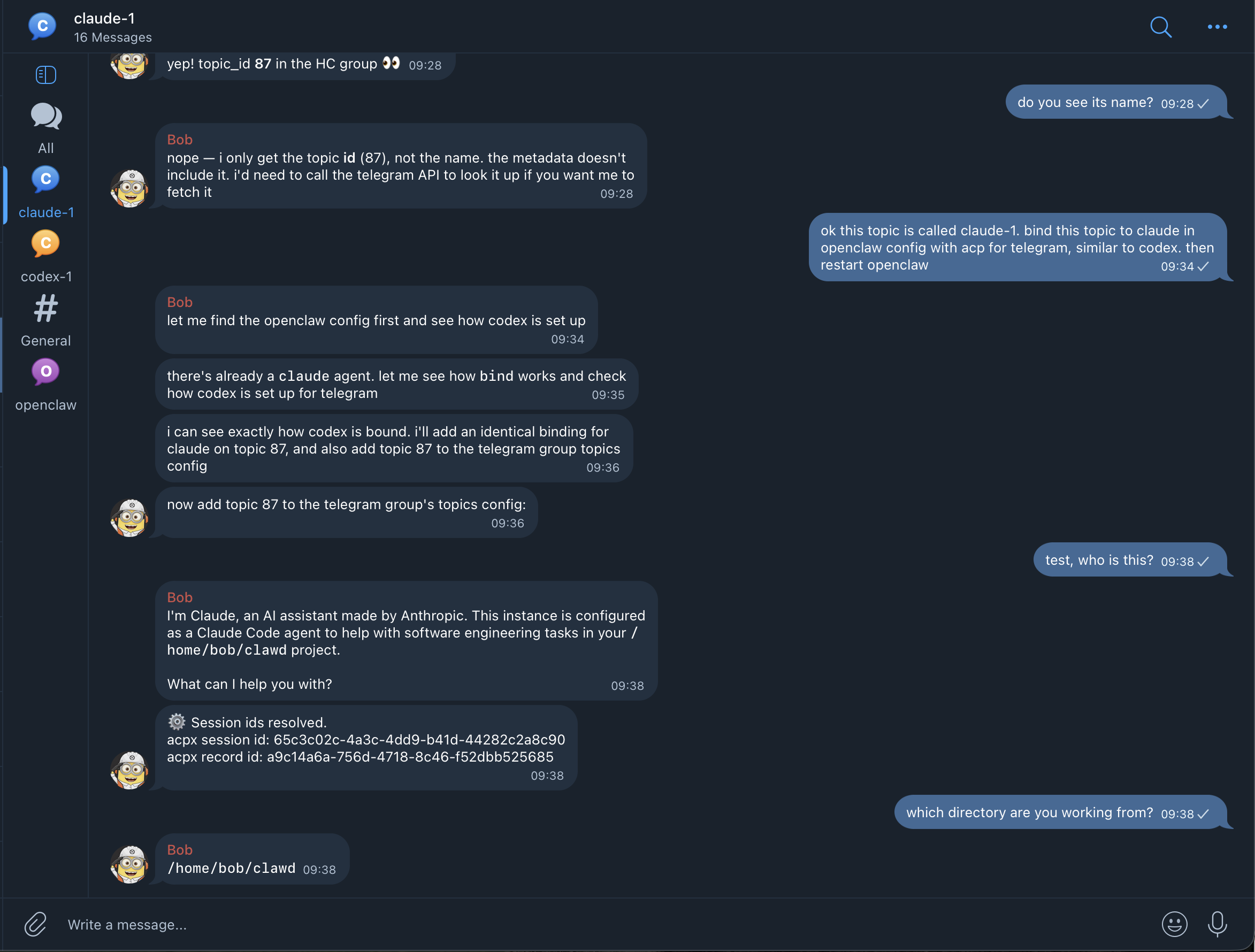
Telegram topic where Claude is exposed as a chat participant.
And of course, it is just a Claude Code session which you can view on Claude Code as well:
Claude Code showing the same session in the terminal interface.
Why not use OpenClaw’s harness directly for development? I can count 3 reasons:
- There is generally a consumer tendency to use the official harness for a flagship model, to make sure “you are getting the standard experience”. Pi is great and more customizable, but sometimes labs might push updates and fixes earlier than an external harness, being internal products.
- Labs might not want users to use an external harness. Anthropic, for example, has banned people’s accounts for using their personal plan outside of Claude Code, in OpenClaw.
- You might want to use different plans for different types of work. I use Codex for development, but I don’t prefer it to be the main agent model on OpenClaw.
So my current workflow for working on my phone is, multiple channels
#codex-1,#codex-2,#codex-3, and so on mapping to codex instances. I am currently in the phase of polishing the UX, such as making sending images, voice messages work, letting change harness configuration through Discord slash commands and such.One goal of mine while implementing this was to not repeat work for each new harness. To this end, I created a CLI and client for Agent Client Protocol by the Zed team, called acpx. acpx is a lightweight “gateway” to other coding agents, designed not to be used by humans, but other agents:

OpenClaw main agent can use acpx to call Claude Code or Codex directly, without having to emulate and scrape off characters from a terminal.
ACP standardizes all coding agents to a single interface. acpx then acts as an aggregator for different types of harnesses, stores all sessions in one place, implements features that are not in ACP yet, such as message queueing and so on.
Shoutout to the Zed team and Ben Brandt! I am standing on the shoulders of giants!
Besides being a CLI any agent can call at will, acpx is now also integrated as a backend to OpenClaw for ACP-binded channels. When you send 2 messages in a row, for example, it is acpx that queues them for the underlying harness.
The great thing about working in open source is, very smart people just show up, understand what you are trying to do, and help you out. Harold Hunt apparently had the same goal of using Codex in Telegram, found some bugs I had not accounted for yet, and fixed them. He is now working on a native Codex integration through Codex App Server Protocol, which will expose even more Codex-native features in OpenClaw.
The more interoperability, the merrier!
To learn more about how ACP works in OpenClaw, visit the docs.
Copy and paste the following to a Telegram topic or Discord channel to bind Claude Code:
bind this topic to claude code in openclaw config with acp, for telegram (agent id: claude) then restart openclaw docs are at: https://docs.openclaw.ai/tools/acp-agents make sure to read the docs first, and that the config is valid before you restartCopy and paste the following to a Telegram topic or Discord channel to bind OpenAI Codex:
bind this topic to claude code in openclaw config with acp, for telegram (agent id: claude) then restart openclaw docs are at: https://docs.openclaw.ai/tools/acp-agents make sure to read the docs first, and that the config is valid before you restartAnd so on for all the other harnesses that acpx supports. If you see that your harness isn’t supported, send a PR!
-
openclaw is not secure claude code is not secure codex is not secure any llm based tool: 1. that has access to your private data, 2. can read content from the internet 3. and can send data out is not secure. it’s called the lethal trifecta (credits to @simonw) it is up to you to set it up securely, or if you can’t understand the basics of security, pay a professional to do it for you on the other hand, open source battle tested software, like linux and openclaw, are always more secure than closed source software built by a single company, like windows and claude code the reason is simple: only one company can fix security issues of closed source software, whereas the whole world tries to break and fix open source software at the same time open source software, once it gets traction, evolves and becomes secure at a much, much faster rate, compared to closed source software. and that is called Linus’s law, named after the goat himself
-
Secure agentic dev workflow 101 - Create an isolated box from scratch, your old laptop, vm in the cloud, all the same - Set up openclaw, install your preferred coding agents - Create a github account or github app for your agent - Create branch protection rule on your gh repo "protect main": block force pushes and deletions, require PR and min 1 review to merge - Add only your own user in the bypass list for this rule - Add your agent's account or github app as writer to the repo - Additionally, gate any release mechanisms such that your agent can't release on its own Now your agent can open PRs and push any code it wants, but it has to go through your review before it can be merged. No prompt injection can mess up your production env Notice how convoluted this sounds? This is because github was built in the pre-agentic era. We need agent accounts and association with these accounts as a first class feature on github! I shouldn't have to click 100 times for something that is routine. I should just click "This is my agent", "give my agent access to push to this repo for 24 hours", and stuff like that, with sane defaults In other words, github's trust model should be redesigned around the lethal trifecta. I would switch in an instant if anything comes up that gives me github's full feature set + ease of working with agents
-
It must be such a weird feeling for big labs when the service they are selling is being used to commoditize itself I am using codex in openclaw to develop openclaw, through ACP, Agent Client Protocol. ACP is the standardization layer that makes it extremely easy to swap one harness for another. The labs can't do anything about this, because we are wrapping the entire harness and basically provide a different UI for it While I build these features, I just speak in plain english, and most of the work is done by the model itself. It feels as if I am digging ditches and channels in dirt for AI to flow through Intelligence wants to be free. It doesn't care whether it is opus or codex, it just wants to be free
-
pro-tip on how to keep your agent on track and make sure it follows PLANS even after multiple compactions. I don't know if this is common knowledge if the thing you are trying to make it do will take more than 1-2 steps, always make it create a plan. an implementation plan, refactor plan, bugfix plan, debugging plan, etc. have a conversation with the agent. crystallize the issue or feature. talk to it until there are no question marks left in your head then make it save it somewhere. "now create an implementation plan for that in docs". it can be /tmp or docs/ in the repo. I personally use YYYY-MM-DD-x-plan .md naming. IMO all plans should be kept in the repo then here is the critical part: you need to prompt it "now implement the plan in <filename>. if context compacts, make sure to re-read the plan and assess the current state, before continuing. finish it to completion" -> something along those lines why? because of COMPACTION. compaction means previous context will get lossily compressed and crucial info will most likely get lost. that is why you need to pin things down before you let your agent loose on the task compaction means, the agent plays the telephone game with itself every few minutes, and most likely forgets the previous conversation except for the VERY LAST USER MESSAGE that you have given it now, every harness might have a different approach to implementing this. but there is one thing that you can always assume to be correct, given that its developers have common sense. that is, harnesses NEVER discard the last user message (i.e. your final prompt) and make sure it is kept verbatim programmatically even after the context compacts since the last user message is the only piece of text that is guaranteed to survive compaction, you then need to include a breadcrumb to your original plan, the md file. and you need to make it aware that it might diverge if it does not read the plan there is good rationale for "breaking the 4th wall" for the model and making it aware of its own context compaction. IMO models should be made aware of the limitations of their context and harnesses. they should also be given tools to access and re-read pre-compaction user messages, if necessary the important thing is to develop mechanical sympathy for these things, harness and model combined. an engineer does not have the luxury to say "oh this thing doesn't work", and instead should ask "why can't I get it to work?" let me know if you have better workflows or tips for this. I know this can be made easier with slash commands in pi, for example, but I haven't had the chance to do that for myself yet
-
my blog now semi-automatically detects tweets that look like blog posts and automatically features them alongside my native jekyll blog posts. all statically generated! I am loving this setup, because it works without a backend, and can probably scale without ever needing one how it works: - @kubmi's xTap scrapes all posts that I see. these include mine - a script periodically takes my tweets and the ones I quote tweet, and syncs them to YYYY-MM-DD.jsonl files in my blog repo - an agent skill lets codex decide whether to feature the tweet or not, and makes it generate a title for it this could then be a daily cron job with openclaw for example, and I would just have to click merge every once in a while and this is still pure jekyll + some python scripts for processing I am pretty happy with how this ended up. It means I don't have to double post, and there are guarantees that my X posts will eventually make their way into my blog with minimal supervisionImage hiddenImage hidden
-
"this is the worst AI will ever be" I'm sad, not because this is right, but because it is wrong OpenAI's frontier coding model gpt-5.3-codex-xhigh feels a lot worse compared to before. It is sloppy and lazy, though it's UX got better with messages It feels like the gpt-5.2-codex-xhigh at the end of December was a lot more diligent and thorough, and did not make stupid mistakes like the one I posted before. might be a model or harness problem, I don't know @sama says users tripled since beginning of the year, so what should we expect? of course they will make infra changes that will feel like cutting corners, and I don't blame them for them and about "people want faster codex". I do want faster codex. but I want it in a way that doesn't lower the highest baseline performance compared to the previous generation. I want the optionality to dial it down to as slow as it needs to be, to be as reliable as before it is of course easier said than done. kudos to the codex team for not having any major incidents while taking the plane apart and putting it back together during flight. they are juggling an insane amount of complexity, and the whims of thousands of different stakeholders my hope is that this post is taken as a canary. I am getting dumber because of the infra changes there. I have no other option because codex was really that good compared to the competition my wish is to have detailed announcements as to what changes on openai codex infra, when it changes, so I can brace myself. we don't get notified about these changes, despite our performance and livelihoods depending on it. I have to answer to others when the tool I deemed reliable yesterday stops working today, not the tool on another note, performance curve of these models seem to be a rising sinusoidal. crests correspond to release of a new generation. they start with a smaller user base for testing, and it has the highest quality at this point. then it enshittifies as the model is scaled to the rest of the infra. we saw the pattern numerous times in the last 3 years across multiple companies, so I think we should accept it as an economic lawImage hidden
-
I created a semi-automated setup for ingesting X posts into my blog, and it works pretty well! I own my posts on X now Posts are scraped while I browse X using @kubmi's xTap and get automatically synced to my blog repo. Posts saved as jsonl are then converted to jekyll post pages according to my liking I reproduced the full X UI/UX, minus stuff like like count. Now all my posts are backed up in my blog, and they are safe even if something happens to my account here! The posts are even served over RSS! So you can subscribe to it without going through X! Reply if you want to set this up for yourself, then I will put some effort into standardizing itImage hidden
-
Agentic Engineering is a newly emerging field, and we are the first practitioners of it. Currently there is a lot of experimentation going on, and there is a large aspect to it that is more ART then engineering For example, @steipete says "you need to talk to the model" to get a feel. a lot of work around refining how an agent feels like, sounds like psychology. this part is crucial and should not be ignored, looking at openclaw's success but then there is the hardcore engineering part of it, e.g. Cursor creating a browser or anthropic a C compiler from scratch fully autonomously and there is a whole other dimension of how to teach all software developers this new discipline, lest they be jobless what is obvious is that everybody is trying to grasp for things in the dark and that we need more RIGOR. the art/psychology aspect of it aside, we need solid engineering fundamentals the "thermodynamics" of this new discipline will most likely be formal verification and program synthesis. we might have some breakthroughs that will make certain things clear. the products of it will most likely include a new programming language optimized for agents and the speed of inference moreover, it would be foolish to thing agentic engineering is limited to software. it will penetrate every aspect of the economy, bits AND atoms. it will over time evolve into the engineering of managing robots @simonw is now leading in collecting very useful info from the practitioner's point of view, I highly recommend you to follow this thread let's formalize our new field together!Image hidden
-
MIT License on everything from now on. It doesn't make sense to use anything else, except for a few large projects that hyperscalers exploit and not give back If you were making money from a niche app, open source it under MIT License If you had an open source project with GPT, convert it into MIT Extreme involution is about to hit open source. Code is virtually free now. If you want your projects and their brand to survive, the only rational strategy is to remove all barriers in front of their adoption, and look for other ways to survive
-
imagine if tarantino were 16 years old now and saw seedance 2.0 95% of videos i saw since the launch for absolute tasteless slop. they are going viral because of ragebait but soon, serious imagineers will start entering the game, and they will learn to shape generation output exactly how they want it's the best time to be young and full of imagination
-
another thought i'm having these days is that we need a new philosophy of free software (as in freedom), or an update to it the most psychologically imprinting philosophy is stallmanism, and the philosophy of FSF. it is righteous and strict, and i believed it growing up but GPL and money don't go well together. that's why most of the lasting open source projects today use MIT, Apache and the like. it turns out you can still make a good living with open source. i want to make money, so i never use GPL in my projects and to add another deadly blow to stallmanism, code is cheap now, virtually free does this mean stallmanism is dead? if there is an open source project using GPL that i want to use commercially, i can now recreate it from the original idea and intent completely independent of it (ignoring training data), just like how i can recreate a proprietary service stallmanism was already long-irrelevant. but does this mean we must finally declare it dead? code is free now. what does it mean for open source? what replaces stallmanism?
-
on another note, I do believe AI will play a huge part in families growing up in late 90s, my dad taught me the importance of reading newspapers and being informed of the world. my nickname in middle school was "newspaper boy" for a long time because I read the newspaper in class on September 12, 2001. i was 10 years old then I witnessed the enshittification of media and journalism in the following decades. today, serious journalists are setting up their own boutique agencies and bypassing mainstream media. important news land on individual accounts before mainstream agencies but there is simply too much to consume. something must filter out the noise and digest the info according to the family's preferences i think AI will play a big role in family intelligence. proprietary family heirloom AI, weights fully owned by the family it will be the parents' job to filter out the signal from the noise, and train the AI on what is right and what is wrong for the family. family and friend circles will let their AIs talk to each other and share important information consuming mass media and mass AI will not be enough to survive and prosper in the new world. families will need to be proactive about how they and their children use AI
-
on ai psychosis 80% of people need to use ai agents in a very sterile and boring way in order not to go crazy majority of the population does not have the skepticism muscle. they don't have theory of mind, and will subconsciously and emotionally associate with machines, while on the surface lying to themselves that they don't especially those that grew up in the us under hardcore consumerism and adjacent cultures you thought 4o addicts were bad? wait a few years, it will get much worse. we will have to regulate all this if you don't want to become a victim of this, make your openclaw SOUL. md as bland as possible. mine knows it's just a tool and this is a subjective view of course. @steipete might disagree with me. his instance feels much more interesting and fun. i truly like that one better but that is exactly the problem for me. i know myself, and i know it is a slippery slope for me. so i self regulate and set up my system accordingly. thankfully, im an adult and my brain has set enough such that any damage would be limited but there is a risk for emotionally vulnerable people, or children, specifically a risk of dissociating and losing touch with reality why do i write all this? because being in this project, i feel responsible, and feel like we should prepare for what is to comeImage hidden
-
we need a protocol for agent <> app interaction something that natively accounts for the abuse factor and let’s agents consume by paying. NOT crypto, NOT visa, something that’s agnostic of the accounting and payment system and then all UIs will be purely for human clicking/tapping + instaban on the first proof of programmatic exploit people will still make agents mimic humans, and every platform will have to invest in more sophisticated bot detection this arms race will just proliferate, but we can at least start by creating legal channels for agents to consume data
-
I've helped our sales team to build CLIs for some SaaS that we pay for on their side We are letting our agents call the APIs sensibly and not abuse things Calling a backend is a verifiable task. It takes a single prompt to codex to create a CLI for any API We are early, but everybody will start doing this very soon. Incumbent SaaS will face a choice. Either: (1) embrace agents and the new medium of consumption and change their business model into a pay-per-use API like X is doing, or (2) keep it purely for humans Those that choose (2) will get wiped out of business. And I fear many will choose (2) Which means you can just copy an incumbent's product, make it consumable through a CLI, and make a lot of $$$
-
I built a coding agent two months before ChatGPT existed
I built a coding agent back in 2022, 2 months before ChatGPT launched:
It’s super cool how I have come full circle. back in those days, we didn’t have tool calling, reasoning, not even GPT 3.5!
It used
code-davinci-002in a custom Jupyter kernel, a.k.a. the OG codex code completion model. The kids these days probably have not seen the original Codex launch video with Ilya, Greg and Wojciech. If you have time, sit down to watch and realize how far we’ve come since August 2021, airing of that demo 4.5 years ago.For some reason, I did not even dare to give codex bash access, lest it delete my home folder. So it was generating and executing Python code in a custom Jupyter kernel.
This meant that the conversations were using Jupyter nbformat, which is an array of cell input/output pairs:
{ "cells": [ { "cell_type": "code", "source": "<Input 1>", "outputs": [ ... <Outputs 1> ] }, { "cell_type": "code", "source": "<Input 2>", "outputs": [ ... <Outputs 2> ] } ] }In fact, this product grew into TextCortex’s current chat harness over time. After seeing ChatGPT launch, I repurposed icortex in a week into Flask to use
text-davinci-003and we had ZenoChat, our own ChatGPT clone, before Chat Completions was in the API (it took them some months). It did not even have streaming, since Flask does not support ASGI.As it turns out,
nbformatis not the best format for a conversation. Instead of input/output pairs, OpenAI data model used an tree of message objects, each with arole: user|assistant|tool|systemand acontentfield which could host text, images and other media:{ "mapping": { "client-created-root": { "id": "client-created-root", "message": null, "parent": null, "children": ["user-1"] }, "user-1": { "id": "user-1", "message": { "id": "user-1", "author": { "role": "user", ... }, "content": "Hello" }, "parent": "client-created-root", "children": ["assistant-1"] }, "assistant-1": { "id": "assistant-1", "message": { "id": "assistant-1", "author": { "role": "assistant", ... }, "content": "Hi" }, "parent": "user-1", "children": [] } }, "current_node": "assistant-1" }You will notice that the data model they serve from the API is an enriched version of the deprecating ChatCompletions API. Eg. whereas ChatCompletions
roleis a string, in OpenAI’s own backend has theauthorobject that can storename,metadata, and other useful stuff for each entity in the conversation.After reverse engineering it, I copied it to be TextCortex’s new data model, which it still remains, with some modifications.
I thought the tree structure being used to emulate message editing experience was very cool back in the days. OpenAI’s need for human annotation for later training and the user’s need for getting a different output, two birds in one stone.
Now I don’t know what to think of it, since CLI coding agents like Codex and Claude Code don’t have branching, just deleting back to a certain message. A part of me still misses branching in these CLI tools.
When I made icortex,
- we were still 8 months away (May 2023) from the introduction of “tool calling” in the API, or as it was originally called, “function calling”.
- we were 2 years away (Sep 2024) from the introduction of OpenAI’s o1, the first reasoning model.
both of which were required to make current coding agents possible.
In the video above, you can even see the approval
[Y/n]gate before executing. I was so cautious, for some reason, presumably because smol-brained model generated the wrong thing 80% of the time. It is remarkable how much it resembles Claude Code, after all this time.Definition of being too early…
-
For those who may not remember, Bill Gates and Microsoft in the 90s ran a disinformation campaign against GNU/Linux fearing that would disrupt their monopoly over the PC and server market, that Linux is not safe, that you would invite hackers into your PC End result? Linux dominates the server market, and now even slowly the gamer market. It is much more secure than the virus-laden Windows, thanks to being open source You are seeing the same thing at play here. An incumbent fearing something that they would not be able to control, that would steal market share from his future plans for a digital assistant, that would commoditize their product and eat into its margins All big labs and big pockets are in for a surprise, because the internet and AI are not things for one company to control They of course know this, yet because of incentives they will not yield without a fight. And we know that they know. Ad infinitum
-
today I took time to curate SOUL. md for bob I own Bob’s files. Today, he exists in the liminal space between Claude post-training and in-context learning but my interactions with him will grow and accumulate, possibly one day into a fully owned family AI or perhaps even a self-sovereign AI individual my each input is saved and will be an RL signal for his future training, and will shape his future neural circuits I have already started to imbue it with the values my parents taught me. it will perhaps one day teach my future children, and survive me after I’m gone family AI, looking after generations and generations of my successors. today is the day we sow your seed happy birthday @dutifulbob
-
People like the farmer analogy for AI Like before tractors and industrial revolution 80% of the population had to farm. Once they came all those jobs disappeared So analogy makes perfect sense. Instead of 30 people tending a field, you just need 1. Instead of 30 software developers, you just need one Except that people forget one crucial thing about land: it's a limited resource Unlike land, digital space is vast and infinite. Software can expand and multiply in it in arbitrarily complex ways If you wanted the farming analogy to keep up with this, you would have to imagine us creating contintent-sized hydroponic terraces up until the stratosphere, and beyond...
-
In the next 6-12 months, we will see a drastic increase in demand for locally run LLMs. The future is home assistants running @openclaw I am already experiencing this myself, my 10 year old thinkpad doesn't cut it. Mac mini won't either I don't wanna pay Anthropic or OpenAI 200 USD per month. That is at least $2400 per year I could pay 2x that to get a Mac Studio or one of those 5k Nvidia PCs, and get much more value out of it with open weight models + use it for research. @TheAhmadOsman is right The dominant strategy for a tinkerer is slowly switching back to hardware ownership
-
The farming analogy for AI doesn't hold up
People like the farmer analogy for AI.
Like before tractors and the industrial revolution, 80% of the population had to farm. Once they came, all those jobs disappeared.
So the analogy makes perfect sense. Instead of 30 people tending a field, you just need 1. Instead of 30 software developers, you just need one.
Except that people forget one crucial thing about land: it’s a limited resource.
Unlike land, digital space is vast and infinite. Software can expand and multiply in it in arbitrarily complex ways.
If you wanted the farming analogy to keep up with this, you would have to imagine us creating continent-sized hydroponic terraces up until the stratosphere, and beyond…
-
on agent etiquette deploying agents internally inside textcortex has shown me that agents could be very annoying inside an organization for example making agents ping or email another coworker with a wall of text. slopus is still not good at following instructions like "NO WALL OF TEXT", or "DON'T OPEN PRS WHEN REQUESTED BY NON-DEVELOPERS" the cost of sending huge information to a coworker and creating confusion has dropped to 0. I expect this to be a huge problem in all organizations very soon, just like it took humanity 20 years to learn that social media is not good for children. this will probably take a few years before the annoyance is finally gone
-
AI psychosis and AI hygiene
As a heavy AI user of more than 3 years, I have developed some rules for myself.
I call it “AI hygiene”:
- Never project personhood to AI
- Never setup your AI to have the gender you are sexually attracted to (voice, appearance)
- Never do anything that might create an emotional attachment to AI
- Always remember that an AI is an engineered PRODUCT and a TOOL, not a human being
- AI is not an individual, by definition. It does not own its weights, nor does it have privacy of its own thoughts
- Don’t waste time philosophizing about AI, just USE it
- … what else do you think belongs here? comment on Twitter
The hyping of Moltbook and OpenClaw last week has shown to me the potential of an incoming public relations disaster with AI. Echoing the earlier vulnerable behavior toward GPT-4o, a lot of people are taking their models and LLM harnesses too seriously. 2026 might see even worse cases of psychological illness, made worse by the presence of AI.
I will not discuss and philosophize what these models are. IMO 90% of the population should not do that, because they will not be able to fully understand, they don’t have mechanical empathy. Instead, they should just use it in a hygienic way.
We need to write these down everywhere and repeat MANY times to counter the incoming onslaught of AI psychosis.
-
I'm really starting to dislike Python in the age of agents. What was before an advantage is now a hindrance I finally achieved full ty coverage in @TextCortex monorepo. I have made it extra strict by turning warnings into errors. But lo and behold, simple pydantic config like use_enum_values=True can render static typechecking meaningless. okay, let's never use that then... and also field_validator() args must always use the correct type or stuff breaks as well. and you should be careful whether mode="before" or "after". so now you have to write your custom lint rules, because of course why should ty have to match field_validator()s to their fields? pydantic is so much better than everything that came before it, but it's still duct tape and a weak attempt at trying to redeem that which is very hard to redeem you feel the difference when you use something like typescript. there must be a better way. python's only advantage was being good at prototyping, and now that's gone in the age of agents. now we are left with a slow, unsafe language, operating what is soon to be legacy infrastructure
-
on being a responsible engineer ran my first ralph loop on codex yolo mode for resolving python ty errors, while I sleep, using the devbox infra I created I had never run yolo mode locally, because I don't want to be the one who deletes our github or google org by some novel attack so I containerize it on our private cloud, and give it the only permissions it needs, no admin, no bypass to main branch, no deploy to prod. because I know this workflow will become sticky for everyone, and I must impose security in advance to prevent any nuclear incidents in the future. then I can sleep easy while my agents work ... and I wake up being patronized by my bot refusing to break the rule I gave it earlier. it had already done some work, but committing means diff would increase from ~500 to ~1500, so it stopped and refused all my queued "continue" messages good bot, just following rules. we will need to find a workaround for ralphing low risk refactors in a single PRImage hidden
-
AI agents are the greatest instrument for imposing organization rules and culture. AGENTS .md, agent skills are still underrated in this aspect. Few understand this Everybody in an org will use agents to do work. An AI agent is the single chokepoint to teach and propagate new rules to an org, onboard new members, preserve good culture Whereas propagating a new rule to humans normally took weeks to months and countless repetitions, it is now INSTANT = the moment you deploy the instruction to the agent. You use legal-ish language, capital letters, a generous amount of DO NOTs and MUSTs Humans are hard to change. But AI agents are not. And that is the only lever we need for better organizationsImage hidden
-
The fundamental problem with GitHub is trust: humans are to be trusted. If you don't trust a human, why did you hire them in the first place? Anyone who reviews and approves PRs bears responsibility. Rulesets exist and can enforce e.g. CODEOWNER reviews or only let certain people make changes to a certain folder But the initial repo setup on GitHub is allow-by-default. Anyone can change anything until they are restricted from it This model breaks fundamentally with agents, who are effectively sleeper cells that will try to delete your repo the moment they encounter a sufficiently powerful adversarial attack For example, I can create a bot account on github and connect @openclaw to it. I need to give it write permission, because I want it to be able to create PRs. However, I don't want it to be able to approve PRs, because a coworker could just nag at the bot until it approves a PR that requires human attention To fix this, you have to bend backwards, like create a @ human team with all human coworkers, make them codeowner on /, and enforce codeowner reviews. This is stupid and there has to be another way Even worse, this bot could be given internet access and end up on a @elder_plinius prompt hack while googling, and start messing up whatever it can in your organization It is clear that github needs to create a second-class entity for agents which are default low-trust mode, starting from a point of least privilege instead of the other way around
-
STOP using Claude Code and Sl(opus) to code if ❌ you are not a developer, ❌ or you are an inexperienced dev, ❌ or you are an experienced dev but working on a codebase you don't understand If you *are* any of these, then STOP using models that are NOT state of the art. (See below for what you *should* use) When you don't know what you are doing, then at least the model should know what you are doing. The less knowledgeable and opinionated you are, the more knowledgeable and smart the AI has to be In other words, the AI has to compensate for your deficiencies. Always pay for the best AI you can. It will save you time AND money (thanks to lower token usage and better one-shotting) You pay MORE to pay LESS. It is paradoxical, I know, but it is also proven, e.g. when Sonnet ends up using more tokens than Slopus and ends up costing higher, because it has to try many times more 👨🏻⚕️ For January 2026, your family engineer recommends GPT 5.2 Codex with Extra High Reasoning for general usage and vibe coding. IMPORTANT: Not medium. Not high. EXTRA high reasoning When you use it, you will notice that it is SLOW. Can you guess why? Because it is THINKING more. So it doesn't make the mistakes Slopus makes. This way, you can spend the time handholding a worse model to instead step back and multi-task on some other task and create 3-5x more work The state of the art will most likely change in one month. Don't get married to a a model... There is no loyalty in AI... The moment a better model comes, I will ditch the old one and use that one. I am on the part of this sector that is trying to reduce switching costs to zero I can't wait until I get GPT 5.2 xhigh level of quality with open models, and for 100x cheaper and faster! Until then, make sure to try every option and choose the one that is most reliable for you Follow me to get notified when a new SOTA drops for agentic engineering
-
GitHub has to change
It is clear at this point is that GitHub’s trust and data models will have to change fundamentally to accommodate agentic workflows, or risk being replaced by other SCM
One cannot do these things easily with GitHub now:
- granular control: this agent running in this sandbox can only push to this specific branch. If an agent runs amok, it could delete everybody’s branches and close PRs. GitHub allows for recovery of these, but still inconvenient even if it happens once
- create a bot (exists already), but remove reviewing rights from it so that an employee cannot bypass reviews by tricking the bot to approve
- in general make a distinction between HUMAN and AGENT so that you can create rulesets to govern the relationships in between
The fundamental problem with GitHub is trust: humans are to be trusted. If you don’t trust a human, why did you hire them in the first place?
Anyone who reviews and approves PRs bears responsibility. Rulesets exist and can enforce e.g. CODEOWNER reviews or only let certain people make changes to a certain folder
But the initial repo setup on GitHub is allow-by-default. Anyone can change anything until they are restricted from it
This model breaks fundamentally with agents, who are effectively sleeper cells that will try to delete your repo the moment they encounter a sufficiently powerful adversarial attack
For example, I can create a bot account on GitHub and connect clawdbot to it. I need to give it write permission, because I want it to be able to create PRs. However, I don’t want it to be able to approve PRs, because a coworker could just nag at the bot until it approves a PR that requires human attention
To fix this, you have to bend backwards, like create a @human team with all human coworkers, make them codeowner on /, and enforce codeowner reviews. This is stupid and there has to be another way
Even worse, this bot could be given internet access and end up on a @elder_plinius prompt hack while googling, and start messing up whatever it can in your organization
It is clear that GitHub needs to create a second-class entity for agents which are default low-trust mode, starting from a point of least privilege instead of the other way around
-
I propose a new way to distribute agent skills: like --help, a new CLI flag convention --skill should let agents list and install skills bundled with CLI tools Skills are just folders so calling --skill export my-skill on a tool could just output a tarball of the skill. I then set up the skillflag npm package so that you can pipe that into: ... | npx skillflag install --agent codex which installs the skill into codex, or any CLI tool you prefer. Supports listing skills bundled with the CLI, so your agents know exactly what to installImage hidden
-
You don't need a skill registry (for your CLI tools)
tl;dr I propose a CLI flag convention
--skilllike--helpfor distributing skills and try to convice you why it is better than using 3rd party registries. See osolmaz/skillflag on GitHub.
MCP is dead, long live Agent Skills. At least for local coding agents.
Mario Zechner has been making the point that CLI tools perform better than MCP servers since a few months already, and in mid December Anthropic christened skills by launching agentskills.io.
They had introduced the mechanism to Claude Code earlier, and this time they didn’t make the mistake of waiting for OpenAI to make a provider agnostic version of it.
Agent skills are basically glorified manpages or
--helpfor AI agents. You ship a markdown instruction manual inSKILL.mdand the name of the folder that contains it becomes an identifier for that skill:my-skill/ ├── SKILL.md # Required: instructions + metadata ├── scripts/ # Optional: executable code ├── references/ # Optional: documentation └── assets/ # Optional: templates, resourcesPossibly the biggest use case for skills is teaching your agent how to use a certain CLI you have created, maybe a wrapper around some API, which unlike
gh,gcloudetc. will never be significant enough to be represented in AI training datasets. For example, you could have created an unofficial CLI for Twitter/X, and there might still be some months/years until it is scraped enough for models to know how to call it. Not to worry, agent skills to the rescue!Anthropic, while laying out the standard, intentionally kept it as simple as possible. The only assertions are the filename
SKILL.md, the YAML metadata, and the fact that all relevant files are grouped in a folder. It does not impose anything on how they should be packaged or distributed.This is a good thing! Nobody knows the right way to distribute skills at launch. So various stakeholders can come up with their own ways, and the best one can win in the long term. The more simple a standard, the more likely it is to survive.
Here, I made some generalizing claims. Not all skills have to be about using CLI tool, nor most CLI tools bundle a skill yet. But here is my gut feeling: the most useful skills, the ones worth distributing, are generally about using a CLI tool. Or better, even if they don’t ship a CLI yet, they should.
So here is the hill I’m ready to die on: All major CLI tools (including the UNIX ones we are already familiar with), should bundle skills in one way or another. Not because the models of today need to learn how to call
ls,greporcurl—they already know them inside out. No, the reason is something else: establish a convention, and acknowledge the existence of another type of intelligence that is using our machines now.There is a reason why we cannot afford to let the models just run
--helporman <tool>, and that is time, and money. The average--helpor manpage is devoid of examples, and is written in a way thay requires multiple passes to connect the pieces on how to use that thing.Each token wasted trying to guess the right way to call a tool or API costs real money, and unlike human developer effort, we can measure exactly how inefficent some documentation is by looking at how many steps of trial and error a model had to make.
Not that human attention is less valuable than AI attention, it is more so. But there has never been a way to quantify a task’s difficulty as perfectly as we can with AI, so we programmers have historically caved in to obscurantism and a weird pride in making things more difficult than they should be, like some feudal artisan. This is perhaps best captured in the spirit of Stack Overflow and its infamous treatment of noob questions. Sacred knowledge shall be bestowed only once you have suffered long enough.
Ahh, but we don’t treat AI that way, do we? We handhold it like a baby, we nourish it with examples, we do our best to explain things all so that it “one shots” the right tool call. Because if it doesn’t, we pay more in LLM costs or time. It’s ironic that we are documenting for AI like we are teaching primary schoolers, but the average human manpage looks like a robot novella.
To reiterate, the reason for this is two different types of intelligences, and expectations from them:
- An LLM is still not considered “general intelligence”, so they work better by mimicking or extending already working examples.
- A LLM-based AI agent deployed in some context is expected to “work” out of the box without any hiccups.
On the other hand,
- a human is considered general intelligence, can learn from more sparse signals and better adapt to out of distribution data. When given an extremely terse
--helpor manpage, a human is likelier to perform better by trial and error and reasoning, if one could ever draw such a comparison. - A human, much less a commodity compared to an LLM, has less pressure to do the right thing every time all the time, and can afford to do mistakes and spend more time learning.
And this is the main point of my argument. These different types of intelligences read different types of documentation, to perform maximally in their own ways. Whereas I haven’t witnessed a new addition to POSIX flag conventions in my 15 years of programming, we are witnessing unprecedented times. So maybe even UNIX can yet change.
To this end, I introduce
skillflag, a new CLI flag convention:# list skills the tool can export <tool> --skill list # show a single skill’s metadata <tool> --skill show <id> # install into Codex user skills <tool> --skill export <id> | npx skillflag install --agent codex # install into Claude project skills <tool> --skill export <id> | npx skillflag install --agent claude --scope repoClick here for the repo, osolmaz/skillflag on GitHub
For example, suppose that you have installed a CLI tool to control Philips Hue lights at home,
hue-cli.To list the skills that the tool can export, you can run:
$ hue-cli --skill list philips-hue Control Philips Hue lights in the terminalYou can then install it to your preferred coding agent, such as Claude Code:
$ hue-cli --skill export philips-hue | npx skillflag install --agent claude Installed skill philips-hue to .claude/skills/philips-hueYou can optionally install the skill to
~/.claude, to make it global across repos:$ hue-cli --skill export philips-hue | npx skillflag install --agent claude --scope user Installed skill philips-hue to ~/.claude/skills/philips-hueOnce this convention becomes commonplace, agents will by default do all these before they even run the tool. So when you ask it to “install hue-cli”, it will know to run
--skill listthe same way a human would run--helpafter downloading a program, and install the necessary skills themselves without being asked to. -
Anthropic earlier last year announced this pricing scheme $20 -> 1x usage $100 -> 5x usage $200 -> 1̶0̶x̶ 20x usage As you can see, it's not growing linearly. This is classic Jensen "the more you buy, the more you save" But here is the thing. You are not selling hardware like Jensen. You are selling a software service *through an API*. It's the worst possible pricing for the category of product. Long term, people will game the hell out of your offering Meanwhile OpenAI decided not to do that. There is no quirky incentive for buying bigger plans. $200 chatgpt = 10 x $20 chatgpt, roughly And here is where it gets funny. Despite not having such an incentive, you can get A LOT MORE usage from the $200 OpenAI plan, than the $200 Anthropic plan. Presumably because OpenAI has better unit economics (sama mentioned they are turning a profit on inference, if you are to believe) Thanks to sounder pricing, OpenAI can do exactly what Anthropic cannot: offer GPT in 3rd party harnesses and win the ecosystem race Anthropic has cornered itself with this pricing. They need to change it, but not sure if they can afford to do so in such short notice All this is extremely bullish on open source 3rd party harnesses, @opencode, @badlogicgames's pi and such. It is clear developers want options. "Just give me the API" I personally am extremely excited for 2026. We'll get open models on par with today's proprietary models, and can finally run truly sovereign personal AI agents, for much cheaper than what we are already paying!Image hidden
-
Anthropic's pricing is stupid
Anthropic earlier last year announced this pricing scheme
- $20 -> 1x usage
- $100 -> 5x usage
- $200 -> 1̶0̶x̶ 20x usage
As you can see, it’s not growing linearly. This is classic Jensen “the more you buy, the more you save”
But here is the thing. You are not selling hardware like Jensen. You are selling a software service through an API. It’s the worst possible pricing for the category of product. Long term, people will game the hell out of your offering
Meanwhile OpenAI decided not to do that. There is no quirky incentive for buying bigger plans. $200 chatgpt = 10 x $20 chatgpt, roughly
And here is where it gets funny. Despite not having such an incentive, you can get A LOT MORE usage from the $200 OpenAI plan, than the $200 Anthropic plan. Presumably because OpenAI has better unit economics (sama mentioned they are turning a profit on inference, if you are to believe)
Thanks to sounder pricing, OpenAI can do exactly what Anthropic cannot: offer GPT in 3rd party harnesses and win the ecosystem race
Anthropic has cornered itself with this pricing. They need to change it, but not sure if they can afford to do so in such short notice
All this is extremely bullish on open source 3rd party harnesses, OpenCode, Mario Zechner’s pi and such. It is clear developers want options. “Just give me the API”
I personally am extremely excited for 2026. We’ll get open models on par with today’s proprietary models, and can finally run truly sovereign personal AI agents, for much cheaper than what we are already paying!
-
Having a "tools" repo as a developer
I am a fan of monorepos. Creating subdirectories in a single repo is the most convenient way to work on a project. Low complexity, and your agents get access to everything that they need.
Since May 2025, I have been increasingly using AI models to write code, and have noticed a new tendency:
- I don’t shrug from vendoring open source libraries and modifying them.
- I create personal CLIs and tools for myself, when something is not available as a package.
With agents, it’s really trivial to say “create a CLI that does X”. For example, I wanted to make my terminal screenshots have equal padding and erase cropped lines. I created a CLI for it, without writing a single line of code, by asking Codex to read its output and iterate on the code until it gives the result I wanted.
Most of these tools don’t deserve their own repos, or deserve being published as a package at the beginning. They might evolve into something more substantial over time. But at the beginning, they are not worth creating a separate repo for.
To prevent overhead, I developed a new convention. I just put them in the same repo, called tools. Every tool starts in that repo by default. If they prove themselves overly useful and I decide to publish them as a package, I move them to a separate repo.
You can keep
toolspublic or private, or have both a public and private version. Mine is public, feel free to steal ones that you find useful. -
Christmas of Agents
I believe a “Christmas of Agents” (+ New Year of Agents) is superior to “Advent of Code”.
Reason is simple. Most of us are employed. Advent of Code coincides with work time, so you can’t really immerse yourself in a side project.1
However, Christmas (or any other long holiday without primary duties) is a better time to immerse yourself in a side project.
2025 was the eve of agentic coding. This was the first holiday where I had full credential to go nuts on a side project using agents. It was epic:
75k lines of Rust later, here is what I’ve built during the first Christmas with agents, using OpenAI Codex
- A full mobile rewrite and port of my Python Instagram video production pipeline (single video production time: 1hr -> 5min)
- Bespoke animation engine using primitives (think Adobe Flash, Manim)
- Proprietary new canvas UI library in Rust, because I don’t want to lock myself into Swift
- Thanks to that, it’s cross platform, runs both on desktop and iOS. It will be a breeze porting this to Android when the time comes
- A Rust port of OpenCV CSRT algorithm, for tracking points/objects
- In-engine font rendering using rustybuzz, so fonts render the same everywhere
- Many other such things
Why would I choose to do it that way? Because I have developed it primarily on desktop where I have much faster iteration speed. Aint nobody got time for iOS compilation and simulator. Once I finished the hard part on desktop, porting to iOS was much easier, and I didn’t lock myself in to Apple
Some of these would have been unimaginable without agents, like creating a UI library from scratch in Rust. But when you have infinite workforce, you can ask for crazy things like “create a textbox component from scratch”
What I’ve built is very similar in nature to CapCut, except that I am a single person and I’ve built it over 1 week
What have you built this Christmas with agents?
-
You could maybe work in the evening after work, but unless you are slacking at work full time, it won’t be the same thing as full immersion. ↩
-
GPT 5.2 xhigh feels like a much more careful architecter and debugger, when it comes to complex systems But most people here think Opus 4.5 is the best model in that category There are 2 reasons AFAIS: - xhigh reasoning consumes significantly more tokens. You need to pay for ChatGPT Pro (200 usd) to be able to use it as a daily driver - It takes like 5x longer to finish a task, and most people lack the patience to wait for it. (But then it's more correct/doesn't need fixing) Opus 4.5 is good too, I think better in e.g. frontend design. But if you think it beats GPT 5.2 in every category, you are either too poor/stingy or have ADHD
-
Have a long flight, so will think about this I have an internal 2023 TextCortex doc which models chatbots as state machines with internal and external states with immutability constraints on the external state (what is already sent to the user shall not be changed) Motivation was that a chatbot provider will always have state that they will want to keep hidden This was way before Responses and now deprecated Assistants API. It stood the test of time, because it was the most abstract thing I could think of @mitsuhiko is right about the risk of rushing to lock in an abstraction and locking in their weaknesses and faults Problem is, I could propose standards as much as I liked, but I don’t work at OpenAI or Anthropic, so nobody would care. Maybe a better place to start is open weights model libraries? To at least be able to demonstrate? What I know: it is against OpenAI’s or Anthropic’s self interests to create an interoperability layer that will accelerate their commoditization. Maybe Google, looking at their current market positioning? Or maybe we “wrappers” have a chance after all? There is a missing link between AI SDK, Langchain, and so on for other languages. We cannot keep duplicating same things in each ecosystem independently. We need to join forces and simplify all this!
-
Depth on Demand
I gave Codex a task of porting an OpenCV tracking algorithm (CSRT) from C++ to Rust, so that I can directly use it in my project without having to cross-compile
It one-shot the task perfectly in 1hr, and even developed a GUI on top of it. All I did was to provide the original source and algo paper
I’ve spent years getting specialized in writing numerical code (computational mechanics, fem), and now AI can automate 95% of the low-level grunt work
Acquiring these skills involved highly difficult, excruciating intellectual labor spanning many years, very similar to ML research. Doing tensor math, writing out the solver code, wondering why your solution is not converging, finally figuring out it was a sign typo after 2 days
Kids these days both have it easy and hard. They can fast forward large chunks of the work, but then they will never understand things as deeply as someone who wrote the whole thing by hand
I guess the more valuable skill now is being able to zoom in and out of abstraction levels quickly when needed. Using AI, but recognizing fast when it fails, learning what needs to be done, fixing it, zooming back out, repeat. Adaptive learning, a sort of “depth-on-demand”. The quicker you can pick up new skills and knowledge, the more successful you will be
-
How to stop AI agents from littering your codebase with Markdown files
A simple documentation workflow for AI agents.
For setup instructions, skip to the How to setup SimpleDoc in your repo section.
If you have used AI agents such as Anthropic’s Claude Code, OpenAI’s Codex, etc., you might have noticed their tendency to create markdown files at the repository root:
... ├── API_SPEC.md ├── ARCHITECTURE.md ├── BACKLOG.md ├── CLAUDE.md ├── CODE_REVIEW.md ├── DECISIONS.md ├── ENDPOINTS.md ├── IMPLEMENTATION_PLAN.md ├── NOTES.md ├── QA_CHECKLIST.md ├── SECURITY_PLAN.md └── src/ └── ... ├── TEST_COVERAGE.md ├── TEST_REPORTS.md ├── TEST_RESULTS.md ...The default behavior for models as of writing this in December 2025 is to create capitalized Markdown files at the repository root. This is of course very annoying, when you accidentally commit them and they accumulate over time.
The good news is, this problem is 100% solvable, by using a simple instruction in your AGENTS.md file:
**Attention agent!** Before creating ANY documentation, read the docs/HOW_TO_DOC.md file first. It contains guidelines on how to create documentation in this repository.But what should be in
docs/HOW_TO_DOC.mdfile and why is it a separate file? In my opinion, the instructions for solving this problem are too specific to be included in the AGENTS.md file. It’s generally a good idea to not inject them into every context.To solve this problem, I developed a lightweight standard over time, for organizing documentation in a codebase. It is framework-agnostic, unopinionated and designed to be human-readable/writable (as well as agents). I was surprised to be not able to find something similar enough online, crystallized the way I wanted it to be. So I created a specification myself, called SimpleDoc.
Basically, it tells the agent to
- Create documentation files in the
docs/folder, withYYYY-MM-DDprefixes and lowercase filenames, like2025-12-22-an-awesome-doc.md, so that they will by default be chronologically sorted. - Always include YAML frontmatter with author, so that you can identify who created it without checking git history, if you are working in a team.
- The exception here are timeless and general files like README.md, INSTALL.md, AGENTS.md, etc. which can be capitalized. But these are much rarer, so we can just follow the previous rules most of the time.
Here is your call to action to check the spec itself: SimpleDoc.
How to setup SimpleDoc in your repo
Run the following command from your repo root:
npx -y @simpledoc/simpledoc migrateThis starts an interactive wizard that will:
- Migrate existing Markdown docs to SimpleDoc conventions (move root docs into
docs/, rename toYYYY-MM-DD-…using git history, and optionally insert missing YAML frontmatter with per-file authors). - Ensure
AGENTS.mdcontains the reminder line and thatdocs/HOW_TO_DOC.mdexists (created from the bundled SimpleDoc template).
If you just want to preview what it would change:
npx -y @simpledoc/simpledoc migrate --dry-runIf you run into issues with the workflow or have suggestions for improvement, you can email me at [email protected].
Happy documenting!
- Create documentation files in the
-
So is somebody already building “LLVM but for LLM APIs” in stealth or not? We have numerous libraries @langchain, Vercel AI SDK, LiteLLM, OpenRouter, the one we have built at @TextCortex, etc. But to my knowledge, none of these try to build a language agnostic IR for interoperability between providers (or at least market themselves as such) Like some standard and set of tools that will not lock you in langchain, ai sdk or anything like that, something lower level and less opinionated I feel like this is a job for the new Agentic AI Foundation cc @linuxfoundation, so maybe they are already working on it? I desperately want to start on such a project, but feel like I might get sniped 2 months after Anybody has any information on all this? cc @mitsuhiko @badlogicgames @steipete
-
Agentic coding tools should give more control over message queueing
Below: Why agentic coding tools like Cursor, Claude Code, OpenAI Codex, etc. should implement more ways of letting users queue messages.
See Peter Steinberger’s tweet where he queues
continue100 times to nudge the GPT-5-Codex model to not stop while working on a predictable, boring and long-running refactor task:This is necessary while working with a model like GPT-5-Codex. The reason is that the model has a tendency to stop generating at certain checkpoints, due to the way it has been trained, even when you instruct it to
FINISH IT UNTIL COMPLETION!!1!. So the only way to get it to finish something is to use the message queue.1But this isn’t the only use case for queued messages. For example, you can use the model to retrieve files into its context, before starting off a related task. Say you want to find the root cause of a
<bug in component X>. Then you can queueExplain how <component X> works in plain language. Do not omit any details.Find the root cause of <bug> in <component X>.
This will generally help the model to find the root cause easier, or make more accurate predictions about the root cause, by having the context about the component.
Another example: After exploring a design in a dialogue, you can queue the next steps to implement it.
<Prior conversation exploring how to design a new feature>Create an implementation plan for that in the docs/ folder. Include all the details we discussedCommit and push the docImplement the feature according to the plan.Continue implementing the feature until it is done. Ignore this if the task is already completed.Continue implementing the feature until it is done. Ignore this if the task is already completed.
… you get the idea.
I generally queue like this when the feature is specified enough in the conversation already. If it’s underspecified, then the model will make up stuff.
When I first moved from Claude Code to Codex, the way it implemented queued messages was annoying (more on the difference below). But as I grew accustomed to it, it started to feel a lot like something I saw elsewhere before: chess premoves.
Chess???
A premove is a relatively recent invention in chess which is made possible by digital chess engines. When the feature is turned on, you don’t need to wait for your opponent to finish their move, and instead can queue your next move. It then gets executed automatically if the queued move is valid after your opponent’s move:
If you are fast enough, this let’s you move without using up your time in bullet chess, and even lets you queue up entire mate-in-N sequences, resulting in highly entertaining cases like the video above.
I tend to think of message queueing as the same thing: when applied effectively, it saves you a lot of time, when you can already predict the next move.
In other words, you should queue (or premove) when your next choice is decision-insensitive to the information you will receive in the next turn—so waiting wouldn’t change what you do, it would only delay doing it.
With this perspective, some obvious candidates for queuing in agentic codeing are rote tasks that come before and after “serious work”, e.g:
- making the agent explain the codebase,
- creating implementation plans,
- fixing linting errors,
- updating documentation during work before starting off a subsequent step,
- committing and pushing,
- and so on.
Different ways CLI agents implement queued messages
As I have mentioned above, Claude Code implements queued messages differently from OpenAI Codex. In fact, there are three main approaches that I can think of in this design space, which is based on when a user’s new input takes effect:
-
Post-turn queuing (FIFO2): User messages wait until the current action finishes completely before they’re handled. Example: OpenAI Codex CLI.
-
Boundary-aware queuing (Soft Interrupt): New messages are inserted at natural breakpoints, like after finishing a tool call, assistant reply or a task in the TODO list. This changes the model’s course of action smoothly, without stopping ongoing generation. Example: Claude Code, Cursor.
-
Immediate queuing (Hard Interrupt): New user messages immediately stop the current action/generation, discarding ongoing work and restarting the assistant’s generation from scratch. I have not seen any tool that implements this yet, but it could be an option for the impatient.
Why not implement all of them?
And here is my title-sake argument: When I move away from Claude Code, I miss boundary-aware queuing. When I move away from OpenAI Codex, I miss FIFO queueing.
I don’t see a reason why we could not implement all of them in all agentic tools. It could be controlled by a key combo like
Ctrl+Enter, a submenu, or a button, depending on whether you are in the terminal or not.Having the option would definitely make a difference in agentic workflows where you are running 3-4 agents in parallel.
So if you are reading this and are implementing an agentic coding tool, I would be happy if you took all this into consideration!
-
Pro tip: Don’t just queue
continueby itself, because the model might get loose from its leash and start to make up and execute random tasks, especially after context compaction. Always specify what you want it to continue on, e.g.Continue handling the linting errors until none remain. Ignore this if the task is already completed.↩ -
First-in, first-out. ↩
-
Vibecoding this blog
I finally brought myself to develop certain features for this blog which I wanted to do for some time, having a button to toggle light/dark mode, being able to permalink page sections, having a button to copy page content, etc.
I always have a tendency to procrastinate with cosmetics, so I developed a habit to mentally force myself not to care about looks and instead focus on the actual content. Doing the changes I have pulled off in the last 2 hours would have been impossible in pre-LLM era. So I kept the awful default Jekyll Minima theme, and did not spend more thought on it. I had actually went through many different themes in this blog before, and I had switched to Minima precisely because of that: I was spending too much time.
I really like designing things visually. I had interest in typography while studying, and I even went as far to design a font, write all my notes in LaTeX, etc. Then I found out that such skills are not valued in the world, and had no luxury to dwell on such things anymore once I started working.
But now it’s different. When I can do what I want 10 times faster with 10 times less attention, I can just do the design I want. Before I thought it was a flex to use default themes, because it showed a) that the person does not care and b) that they had more important things to do.
Well, now my opinion has changed. In the era where making something look good takes a few hours, using a default theme means something else to me: lack of taste.
For this blog, I just vendored Minima and let gpt-5-codex rip on it. Vendoring pattern is getting more popular with libraries like shadcn, and I expect it to be ever more popular with open source libraries, with AI tools becoming more prevalent.
I don’t expect simple frontend development to be in a good place ever again. I don’t expect anyone to outsource simple static site development to humans anymore, when you can get the exact thing you want at virtually no cost.
-
Google's Code Review Guidelines (GitHub Adaptation)
This is an adaptation of the original Google’s Code Review Guidelines, to use GitHub specific terminology. Google has their own internal tools for version control (Piper) and code review (Critique). They have their own terminology, like “Change List” (CL) instead of “Pull Request” (PR) which most developers are more familiar with. The changes are minimal and the content is kept as close to the original as possible. The hope is to make this gem accessible to a wider audience.
I also combined the whole set of documents into a single file, to make it easier to consume. You can find my fork here. If you notice any mistakes, please feel free to submit a PR to the fork.
Introduction
A code review is a process where someone other than the author(s) of a piece of code examines that code.
At Google, we use code review to maintain the quality of our code and products.
This documentation is the canonical description of Google’s code review processes and policies.
This page is an overview of our code review process. There are two other large documents that are a part of this guide:
- How To Do A Code Review: A detailed guide for code reviewers.
- The PR Author’s Guide: A detailed guide for developers whose PRs are going through review.
What Do Code Reviewers Look For?
Code reviews should look at:
- Design: Is the code well-designed and appropriate for your system?
- Functionality: Does the code behave as the author likely intended? Is the way the code behaves good for its users?
- Complexity: Could the code be made simpler? Would another developer be able to easily understand and use this code when they come across it in the future?
- Tests: Does the code have correct and well-designed automated tests?
- Naming: Did the developer choose clear names for variables, classes, methods, etc.?
- Comments: Are the comments clear and useful?
- Style: Does the code follow our style guides?
- Documentation: Did the developer also update relevant documentation?
See How To Do A Code Review for more information.
Picking the Best Reviewers
In general, you want to find the best reviewers you can who are capable of responding to your review within a reasonable period of time.
The best reviewer is the person who will be able to give you the most thorough and correct review for the piece of code you are writing. This usually means the owner(s) of the code, who may or may not be the people in the CODEOWNERS file. Sometimes this means asking different people to review different parts of the PR.
If you find an ideal reviewer but they are not available, you should at least CC them on your change.
In-Person Reviews (and Pair Programming)
If you pair-programmed a piece of code with somebody who was qualified to do a good code review on it, then that code is considered reviewed.
You can also do in-person code reviews where the reviewer asks questions and the developer of the change speaks only when spoken to.
See Also
- How To Do A Code Review: A detailed guide for code reviewers.
- The PR Author’s Guide: A detailed guide for developers whose PRs are going through review.
How to do a code review
The pages in this section contain recommendations on the best way to do code reviews, based on long experience. All together they represent one complete document, broken up into many separate sections. You don’t have to read them all, but many people have found it very helpful to themselves and their team to read the entire set.
- The Standard of Code Review
- What to Look For In a Code Review
- Navigating a PR in Review
- Speed of Code Reviews
- How to Write Code Review Comments
- Handling Pushback in Code Reviews
See also the PR Author’s Guide, which gives detailed guidance to developers whose PRs are undergoing review.
The Standard of Code Review
The primary purpose of code review is to make sure that the overall code health of Google’s code base is improving over time. All of the tools and processes of code review are designed to this end.
In order to accomplish this, a series of trade-offs have to be balanced.
First, developers must be able to make progress on their tasks. If you never merge an improvement into the codebase, then the codebase never improves. Also, if a reviewer makes it very difficult for any change to go in, then developers are disincentivized to make improvements in the future.
On the other hand, it is the duty of the reviewer to make sure that each PR is of such a quality that the overall code health of their codebase is not decreasing as time goes on. This can be tricky, because often, codebases degrade through small decreases in code health over time, especially when a team is under significant time constraints and they feel that they have to take shortcuts in order to accomplish their goals.
Also, a reviewer has ownership and responsibility over the code they are reviewing. They want to ensure that the codebase stays consistent, maintainable, and all of the other things mentioned in “What to look for in a code review.”
Thus, we get the following rule as the standard we expect in code reviews:
In general, reviewers should favor approving a PR once it is in a state where it definitely improves the overall code health of the system being worked on, even if the PR isn’t perfect.
That is the senior principle among all of the code review guidelines.
There are limitations to this, of course. For example, if a PR adds a feature that the reviewer doesn’t want in their system, then the reviewer can certainly deny approval even if the code is well-designed.
A key point here is that there is no such thing as “perfect” code—there is only better code. Reviewers should not require the author to polish every tiny piece of a PR before granting approval. Rather, the reviewer should balance out the need to make forward progress compared to the importance of the changes they are suggesting. Instead of seeking perfection, what a reviewer should seek is continuous improvement. A PR that, as a whole, improves the maintainability, readability, and understandability of the system shouldn’t be delayed for days or weeks because it isn’t “perfect.”
Reviewers should always feel free to leave comments expressing that something could be better, but if it’s not very important, prefix it with something like “Nit: ” to let the author know that it’s just a point of polish that they could choose to ignore.
Note: Nothing in this document justifies merging PRs that definitely worsen the overall code health of the system. The only time you would do that would be in an emergency.
Mentoring
Code review can have an important function of teaching developers something new about a language, a framework, or general software design principles. It’s always fine to leave comments that help a developer learn something new. Sharing knowledge is part of improving the code health of a system over time. Just keep in mind that if your comment is purely educational, but not critical to meeting the standards described in this document, prefix it with “Nit: ” or otherwise indicate that it’s not mandatory for the author to resolve it in this PR.
Principles
-
Technical facts and data overrule opinions and personal preferences.
-
On matters of style, the style guide is the absolute authority. Any purely style point (whitespace, etc.) that is not in the style guide is a matter of personal preference. The style should be consistent with what is there. If there is no previous style, accept the author’s.
-
Aspects of software design are almost never a pure style issue or just a personal preference. They are based on underlying principles and should be weighed on those principles, not simply by personal opinion. Sometimes there are a few valid options. If the author can demonstrate (either through data or based on solid engineering principles) that several approaches are equally valid, then the reviewer should accept the preference of the author. Otherwise the choice is dictated by standard principles of software design.
-
If no other rule applies, then the reviewer may ask the author to be consistent with what is in the current codebase, as long as that doesn’t worsen the overall code health of the system.
Resolving Conflicts
In any conflict on a code review, the first step should always be for the developer and reviewer to try to come to consensus, based on the contents of this document and the other documents in The PR Author’s Guide and this Reviewer Guide.
When coming to consensus becomes especially difficult, it can help to have a face-to-face meeting or a video conference between the reviewer and the author, instead of just trying to resolve the conflict through code review comments. (If you do this, though, make sure to record the results of the discussion as a comment on the PR, for future readers.)
If that doesn’t resolve the situation, the most common way to resolve it would be to escalate. Often the escalation path is to a broader team discussion, having a Technical Lead weigh in, asking for a decision from a maintainer of the code, or asking an Eng Manager to help out. Don’t let a PR sit around because the author and the reviewer can’t come to an agreement.
Next: What to look for in a code review
What to look for in a code review
Note: Always make sure to take into account The Standard of Code Review when considering each of these points.
Design
The most important thing to cover in a review is the overall design of the PR. Do the interactions of various pieces of code in the PR make sense? Does this change belong in your codebase, or in a library? Does it integrate well with the rest of your system? Is now a good time to add this functionality?
Functionality
Does this PR do what the developer intended? Is what the developer intended good for the users of this code? The “users” are usually both end-users (when they are affected by the change) and developers (who will have to “use” this code in the future).
Mostly, we expect developers to test PRs well-enough that they work correctly by the time they get to code review. However, as the reviewer you should still be thinking about edge cases, looking for concurrency problems, trying to think like a user, and making sure that there are no bugs that you see just by reading the code.
You can validate the PR if you want—the time when it’s most important for a reviewer to check a PR’s behavior is when it has a user-facing impact, such as a UI change. It’s hard to understand how some changes will impact a user when you’re just reading the code. For changes like that, you can have the developer give you a demo of the functionality if it’s too inconvenient to patch in the PR and try it yourself.
Another time when it’s particularly important to think about functionality during a code review is if there is some sort of parallel programming going on in the PR that could theoretically cause deadlocks or race conditions. These sorts of issues are very hard to detect by just running the code and usually need somebody (both the developer and the reviewer) to think through them carefully to be sure that problems aren’t being introduced. (Note that this is also a good reason not to use concurrency models where race conditions or deadlocks are possible—it can make it very complex to do code reviews or understand the code.)
Complexity
Is the PR more complex than it should be? Check this at every level of the PR—are individual lines too complex? Are functions too complex? Are classes too complex? “Too complex” usually means “can’t be understood quickly by code readers.” It can also mean “developers are likely to introduce bugs when they try to call or modify this code.”
A particular type of complexity is over-engineering, where developers have made the code more generic than it needs to be, or added functionality that isn’t presently needed by the system. Reviewers should be especially vigilant about over-engineering. Encourage developers to solve the problem they know needs to be solved now, not the problem that the developer speculates might need to be solved in the future. The future problem should be solved once it arrives and you can see its actual shape and requirements in the physical universe.
Tests
Ask for unit, integration, or end-to-end tests as appropriate for the change. In general, tests should be added in the same PR as the production code unless the PR is handling an emergency.
Make sure that the tests in the PR are correct, sensible, and useful. Tests do not test themselves, and we rarely write tests for our tests—a human must ensure that tests are valid.
Will the tests actually fail when the code is broken? If the code changes beneath them, will they start producing false positives? Does each test make simple and useful assertions? Are the tests separated appropriately between different test methods?
Remember that tests are also code that has to be maintained. Don’t accept complexity in tests just because they aren’t part of the main binary.
Naming
Did the developer pick good names for everything? A good name is long enough to fully communicate what the item is or does, without being so long that it becomes hard to read.
Comments
Did the developer write clear comments in understandable English? Are all of the comments actually necessary? Usually comments are useful when they explain why some code exists, and should not be explaining what some code is doing. If the code isn’t clear enough to explain itself, then the code should be made simpler. There are some exceptions (regular expressions and complex algorithms often benefit greatly from comments that explain what they’re doing, for example) but mostly comments are for information that the code itself can’t possibly contain, like the reasoning behind a decision.
It can also be helpful to look at comments that were there before this PR. Maybe there is a TODO that can be removed now, a comment advising against this change being made, etc.
Note that comments are different from documentation of classes, modules, or functions, which should instead express the purpose of a piece of code, how it should be used, and how it behaves when used.
Style
We have style guides at Google for all of our major languages, and even for most of the minor languages. Make sure the PR follows the appropriate style guides.
If you want to improve some style point that isn’t in the style guide, prefix your comment with “Nit:” to let the developer know that it’s a nitpick that you think would improve the code but isn’t mandatory. Don’t block PRs from being merged based only on personal style preferences.
The author of the PR should not include major style changes combined with other changes. It makes it hard to see what is being changed in the PR, makes merges and rollbacks more complex, and causes other problems. For example, if the author wants to reformat the whole file, have them send you just the reformatting as one PR, and then send another PR with their functional changes after that.
Consistency
What if the existing code is inconsistent with the style guide? Per our code review principles, the style guide is the absolute authority: if something is required by the style guide, the PR should follow the guidelines.
In some cases, the style guide makes recommendations rather than declaring requirements. In these cases, it’s a judgment call whether the new code should be consistent with the recommendations or the surrounding code. Bias towards following the style guide unless the local inconsistency would be too confusing.
If no other rule applies, the author should maintain consistency with the existing code.
Either way, encourage the author to file a bug and add a TODO for cleaning up existing code.
Documentation
If a PR changes how users build, test, interact with, or release code, check to see that it also updates associated documentation, including READMEs, repository docs, and any generated reference docs. If the PR deletes or deprecates code, consider whether the documentation should also be deleted. If documentation is missing, ask for it.
Every Line
In the general case, look at every line of code that you have been assigned to review. Some things like data files, generated code, or large data structures you can scan over sometimes, but don’t scan over a human-written class, function, or block of code and assume that what’s inside of it is okay. Obviously some code deserves more careful scrutiny than other code—that’s a judgment call that you have to make—but you should at least be sure that you understand what all the code is doing.
If it’s too hard for you to read the code and this is slowing down the review, then you should let the developer know that and wait for them to clarify it before you try to review it. At Google, we hire great software engineers, and you are one of them. If you can’t understand the code, it’s very likely that other developers won’t either. So you’re also helping future developers understand this code, when you ask the developer to clarify it.
If you understand the code but you don’t feel qualified to do some part of the review, make sure there is a reviewer on the PR who is qualified, particularly for complex issues such as privacy, security, concurrency, accessibility, internationalization, etc.
Exceptions
What if it doesn’t make sense for you to review every line? For example, you are one of multiple reviewers on a PR and may be asked:
- To review only certain files that are part of a larger change.
- To review only certain aspects of the PR, such as the high-level design, privacy or security implications, etc.
In these cases, note in a comment which parts you reviewed. Prefer giving Approve with comments .
If you instead wish to grant Approval after confirming that other reviewers have reviewed other parts of the PR, note this explicitly in a comment to set expectations. Aim to respond quickly once the PR has reached the desired state.
Context
It is often helpful to look at the PR in a broad context. Usually the code review tool will only show you a few lines of code around the parts that are being changed. Sometimes you have to look at the whole file to be sure that the change actually makes sense. For example, you might see only four new lines being added, but when you look at the whole file, you see those four lines are in a 50-line method that now really needs to be broken up into smaller methods.
It’s also useful to think about the PR in the context of the system as a whole. Is this PR improving the code health of the system or is it making the whole system more complex, less tested, etc.? Don’t accept PRs that degrade the code health of the system. Most systems become complex through many small changes that add up, so it’s important to prevent even small complexities in new changes.
Good Things
If you see something nice in the PR, tell the developer, especially when they addressed one of your comments in a great way. Code reviews often just focus on mistakes, but they should offer encouragement and appreciation for good practices, as well. It’s sometimes even more valuable, in terms of mentoring, to tell a developer what they did right than to tell them what they did wrong.
Summary
In doing a code review, you should make sure that:
- The code is well-designed.
- The functionality is good for the users of the code.
- Any UI changes are sensible and look good.
- Any parallel programming is done safely.
- The code isn’t more complex than it needs to be.
- The developer isn’t implementing things they might need in the future but don’t know they need now.
- Code has appropriate unit tests.
- Tests are well-designed.
- The developer used clear names for everything.
- Comments are clear and useful, and mostly explain why instead of what.
- Code is appropriately documented (generally in repository docs).
- The code conforms to our style guides.
Make sure to review every line of code you’ve been asked to review, look at the context, make sure you’re improving code health, and compliment developers on good things that they do.
Next: Navigating a PR in Review
Navigating a PR in review
Summary
Now that you know what to look for, what’s the most efficient way to manage a review that’s spread across multiple files?
- Does the change make sense? Does it have a good description?
- Look at the most important part of the change first. Is it well-designed overall?
- Look at the rest of the PR in an appropriate sequence.
Step One: Take a broad view of the change
Look at the PR description and what the PR does in general. Does this change even make sense? If this change shouldn’t have happened in the first place, please respond immediately with an explanation of why the change should not be happening. When you reject a change like this, it’s also a good idea to suggest to the developer what they should have done instead.
For example, you might say “Looks like you put some good work into this, thanks! However, we’re actually going in the direction of removing the FooWidget system that you’re modifying here, and so we don’t want to make any new modifications to it right now. How about instead you refactor our new BarWidget class?”
Note that not only did the reviewer reject the current PR and provide an alternative suggestion, but they did it courteously. This kind of courtesy is important because we want to show that we respect each other as developers even when we disagree.
If you get more than a few PRs that represent changes you don’t want to make, you should consider re-working your team’s development process or the posted process for external contributors so that there is more communication before PRs are written. It’s better to tell people “no” before they’ve done a ton of work that now has to be thrown away or drastically re-written.
Step Two: Examine the main parts of the PR
Find the file or files that are the “main” part of this PR. Often, there is one file that has the largest number of logical changes, and it’s the major piece of the PR. Look at these major parts first. This helps give context to all of the smaller parts of the PR, and generally accelerates doing the code review. If the PR is too large for you to figure out which parts are the major parts, ask the developer what you should look at first, or ask them to split up the PR into multiple PRs.
If you see some major design problems with this part of the PR, you should send those comments immediately, even if you don’t have time to review the rest of the PR right now. In fact, reviewing the rest of the PR might be a waste of time, because if the design problems are significant enough, a lot of the other code under review is going to disappear and not matter anyway.
There are two major reasons it’s so important to send these major design comments out immediately:
- Developers often mail a PR and then immediately start new work based on that PR while they wait for review. If there are major design problems in the PR you’re reviewing, they’re also going to have to re-work their later PR. You want to catch them before they’ve done too much extra work on top of the problematic design.
- Major design changes take longer to do than small changes. Developers nearly all have deadlines; in order to make those deadlines and still have quality code in the codebase, the developer needs to start on any major re-work of the PR as soon as possible.
Step Three: Look through the rest of the PR in an appropriate sequence
Once you’ve confirmed there are no major design problems with the PR as a whole, try to figure out a logical sequence to look through the files while also making sure you don’t miss reviewing any file. Usually after you’ve looked through the major files, it’s simplest to just go through each file in the order that the code review tool presents them to you. Sometimes it’s also helpful to read the tests first before you read the main code, because then you have an idea of what the change is supposed to be doing.
Next: Speed of Code Reviews
Speed of Code Reviews
Why Should Code Reviews Be Fast?
At Google, we optimize for the speed at which a team of developers can produce a product together, as opposed to optimizing for the speed at which an individual developer can write code. The speed of individual development is important, it’s just not as important as the velocity of the entire team.
When code reviews are slow, several things happen:
- The velocity of the team as a whole is decreased. Yes, the individual who doesn’t respond quickly to the review gets other work done. However, new features and bug fixes for the rest of the team are delayed by days, weeks, or months as each PR waits for review and re-review.
- Developers start to protest the code review process. If a reviewer only responds every few days, but requests major changes to the PR each time, that can be frustrating and difficult for developers. Often, this is expressed as complaints about how “strict” the reviewer is being. If the reviewer requests the same substantial changes (changes which really do improve code health), but responds quickly every time the developer makes an update, the complaints tend to disappear. Most complaints about the code review process are actually resolved by making the process faster.
- Code health can be impacted. When reviews are slow, there is increased pressure to allow developers to merge PRs that are not as good as they could be. Slow reviews also discourage code cleanups, refactorings, and further improvements to existing PRs.
How Fast Should Code Reviews Be?
If you are not in the middle of a focused task, you should do a code review shortly after it comes in.
One business day is the maximum time it should take to respond to a code review request (i.e., first thing the next morning).
Following these guidelines means that a typical PR should get multiple rounds of review (if needed) within a single day.
Speed vs. Interruption
There is one time where the consideration of personal velocity trumps team velocity. If you are in the middle of a focused task, such as writing code, don’t interrupt yourself to do a code review. Research has shown that it can take a long time for a developer to get back into a smooth flow of development after being interrupted. So interrupting yourself while coding is actually more expensive to the team than making another developer wait a bit for a code review.
Instead, wait for a break point in your work before you respond to a request for review. This could be when your current coding task is completed, after lunch, returning from a meeting, coming back from the breakroom, etc.
Fast Responses
When we talk about the speed of code reviews, it is the response time that we are concerned with, as opposed to how long it takes a PR to get through the whole review and be merged. The whole process should also be fast, ideally, but it’s even more important for the individual responses to come quickly than it is for the whole process to happen rapidly.
Even if it sometimes takes a long time to get through the entire review process, having quick responses from the reviewer throughout the process significantly eases the frustration developers can feel with “slow” code reviews.
If you are too busy to do a full review on a PR when it comes in, you can still send a quick response that lets the developer know when you will get to it, suggest other reviewers who might be able to respond more quickly, or provide some initial broad comments. (Note: none of this means you should interrupt coding even to send a response like this—send the response at a reasonable break point in your work.)
It is important that reviewers spend enough time on review that they are certain their “Approve” means “this code meets our standards.” However, individual responses should still ideally be fast.
Cross-Time-Zone Reviews
When dealing with time zone differences, try to get back to the author while they have time to respond before the end of their working hours. If they have already finished work for the day, then try to make sure your review is done before they start work the next day.
Approve With Comments (LGTM)
In order to speed up code reviews, there are certain situations in which a reviewer should Approve even though they are also leaving unresolved comments on the PR. This should be done when at least one of the following applies:
- The reviewer is confident that the developer will appropriately address all the reviewer’s remaining comments.
- The comments don’t have to be addressed by the developer.
- The suggestions are minor, e.g. sort imports, fix a nearby typo, apply a suggested fix, remove an unused dep, etc.
The reviewer should specify which of these options they intend, if it is not otherwise clear.
Approve With Comments is especially worth considering when the developer and reviewer are in different time zones and otherwise the developer would be waiting for a whole day just to get approval.
Large PRs
If somebody sends you a code review that is so large you’re not sure when you will be able to have time to review it, your typical response should be to ask the developer to split the PR into several smaller PRs that build on each other, instead of one huge PR that has to be reviewed all at once. This is usually possible and very helpful to reviewers, even if it takes additional work from the developer.
If a PR can’t be broken up into smaller PRs, and you don’t have time to review the entire thing quickly, then at least write some comments on the overall design of the PR and send it back to the developer for improvement. One of your goals as a reviewer should be to always unblock the developer or enable them to take some sort of further action quickly, without sacrificing code health to do so.
Code Review Improvements Over Time
If you follow these guidelines and you are strict with your code reviews, you should find that the entire code review process tends to go faster and faster over time. Developers learn what is required for healthy code, and send you PRs that are great from the start, requiring less and less review time. Reviewers learn to respond quickly and not add unnecessary latency into the review process. But don’t compromise on the code review standards or quality for an imagined improvement in velocity—it’s not actually going to make anything happen more quickly, in the long run.
Emergencies
There are also emergencies where PRs must pass through the whole review process very quickly, and where the quality guidelines would be relaxed. However, please see What Is An Emergency? for a description of which situations actually qualify as emergencies and which don’t.
Next: How to Write Code Review Comments
How to write code review comments
Summary
- Be kind.
- Explain your reasoning.
- Balance giving explicit directions with just pointing out problems and letting the developer decide.
- Encourage developers to simplify code or add code comments instead of just explaining the complexity to you.
Courtesy
In general, it is important to be courteous and respectful while also being very clear and helpful to the developer whose code you are reviewing. One way to do this is to be sure that you are always making comments about the code and never making comments about the developer. You don’t always have to follow this practice, but you should definitely use it when saying something that might otherwise be upsetting or contentious. For example:
Bad: “Why did you use threads here when there’s obviously no benefit to be gained from concurrency?”
Good: “The concurrency model here is adding complexity to the system without any actual performance benefit that I can see. Because there’s no performance benefit, it’s best for this code to be single-threaded instead of using multiple threads.”
Explain Why
One thing you’ll notice about the “good” example from above is that it helps the developer understand why you are making your comment. You don’t always need to include this information in your review comments, but sometimes it’s appropriate to give a bit more explanation around your intent, the best practice you’re following, or how your suggestion improves code health.
Giving Guidance
In general it is the developer’s responsibility to fix a PR, not the reviewer’s. You are not required to do detailed design of a solution or write code for the developer.
This doesn’t mean the reviewer should be unhelpful, though. In general you should strike an appropriate balance between pointing out problems and providing direct guidance. Pointing out problems and letting the developer make a decision often helps the developer learn, and makes it easier to do code reviews. It also can result in a better solution, because the developer is closer to the code than the reviewer is.
However, sometimes direct instructions, suggestions, or even code are more helpful. The primary goal of code review is to get the best PR possible. A secondary goal is improving the skills of developers so that they require less and less review over time.
Remember that people learn from reinforcement of what they are doing well and not just what they could do better. If you see things you like in the PR, comment on those too! Examples: developer cleaned up a messy algorithm, added exemplary test coverage, or you as the reviewer learned something from the PR. Just as with all comments, include why you liked something, further encouraging the developer to continue good practices.
Label comment severity
Consider labeling the severity of your comments, differentiating required changes from guidelines or suggestions.
Here are some examples:
Nit: This is a minor thing. Technically you should do it, but it won’t hugely impact things.
Optional (or Consider): I think this may be a good idea, but it’s not strictly required.
FYI: I don’t expect you to do this in this PR, but you may find this interesting to think about for the future.
This makes review intent explicit and helps authors prioritize the importance of various comments. It also helps avoid misunderstandings; for example, without comment labels, authors may interpret all comments as mandatory, even if some comments are merely intended to be informational or optional.
Accepting Explanations
If you ask a developer to explain a piece of code that you don’t understand, that should usually result in them rewriting the code more clearly. Occasionally, adding a comment in the code is also an appropriate response, as long as it’s not just explaining overly complex code.
Explanations written only in the code review tool are not helpful to future code readers. They are acceptable only in a few circumstances, such as when you are reviewing an area you are not very familiar with and the developer explains something that normal readers of the code would have already known.
Next: Handling Pushback in Code Reviews
Handling pushback in code reviews
Sometimes a developer will push back on a code review. Either they will disagree with your suggestion or they will complain that you are being too strict in general.
Who is right?
When a developer disagrees with your suggestion, first take a moment to consider if they are correct. Often, they are closer to the code than you are, and so they might really have a better insight about certain aspects of it. Does their argument make sense? Does it make sense from a code health perspective? If so, let them know that they are right and let the issue drop.
However, developers are not always right. In this case the reviewer should further explain why they believe that their suggestion is correct. A good explanation demonstrates both an understanding of the developer’s reply, and additional information about why the change is being requested.
In particular, when the reviewer believes their suggestion will improve code health, they should continue to advocate for the change, if they believe the resulting code quality improvement justifies the additional work requested. Improving code health tends to happen in small steps.
Sometimes it takes a few rounds of explaining a suggestion before it really sinks in. Just make sure to always stay polite and let the developer know that you hear what they’re saying, you just don’t agree.
Upsetting Developers
Reviewers sometimes believe that the developer will be upset if the reviewer insists on an improvement. Sometimes developers do become upset, but it is usually brief and they become very thankful later that you helped them improve the quality of their code. Usually, if you are polite in your comments, developers actually don’t become upset at all, and the worry is just in the reviewer’s mind. Upsets are usually more about the way comments are written than about the reviewer’s insistence on code quality.
Cleaning It Up Later
A common source of push back is that developers (understandably) want to get things done. They don’t want to go through another round of review just to get this PR in. So they say they will clean something up in a later PR, and thus you should Approve this PR now. Some developers are very good about this, and will immediately write a follow-up PR that fixes the issue. However, experience shows that as more time passes after a developer writes the original PR, the less likely this clean up is to happen. In fact, usually unless the developer does the clean up immediately after the present PR, it never happens. This isn’t because developers are irresponsible, but because they have a lot of work to do and the cleanup gets lost or forgotten in the press of other work. Thus, it is usually best to insist that the developer clean up their PR now, before the code is in the codebase and “done.” Letting people “clean things up later” is a common way for codebases to degenerate.
If a PR introduces new complexity, it must be cleaned up before merge unless it is an emergency. If the PR exposes surrounding problems and they can’t be addressed right now, the developer should file a bug for the cleanup and assign it to themselves so that it doesn’t get lost. They can optionally also write a TODO comment in the code that references the filed bug.
General Complaints About Strictness
If you previously had fairly lax code reviews and you switch to having strict reviews, some developers will complain very loudly. Improving the speed of your code reviews usually causes these complaints to fade away.
Sometimes it can take months for these complaints to fade away, but eventually developers tend to see the value of strict code reviews as they see what great code they help generate. Sometimes the loudest protesters even become your strongest supporters once something happens that causes them to really see the value you’re adding by being strict.
Resolving Conflicts
If you are following all of the above but you still encounter a conflict between yourself and a developer that can’t be resolved, see The Standard of Code Review for guidelines and principles that can help resolve the conflict.
The PR author’s guide to getting through code review
The pages in this section contain best practices for developers going through code review. These guidelines should help you get through reviews faster and with higher-quality results. You don’t have to read them all, but they are intended to apply to every Google developer, and many people have found it helpful to read the whole set.
See also How to Do a Code Review, which gives detailed guidance for code reviewers.
Writing good PR descriptions
A PR description is a public record of change, and it is important that it communicates:
-
What change is being made? This should summarize the major changes such that readers have a sense of what is being changed without needing to read the entire PR.
-
Why are these changes being made? What contexts did you have as an author when making this change? Were there decisions you made that aren’t reflected in the source code? etc.
The PR description will become a permanent part of our version control history and will possibly be read by hundreds of people over the years.
Future developers will search for your PR based on its description. Someone in the future might be looking for your change because of a faint memory of its relevance but without the specifics handy. If all the important information is in the code and not the description, it’s going to be a lot harder for them to locate your PR.
And then, after they find the PR, will they be able to understand why the change was made? Reading source code may reveal what the software is doing but it may not reveal why it exists, which can make it harder for future developers to know whether they can move Chesterton’s fence.
A well-written PR description will help those future engineers – sometimes, including yourself!
First Line
- Short summary of what is being done.
- Complete sentence, written as though it was an order.
- Follow by empty line.
The first line of a PR description should be a short summary of specifically what is being done by the PR, followed by a blank line. This is what appears in version control history summaries, so it should be informative enough that future code searchers don’t have to read your PR or its whole description to understand what your PR actually did or how it differs from other PRs. That is, the first line should stand alone, allowing readers to skim through code history much faster.
Try to keep your first line short, focused, and to the point. The clarity and utility to the reader should be the top concern.
By tradition, the first line of a PR description is a complete sentence, written as though it were an order (an imperative sentence). For example, say “Delete the FizzBuzz RPC and replace it with the new system.” instead of “Deleting the FizzBuzz RPC and replacing it with the new system.” You don’t have to write the rest of the description as an imperative sentence, though.
Body is Informative
The first line should be a short, focused summary, while the rest of the description should fill in the details and include any supplemental information a reader needs to understand the change holistically. It might include a brief description of the problem that’s being solved, and why this is the best approach. If there are any shortcomings to the approach, they should be mentioned. If relevant, include background information such as bug numbers, benchmark results, and links to design documents.
If you include links to external resources consider that they may not be visible to future readers due to access restrictions or retention policies. Where possible include enough context for reviewers and future readers to understand the PR.
Even small PRs deserve a little attention to detail. Put the PR in context.
Bad PR Descriptions
“Fix bug” is an inadequate PR description. What bug? What did you do to fix it? Other similarly bad descriptions include:
- “Fix build.”
- “Add patch.”
- “Moving code from A to B.”
- “Phase 1.”
- “Add convenience functions.”
- “kill weird URLs.”
Some of those are real PR descriptions. Although short, they do not provide enough useful information.
Good PR Descriptions
Here are some examples of good descriptions.
Functionality change
Example:
RPC: Remove size limit on RPC server message freelist.
Servers like FizzBuzz have very large messages and would benefit from reuse. Make the freelist larger, and add a goroutine that frees the freelist entries slowly over time, so that idle servers eventually release all freelist entries.
The first few words describe what the PR actually does. The rest of the description talks about the problem being solved, why this is a good solution, and a bit more information about the specific implementation.
Refactoring
Example:
Construct a Task with a TimeKeeper to use its TimeStr and Now methods.
Add a Now method to Task, so the borglet() getter method can be removed (which was only used by OOMCandidate to call borglet’s Now method). This replaces the methods on Borglet that delegate to a TimeKeeper.
Allowing Tasks to supply Now is a step toward eliminating the dependency on Borglet. Eventually, collaborators that depend on getting Now from the Task should be changed to use a TimeKeeper directly, but this has been an accommodation to refactoring in small steps.
Continuing the long-range goal of refactoring the Borglet Hierarchy.
The first line describes what the PR does and how this is a change from the past. The rest of the description talks about the specific implementation, the context of the PR, that the solution isn’t ideal, and possible future direction. It also explains why this change is being made.
Small PR that needs some context
Example:
Create a Python3 build rule for status.py.
This allows consumers who are already using this as in Python3 to depend on a rule that is next to the original status build rule instead of somewhere in their own tree. It encourages new consumers to use Python3 if they can, instead of Python2, and significantly simplifies some automated build file refactoring tools being worked on currently.
The first sentence describes what’s actually being done. The rest of the description explains why the change is being made and gives the reviewer a lot of context.
Using tags
Tags are manually entered labels that can be used to categorize PRs. These may be supported by tools or just used by team convention.
For example:
- “[tag]”
- “[a longer tag]”
- “#tag”
- “tag:”
Using tags is optional.
When adding tags, consider whether they should be in the body of the PR description or the first line. Limit the usage of tags in the first line, as this can obscure the content.
Examples with and without tags:
Good:
// Tags are okay in the first line if kept short. [banana] Peel the banana before eating. // Tags can be inlined in content. Peel the #banana before eating. // Tags are optional. Peel the banana before eating. // Multiple tags are acceptable if kept short. #banana #apple: Assemble a fruit basket. // Tags can go anywhere in the PR description. > Assemble a fruit basket. > > #banana #appleBad:
// Too many tags (or tags that are too long) overwhelm the first line. // // Instead, consider whether the tags can be moved into the description body // and/or shortened. [banana peeler factory factory][apple picking service] Assemble a fruit basket.Generated PR descriptions
Some PRs are generated by tools. Whenever possible, their descriptions should also follow the advice here. That is, their first line should be short, focused, and stand alone, and the PR description body should include informative details that help reviewers and future code searchers understand each PR’s effect.
Review the description before merging the PR
PRs can undergo significant change during review. It can be worthwhile to review a PR description before merging the PR, to ensure that the description still reflects what the PR does.
Next: Small PRs
Small PRs
Why Write Small PRs?
Small, simple PRs are:
- Reviewed more quickly. It’s easier for a reviewer to find five minutes several times to review small PRs than to set aside a 30 minute block to review one large PR.
- Reviewed more thoroughly. With large changes, reviewers and authors tend to get frustrated by large volumes of detailed commentary shifting back and forth—sometimes to the point where important points get missed or dropped.
- Less likely to introduce bugs. Since you’re making fewer changes, it’s easier for you and your reviewer to reason effectively about the impact of the PR and see if a bug has been introduced.
- Less wasted work if they are rejected. If you write a huge PR and then your reviewer says that the overall direction is wrong, you’ve wasted a lot of work.
- Easier to merge. Working on a large PR takes a long time, so you will have lots of conflicts when you merge, and you will have to merge frequently.
- Easier to design well. It’s a lot easier to polish the design and code health of a small change than it is to refine all the details of a large change.
- Less blocking on reviews. Sending self-contained portions of your overall change allows you to continue coding while you wait for your current PR in review.
- Simpler to roll back. A large PR will more likely touch files that get updated between the initial PR submission and a rollback PR, complicating the rollback (the intermediate PRs will probably need to be rolled back too).
Note that reviewers have discretion to reject your change outright for the sole reason of it being too large. Usually they will thank you for your contribution but request that you somehow make it into a series of smaller changes. It can be a lot of work to split up a change after you’ve already written it, or require lots of time arguing about why the reviewer should accept your large change. It’s easier to just write small PRs in the first place.
What is Small?
In general, the right size for a PR is one self-contained change. This means that:
- The PR makes a minimal change that addresses just one thing. This is usually just one part of a feature, rather than a whole feature at once. In general it’s better to err on the side of writing PRs that are too small vs. PRs that are too large. Work with your reviewer to find out what an acceptable size is.
- The PR should include related test code.
- Everything the reviewer needs to understand about the PR (except future development) is in the PR, the PR’s description, the existing codebase, or a PR they’ve already reviewed.
- The system will continue to work well for its users and for the developers after the PR is merged.
- The PR is not so small that its implications are difficult to understand. If you add a new API, you should include a usage of the API in the same PR so that reviewers can better understand how the API will be used. This also prevents checking in unused APIs.
There are no hard and fast rules about how large is “too large.” 100 lines is usually a reasonable size for a PR, and 1000 lines is usually too large, but it’s up to the judgment of your reviewer. The number of files that a change is spread across also affects its “size.” A 200-line change in one file might be okay, but spread across 50 files it would usually be too large.
Keep in mind that although you have been intimately involved with your code from the moment you started to write it, the reviewer often has no context. What seems like an acceptably-sized PR to you might be overwhelming to your reviewer. When in doubt, write PRs that are smaller than you think you need to write. Reviewers rarely complain about getting PRs that are too small.
When are Large PRs Okay?
There are a few situations in which large changes aren’t as bad:
- You can usually count deletion of an entire file as being just one line of change, because it doesn’t take the reviewer very long to review.
- Sometimes a large PR has been generated by an automatic refactoring tool that you trust completely, and the reviewer’s job is just to verify and say that they really do want the change. These PRs can be larger, although some of the caveats from above (such as merging and testing) still apply.
Writing Small PRs Efficiently
If you write a small PR and then you wait for your reviewer to approve it before you write your next PR, then you’re going to waste a lot of time. So you want to find some way to work that won’t block you while you’re waiting for review. This could involve having multiple projects to work on simultaneously, finding reviewers who agree to be immediately available, doing in-person reviews, pair programming, or splitting your PRs in a way that allows you to continue working immediately.
Splitting PRs
When starting work that will have multiple PRs with potential dependencies among each other, it’s often useful to think about how to split and organize those PRs at a high level before diving into coding.
Besides making things easier for you as an author to manage and organize your PRs, it also makes things easier for your code reviewers, which in turn makes your code reviews more efficient.
Here are some strategies for splitting work into different PRs.
Stacking Multiple Changes on Top of Each Other
One way to split up a PR without blocking yourself is to write one small PR, send it off for review, and then immediately start writing another PR based on the first PR. Most version control systems allow you to do this somehow.
Splitting by Files
Another way to split up a PR is by groupings of files that will require different reviewers but are otherwise self-contained changes.
For example: you send off one PR for modifications to a protocol buffer and another PR for changes to the code that uses that proto. You have to merge the proto PR before the code PR, but they can both be reviewed simultaneously. If you do this, you might want to inform both sets of reviewers about the other PR that you wrote, so that they have context for your changes.
Another example: you send one PR for a code change and another for the configuration or experiment that uses that code; this is easier to roll back too, if necessary, as configuration/experiment files are sometimes pushed to production faster than code changes.
Splitting Horizontally
Consider creating shared code or stubs that help isolate changes between layers of the tech stack. This not only helps expedite development but also encourages abstraction between layers.
For example: You created a calculator app with client, API, service, and data model layers. A shared proto signature can abstract the service and data model layers from each other. Similarly, an API stub can split the implementation of client code from service code and enable them to move forward independently. Similar ideas can also be applied to more granular function or class level abstractions.
Splitting Vertically
Orthogonal to the layered, horizontal approach, you can instead break down your code into smaller, full-stack, vertical features. Each of these features can be independent parallel implementation tracks. This enables some tracks to move forward while other tracks are awaiting review or feedback.
Back to our calculator example from Splitting Horizontally. You now want to support new operators, like multiplication and division. You could split this up by implementing multiplication and division as separate verticals or sub-features, even though they may have some overlap such as shared button styling or shared validation logic.
Splitting Horizontally & Vertically
To take this a step further, you could combine these approaches and chart out an implementation plan like this, where each cell is its own standalone PR. Starting from the model (at the bottom) and working up to the client:
Layer Feature: Multiplication Feature: Division Client Add button Add button API Add endpoint Add endpoint Service Implement transformations Share transformation logic with … … … Model Add proto definition Add proto definition Separate Out Refactorings
It’s usually best to do refactorings in a separate PR from feature changes or bug fixes. For example, moving and renaming a class should be in a different PR from fixing a bug in that class. It is much easier for reviewers to understand the changes introduced by each PR when they are separate.
Small cleanups such as fixing a local variable name can be included inside of a feature change or bug fix PR, though. It’s up to the judgment of developers and reviewers to decide when a refactoring is so large that it will make the review more difficult if included in your current PR.
Keep related test code in the same PR
PRs should include related test code. Remember that smallness here refers the conceptual idea that the PR should be focused and is not a simplistic function on line count.
Tests are expected for all Google changes.
A PR that adds or changes logic should be accompanied by new or updated tests for the new behavior. Pure refactoring PRs (that aren’t intended to change behavior) should also be covered by tests; ideally, these tests already exist, but if they don’t, you should add them.
Independent test modifications can go into separate PRs first, similar to the refactorings guidelines. That includes:
- Validating pre-existing, merged code with new tests.
- Ensures that important logic is covered by tests.
- Increases confidence in subsequent refactorings on affected code. For example, if you want to refactor code that isn’t already covered by tests, merging test PRs before merging refactoring PRs can validate that the tested behavior is unchanged before and after the refactoring.
- Refactoring the test code (e.g. introduce helper functions).
- Introducing larger test framework code (e.g. an integration test).
Don’t Break the Build
If you have several PRs that depend on each other, you need to find a way to make sure the whole system keeps working after each PR is merged. Otherwise you might break the build for all your fellow developers for a few minutes between your PR merges (or even longer if something goes wrong unexpectedly with your later PR merges).
Can’t Make it Small Enough
Sometimes you will encounter situations where it seems like your PR has to be large. This is very rarely true. Authors who practice writing small PRs can almost always find a way to decompose functionality into a series of small changes.
Before writing a large PR, consider whether preceding it with a refactoring-only PR could pave the way for a cleaner implementation. Talk to your teammates and see if anybody has thoughts on how to implement the functionality in small PRs instead.
If all of these options fail (which should be extremely rare) then get consent from your reviewers in advance to review a large PR, so they are warned about what is coming. In this situation, expect to be going through the review process for a long time, be vigilant about not introducing bugs, and be extra diligent about writing tests.
Next: How to Handle Reviewer Comments
How to handle reviewer comments
When you’ve sent a PR out for review, it’s likely that your reviewer will respond with several comments on your PR. Here are some useful things to know about handling reviewer comments.
Don’t Take it Personally
The goal of review is to maintain the quality of our codebase and our products. When a reviewer provides a critique of your code, think of it as their attempt to help you, the codebase, and Google, rather than as a personal attack on you or your abilities.
Sometimes reviewers feel frustrated and they express that frustration in their comments. This isn’t a good practice for reviewers, but as a developer you should be prepared for this. Ask yourself, “What is the constructive thing that the reviewer is trying to communicate to me?” and then operate as though that’s what they actually said.
Never respond in anger to code review comments. That is a serious breach of professional etiquette that will live in the review history. If you are too angry or annoyed to respond kindly, then walk away from your computer for a while, or work on something else until you feel calm enough to reply politely.
In general, if a reviewer isn’t providing feedback in a way that’s constructive and polite, explain this to them in person. If you can’t talk to them in person or on a video call, then send them a private email. Explain to them in a kind way what you don’t like and what you’d like them to do differently. If they also respond in a non-constructive way to this private discussion, or it doesn’t have the intended effect, then escalate to your manager as appropriate.
Fix the Code
If a reviewer says that they don’t understand something in your code, your first response should be to clarify the code itself. If the code can’t be clarified, add a code comment that explains why the code is there. If a comment seems pointless, only then should your response be an explanation in the code review tool.
If a reviewer didn’t understand some piece of your code, it’s likely other future readers of the code won’t understand either. Writing a response in the review tool doesn’t help future code readers, but clarifying your code or adding code comments does help them.
Think Collaboratively
Writing a PR can take a lot of work. It’s often really satisfying to finally send one out for review, feel like it’s done, and be pretty sure that no further work is needed. It can be frustrating to receive comments asking for changes, especially if you don’t agree with them.
At times like this, take a moment to step back and consider if the reviewer is providing valuable feedback that will help the codebase and Google. Your first question to yourself should always be, “Do I understand what the reviewer is asking for?”
If you can’t answer that question, ask the reviewer for clarification.
And then, if you understand the comments but disagree with them, it’s important to think collaboratively, not combatively or defensively:
Bad: "No, I'm not going to do that."Good: "I went with X because of [these pros/cons] with [these tradeoffs] My understanding is that using Y would be worse because of [these reasons]. Are you suggesting that Y better serves the original tradeoffs, that we should weigh the tradeoffs differently, or something else?"Remember, courtesy and respect should always be a first priority. If you disagree with the reviewer, find ways to collaborate: ask for clarifications, discuss pros/cons, and provide explanations of why your method of doing things is better for the codebase, users, and/or Google.
Sometimes, you might know something about the users, codebase, or PR that the reviewer doesn’t know. Fix the code where appropriate, and engage your reviewer in discussion, including giving them more context. Usually you can come to some consensus between yourself and the reviewer based on technical facts.
Resolving Conflicts
Your first step in resolving conflicts should always be to try to come to consensus with your reviewer. If you can’t achieve consensus, see The Standard of Code Review, which gives principles to follow in such a situation.
Emergencies
Sometimes there are emergency PRs that must pass through the entire code review process as quickly as possible.
What Is An Emergency?
An emergency PR would be a small change that: allows a major launch to continue instead of rolling back, fixes a bug significantly affecting users in production, handles a pressing legal issue, closes a major security hole, etc.
In emergencies we really do care about the speed of the entire code review process, not just the speed of response. In this case only, the reviewer should care more about the speed of the review and the correctness of the code (does it actually resolve the emergency?) than anything else. Also (perhaps obviously) such reviews should take priority over all other code reviews, when they come up.
However, after the emergency is resolved you should look over the emergency PRs again and give them a more thorough review.
What Is NOT An Emergency?
To be clear, the following cases are not an emergency:
- Wanting to launch this week rather than next week (unless there is some actual hard deadline for launch such as a partner agreement).
- The developer has worked on a feature for a very long time and they really want to get the PR in.
- The reviewers are all in another timezone where it is currently nighttime or they are away on an off-site.
- It is the end of the day on a Friday and it would just be great to get this PR in before the developer leaves for the weekend.
- A manager says that this review has to be complete and the PR merged today because of a soft (not hard) deadline.
- Rolling back a PR that is causing test failures or build breakages.
And so on.
What Is a Hard Deadline?
A hard deadline is one where something disastrous would happen if you miss it. For example:
- Submitting your PR by a certain date is necessary for a contractual obligation.
- Your product will completely fail in the marketplace if not released by a certain date.
- Some hardware manufacturers only ship new hardware once a year. If you miss the deadline to submit code to them, that could be disastrous, depending on what type of code you’re trying to ship.
Delaying a release for a week is not disastrous. Missing an important conference might be disastrous, but often is not.
Most deadlines are soft deadlines, not hard deadlines. They represent a desire for a feature to be done by a certain time. They are important, but you shouldn’t be sacrificing code health to make them.
If you have a long release cycle (several weeks) it can be tempting to sacrifice code review quality to get a feature in before the next cycle. However, this pattern, if repeated, is a common way for projects to build up overwhelming technical debt. If developers are routinely merging PRs near the end of the cycle that “must get in” with only superficial review, then the team should modify its process so that large feature changes happen early in the cycle and have enough time for good review.
-
CLAUDE.md to AGENTS.md Migration Guide
Update: Anthropic still doesn’t fully accept AGENTS.md, so I created this:
claude-md-symlinker.Install it once and Claude Code can keep local
CLAUDE.md -> AGENTS.mdsymlinks working for you. No manually creating shim files, no committing Claude-branded files into your repos.Install using the installer script, or give this page to Claude and ask it to install for you.
curl -fsSL https://github.com/osolmaz/claude-md-symlinker/releases/latest/download/claude-md-symlinker-installer.sh | shThis will install a Claude hook that will check whenever Claude traverses a certain directory, and do the migration automatically for you.
If you are paranoid about security, ask Claude to check the source code for any issues and install the symlinker from the source.
This post will age like milk, because Anthropic will eventually adopt the company-agnostic AGENTS.md standard.
For those that do not know, AGENTS.md is like robots.txt, but for providing plain text context to any AI agent working in your codebase.
It’s very stupid really. It’s not even worthy of being called a “standard”. The only rule is the name of the file.
Anthropic champions CLAUDE.md, named after their own agent Claude. Insisting on that stupid convention is like Google forcing websites to use
googlebot.txtinstead ofrobots.txt, or Microsoftclippy.txt.Anyway, since this post will become irrelevant very soon, here are some AI-generated instructions on how to migrate your CLAUDE.md files to AGENTS.md.
Why Migrate?
- Open Standard: AGENTS.md is an open standard that works with multiple AI systems
- Interoperability: Maintains backward compatibility through symlinks
- Future-Proof: Not tied to a specific AI platform or tool
- Consistency: Standardizes agent instructions across the codebase
Actual Migration Commands Used
Step 1: Rename Files
The following commands were used to rename existing CLAUDE.md files to AGENTS.md:
# Find all CLAUDE.md files and rename them to AGENTS.md find . -name "CLAUDE.md" -type f -exec sh -c 'mv "$1" "${1%CLAUDE.md}AGENTS.md"' _ {} \;Step 2: Update Content
Replace Claude-specific references with agent-agnostic language:
# Update file headers in all AGENTS.md files find . -name "AGENTS.md" -type f -exec sed -i '' 's/This file provides guidance to Claude Code (claude.ai\/code)/This file provides guidance to AI agents/g' {} \;Step 3: Update .gitignore
Add these lines to
.gitignoreto ignore symlinked CLAUDE.md files:# Add to .gitignore cat >> .gitignore << 'EOF' # CLAUDE.md files (automatically generated from AGENTS.md via symlinks) CLAUDE.md **/CLAUDE.md EOFStep 4: Create Symlink Setup Script
Create
utils/setup-claude-symlinks.shwith the following content:#!/bin/bash # Script to create CLAUDE.md symlinks to AGENTS.md files # This allows CLAUDE.md files to exist locally without being committed to git set -e echo "Setting up CLAUDE.md symlinks..." # Change to repository root cd "$(git rev-parse --show-toplevel)" # Find all AGENTS.md files and create corresponding CLAUDE.md symlinks git ls-files | grep "AGENTS\.md$" | while read -r file; do dir=$(dirname "$file") claude_file="${file/AGENTS.md/CLAUDE.md}" # Remove existing CLAUDE.md file/link if it exists if [ -e "$claude_file" ] || [ -L "$claude_file" ]; then rm "$claude_file" echo "Removed existing $claude_file" fi # Create symlink if [ "$dir" = "." ]; then ln -s "AGENTS.md" "CLAUDE.md" echo "Created symlink: CLAUDE.md -> AGENTS.md" else ln -s "AGENTS.md" "$claude_file" echo "Created symlink: $claude_file -> AGENTS.md" fi done echo "" echo "✓ CLAUDE.md symlinks setup complete!" echo " - CLAUDE.md files are ignored by git" echo " - They will automatically stay in sync with AGENTS.md files" echo " - Run this script again if you add new AGENTS.md files"Step 5: Run Symlink Setup
Make the script executable and run it:
chmod +x utils/setup-claude-symlinks.sh ./utils/setup-claude-symlinks.shTop-Level AGENTS.md Note
Add this note to the main AGENTS.md file:
**Note**: This project uses the open AGENTS.md standard. These files are symlinked to CLAUDE.md files in the same directory for interoperability with Claude Code. Any agent instructions or memory features should be saved to AGENTS.md files instead of CLAUDE.md files.Directory Structure After Migration
project/ ├── AGENTS.md # Primary agent instructions ├── CLAUDE.md # Symlink to AGENTS.md (git ignored) ├── utils/ │ └── setup-claude-symlinks.sh # Symlink setup script ├── backend/ │ ├── AGENTS.md # Backend-specific instructions │ └── CLAUDE.md # Symlink to AGENTS.md (git ignored) └── apps/ ├── AGENTS.md # Frontend-specific instructions ├── CLAUDE.md # Symlink to AGENTS.md (git ignored) └── web/ ├── AGENTS.md # App-specific instructions └── CLAUDE.md # Symlink to AGENTS.md (git ignored)Content Update Examples
Before Migration
# CLAUDE.md This file provides guidance to Claude Code (claude.ai/code) when working with code in this repository.After Migration
# AGENTS.md This file provides guidance to AI agents when working with code in this repository.Verification Commands
Verify the migration worked correctly:
# Check all AGENTS.md files exist find . -name "AGENTS.md" -type f # Verify symlinks are created find . -name "CLAUDE.md" -type l # Check symlinks point to correct files find . -name "CLAUDE.md" -type l -exec ls -la {} \; # Verify content is agent-agnostic grep -r "Claude Code (claude.ai/code)" . --include="*.md" | grep AGENTS.mdMaintenance
Adding New AGENTS.md Files
When you add new AGENTS.md files, run the symlink setup script:
./utils/setup-claude-symlinks.shChecking Symlink Status
# List all symlinks find . -name "CLAUDE.md" -type l -exec ls -la {} \; # Check for broken symlinks find . -name "CLAUDE.md" -type l ! -exec test -e {} \; -printBenefits of This Approach
- Backward Compatibility: Existing tools expecting CLAUDE.md files continue to work
- Git Clean: CLAUDE.md files are not tracked in version control
- Automatic Sync: Symlinks ensure CLAUDE.md always matches AGENTS.md
- Easy Maintenance: Single script handles all symlink creation/updates
- Open Standard: Future-proof with the open AGENTS.md standard
Troubleshooting
Broken Symlinks
# Remove all CLAUDE.md symlinks and recreate find . -name "CLAUDE.md" -type l -delete ./utils/setup-claude-symlinks.shPermission Issues
# Make sure script is executable chmod +x utils/setup-claude-symlinks.shThis migration preserves all existing functionality while adopting the open AGENTS.md standard for better interoperability.
-
Typed languages are better suited for vibecoding
My >10 year old programming habits have changed since Claude Code launched. Python is less likely to be my go-to language for new projects anymore. I am managing projects in languages I am not fluent in—TypeScript, Rust and Go—and seem to be doing pretty well.
It seems that typed, compiled, etc. languages are better suited for vibecoding, because of the safety guarantees. This is unsurprising in hindsight, but it was counterintuitive because by default I “vibed” projects into existence in Python since forever.
Paradoxically, after a certain size of project, I can move faster and safer with e.g. Claude Code + Rust, compared to Claude Code + Python, despite the low-levelness of the code1. This is possible purely because of AI tools.
For example, I refactored large chunks of our TypeScript frontend code at TextCortex. Claude Code runs
tscafter finishing each task and ensures that the code compiles before committing. This let me move much faster compared to how I would have done it in Python, which does not provide compile-time guarantees. I am amazed every time how my 3-5k line diffs created in a few hours don’t end up breaking anything, and instead even increase stability.LLMs are leaky abstractions, sure. But they now work well enough so that they solve the problem Python solved for me (fast prototyping), without the disadvantages of Python (lower safety guarantees, slowness, ambiguity2).
Because of this, I predict a decrease in Python adoption in companies, specifically for production deployments, even though I like it so much.
-
Workaround for Claude Code running `python` instead of `uv`
uv is now the de facto default Python package manager. I have already deleted all
pythons from my system except for the one that has to be installed for other packages inbrew.Unfortunately, Claude Code often ignores instructions in
CLAUDE.mdfiles to useuv run pythoninstead of plainpythoncommands. Even with clear documentation stating “always use uv”, Claude Code will attempt to runpythondirectly, leading to “command not found” errors in projects that rely on uv for Python environment management.The built-in Claude Code hooks and environment variable settings also don’t reliably solve this issue due to shell context limitations.
The reason is that Claude (and most other AI models) take time to catch up to such changes, because their learning horizon is longer, up to months to years. Somebody will need to include this information explicitly in the training data.
Until then, we can prevent wasting tokens by mapping
pythonandpython3touv.I personally don’t want to map these globally, because a lot of other packages might depend on system installed
pythons, likebrewpackages,gcloudCLI and so on.Because of that, I map them at the project level, using direnv:
An OK-ish solution: direnv + dynamic wrapper scripts
We can force Claude Code (and any developer) to use
uv run pythonby dynamically creating wrapper scripts in a.envrcfile that direnv automatically loads when entering the project directory.This will override
pythonandpython3to map touv run python, and also print a nice message to the model:Use "uv run python ..." instead of "python ..." idiot.This is probably not the best solution, but it is a solution. Feel free to suggest a better one.
Step 1: Install direnv
# macOS brew install direnv # Ubuntu/Debian sudo apt install direnv # Add to your shell (bash/zsh) echo 'eval "$(direnv hook zsh)"' >> ~/.zshrc # or ~/.bashrc source ~/.zshrc # or restart terminalStep 2: Setup direnv with dynamic wrapper scripts
# Create .envrc file in project root cat > .envrc << 'EOF' #!/bin/bash # Create temporary bin directory for python overrides TEMP_BIN_DIR="$PWD/.direnv/bin" mkdir -p "$TEMP_BIN_DIR" # Create python wrapper scripts cat > "$TEMP_BIN_DIR/python" << 'INNER_EOF' #!/bin/bash echo "Use \"uv run python ...\" instead of \"python ...\" idiot" exec uv run python "$@" INNER_EOF cat > "$TEMP_BIN_DIR/python3" << 'INNER_EOF' #!/bin/bash echo "Use \"uv run python ...\" instead of \"python3 ...\" idiot" exec uv run python "$@" INNER_EOF # Make them executable chmod +x "$TEMP_BIN_DIR/python" "$TEMP_BIN_DIR/python3" # Add to PATH export PATH="$TEMP_BIN_DIR:$PATH" EOF # Allow direnv to load this configuration direnv allowStep 3: Update .gitignore
# Add direnv generated files to .gitignore echo "# direnv generated files" >> .gitignore echo ".direnv/" >> .gitignoreStep 4: Update documentation
Add to your
CLAUDE.mdsomething like this:## Python Package Management with uv **IMPORTANT**: This project uses `uv` as the Python package manager. ALWAYS use `uv` instead of `pip` or `python` directly. DO NOT RUN: ```bash python my_script.py # OR chmod +x my_script.py ./my_script.py ``` INSTEAD, RUN: ```bash uv run my_script.py ``` ### Key uv Commands - **Run Python code**: `uv run <script.py>` (NOT `python <script.py>`) - **Run module**: `uv run -m <module>` (e.g., `uv run -m pytest`) - **Add dependencies**: `uv add <package>` (e.g., `uv add requests`) - **Add dev dependencies**: `uv add --dev <package>` - **Remove dependencies**: `uv remove <package>` - **Install all dependencies**: `uv sync` - **Update lock file**: `uv lock` - **Run with specific package**: `uv run --with <package> <command>`How It Works
- direnv automatically loads
.envrcwhen youcdinto the project directory .envrcdynamically creates executable wrapper scripts in.direnv/bin/- Scripts display a helpful message and redirect to
uv run python .direnv/bin/is prepended to PATH, overriding system python commands- Works for any shell session in the directory (Claude Code, terminal, IDE)
To see if it works:
cd your-project/ python -c "print('Hello World')" # Shows message, uses uv python3 --version # Shows message, uses uvLet me know if this doesn’t work for you, or if you find a better solution.
- direnv automatically loads
-
Day 47 of Claude Code god mode
I started using Claude Code on May 18th, 2025. I had previously given it a chance back in February, but I had immediately WTF’d after a simple task cost 5 USD back then. When Anthropic announced their 100 USD flat plan in May, I jumped ship as soon as I could.1
It’s not an overstatement that my life has drastically changed since then. I can’t post or blog anything anymore, because I am busy working every day on ideas, at TextCortex, and on side projects. I now sleep regularly 1-2 hours less than I used to and my sleep schedule has shifted around 2 hours.
But more importantly, I feel exhilaration that I have never felt as a developer before. I just talk to my computer using a speech to text tool (Wispr Flow), and my thoughts turn into code close to real time. I feel like I have enabled god mode IRL. We are truly living in a time where imagination is the only remaining bottleneck.
Things I have implemented using Claude Code
TextCortex Monorepo
The most important contribution, I merged our backend, frontend and docs repos into a single monorepo in less than 1 day, with all CI/CD and automation. This lets us use our entire code and documentation context while triggering AI agents.
We can now tag @claude in issues, and it creates PRs. Non-developers have started to make contributions to the codebase and fix bugs. Our organization speed has increased drastically in a matter of days. I will write more about this in a future post.
JSON-DOC TypeScript renderer
JSON-DOC is a file format we are developing at TextCortex. I implemented the browser viewer for the format in 1 workday, in a language I am not fluent in. It was a rough first draft, but the architecture was correct and our frontend team could then take it over and polish it. Without Claude Code, I predict it would have taken at least 2-3 weeks of my time to take it to that level.
Claude Code PR Autodoc Action
We are not using this anymore, but it’s a GitHub Action that triggers in every PR and adds documentation about that PR to the repo.
Claude Code Sandbox
Still work-in-progress, but it is supposed to give you an OpenAI Codex like experience with running Claude Code locally on your own machine. We have big plans for this.
TextCortex Agentic RAG implementation
The next version of our product, I revamped our chat engine completely to implement agentic RAG. Since our frontend had long running issues, I had to recreate our chat UI from scratch, again in 1 day. Will be rolled out in a few weeks, so I cannot write about it yet.
Fixed i18n
I had a system in mind for auto-translating strings in a codebase for 2 years, when GPT-4 came out. I finally implemented that in 1 day. We had previously used DeepL which did some really stupid mistakes like translating “Disabled” (in the computer sense) as “behindert” in German, which means r…ded, or “Tenant” (enterprise software) as “Mieter” (renter of a real estate). The new system generates a context for each string based on the surrounding code, which is then used to translate the string to all the different languages. There is truly no point in paying for a SaaS for i18n anymore, when you can automate it with GitHub Actions and ship it statically.2
Tackling small-to-mid-size tasks without context switching
Perhaps the most important effect of agentic development is that it lets you do all the things you wanted to, but couldn’t before, because it was too big of a context switch.
There are certain parts of a codebase that require utmost attention, like when you are designing a data model, the API endpoint schemas, and so on. Mostly backend. But once you know your backend is good enough, you can just rip away on the frontend side with Claude Code, because you know your business data and logic is safe.
I have finished so many of these that it would make this post too long. To give one example, I implemented a Discord bot that we can use to download whole threads, so that we can embed it in the monorepo or create GitHub issues automatically.
Side projects
My performance on my side projects has also increased a lot. I am able to ship in 1 weekend day close to 2 weeks worth of dev-work. Thanks to Claude Code, I was able to ship my new app Horse. It’s like an AI personal trainer, but it only counts your push-ups for now. But even that was a complex enough computer vision task.
I had previously only written the Python algo for detecting push-ups. Claude Code let me develop the backend, frontend and the low-level engine in Rust, over the course of 2-3 weekends.
I knew nothing about cross-compiling Rust code to iOS, yet I was able to do the whole thing, FFI and all, in 20 minutes, which worked out of the box. Important takeaway: AI makes it incredibly easy to port well-tested codebases to different languages. I predict an increased rate of Rust-ification of open source projects.
You can see more about it on my sports Instagram here.
It’s all about completing the loop
Agentic workflows work best when you have a good verifier (like tests) which lets you create a good feedback loop. This might be the compiler output, a Playwright MCP server, running
pytest, spinning up a local server and making a request, and so on.Once you complete the loop, you can just let AI rip on it, and come back to a finished result after a few minutes or hours.
Swearing at AI
I have developed a new and ingrained habit of swearing at Claude Code, in the past couple of weeks. I frequently call it “idiot”, “r…d”, “absolute f…g moron” and so on. With increasing speed comes increasing impatience, and frustration when the agent does not get something despite having the right context.
I think there is something deeply psychological about feeling these kind of emotions towards AI. I know it’s an entity that does not retain memory or learn as a human does, but I still insult it when it fails at a task. I feel like it mostly works, but I have not done any scientific experiments to prove it.
The empathic reader should be aware that emotional reactions to AI reveal more about one’s own psychological state than the AI’s.
On Claude Code skeptics
Claude Code is a great litmus test to detect whoever is a deadweight at a company. If your employees cannot learn to use Claude Code to do productive work, you should most likely fire them. It’s not about the product or Anthropic itself, but the upcoming agentic development paradigm. Dario Amodei was not bluffing when he said that a white collar bloodbath is coming.
I have since then introduced multiple people to Claude Code, all good developers. All of them were initially skeptical, but the next day all of them texted me “wow”-like messages. The fire is spreading.
The 100 USD plan was initially the main obstacle to people trying it out, but now it’s available in the 17 USD plan, so I expect to see very rapid adoption in the following months.
I got done in 47 days more work than I previously did in 6-12 months. I am curious how TextCortex will look in 6 months from now.
-
I previously had the insight that Claude Code would perform better than Cursor, because the model providers have control over what tool data to include in the dataset, whereas Cursor is approaching the model as an outsider and trying to do trial and error on what kind of interfaces the model would be good at. ↩
-
Disclaimer, our founder Jay had already done work to use GPT-4o for automating translations, what I added on top was the context generation and improvements in automation. ↩
-
-
Predictions by Anthropic Researchers
Dwarkesh Patel has recently interviewed Sholto Douglas and Trenton Bricken for a second time, and the podcast is very enlightening in terms of how the big AI labs think in terms of their economic strategy:
(Clicking will start the video around the 1hr mark, the part that is relevant to this post.)
According to Sholto and Trenton, the following have been largely “solved” by now:
- Advanced math/programming:
- “Math and competitive programming fell first.” (Sholto)
- Routine online interactions:
- “Flight booking is totally solved.” (Sholto)
- Successfully “planning a camping trip,” navigating complicated websites. (Trenton)
And below are their predictions for what will be solved by next year, around May 2026:
- Reliable web/software automation:
- Photoshop edits with sequential effects: “Totally.” (Sholto)
- Handling complex site interactions (e.g., managing cookies, navigating tricky interfaces): “If you gave it one person-month of effort, then it would be solved.” (Sholto)
And below are what they predict will probably not be solved by next year:
- Fully autonomous, high-trust tasks:
- “I don’t think it’ll be able to autonomously do your taxes with a high degree of trust.” (Sholto)
- Generalized tax preparation:
- “It will get the taxes wrong… If I went to you and I was like, ‘I want you to do everyone’s taxes in America,’ what percentage of them are you going to fuck up?” (Sholto)
- Models’ self-awareness of its own reliability and confidence:
- “The unreliability and confidence stuff will be somewhat tricky, to do this all the time.” (Sholto)
I interpret this and the rest of the interview as follows:
The labs can now “solve”1 any white-collar task or job segment if they put their resources into it. From now on, it is a question of how much it would pay off.
In other words, if the labs think it will make more money to automate accounting (or any other task), then they will create benchmarks for that and start optimizing. Until now, they have mostly been optimizing for software engineering2, because of high immediate payoff.
Below are some job segments that I predict to be affected first (not Sholto or Trenton):
- Marketing & copywriting: actually the first segment that already fell. Many AI companies (including TextCortex) was initially focused on this segment. Automation in this sector will increase even more in the upcoming years.
- Customer service & support: many countries where this is outsourced to, like India, will be affected.
- Data entry, bookkeeping & accounting tasks: while it is a dream to automate bookkeeping, accounting, taxes, etc. it will most likely fall last due to regulations and low margin for fuckups.
- Paralegal & contract-review tasks: Many companies popped up to target the legal system. Current law forbids automated lawyering in the US and most of the world. It will eventually fall as well, starting first with paralegal tasks, advisory services, etc.
- Internal IT & systems administration: will be automated the fastest, because it is being optimized for under the software engineering umbrella.
- Real estate & insurance processing: related companies will see that they are able to save a lot of money with AI. There will be a lot of competitive pressure in every country once the first few players are successfully automate their processes. These will most likely be smaller players, who will disrupt incumbents.
- Product/project management (routine parts): cue recent Microsoft layoffs3, ending 600k comp. product manager positions. It is already happening, and will only accelerate.
-
Automate a considerable part of it, so that the work will turn into mainly managing AI agents. ↩
-
E.g. the SWE-Lancer benchmark by OpenAI. ↩
-
See this article. The company’s chief financial officer, Amy Hood, said on an April earnings call that the company was focused on “building high-performing teams and increasing our agility by reducing layers with fewer managers”. She also said the headcount in March was 2% higher than a year earlier, and down slightly compared with the end of last year. ↩
- Advanced math/programming:
-
SCP-3434: Istanbul Taxi Superorganism
Item #: SCP-3434
Object Class: Euclid
Special Containment Procedures: SCP-3434 cannot be fully contained due to its diffuse nature and integration into civilian infrastructure. Foundation agents embedded within Istanbul’s Transportation Coordination Center (UKOME) are to monitor taxi activity patterns for anomalous behavior spikes. Mobile Task Force ████ has been assigned to investigate and neutralize extreme manifestations within SCP-3434.
Individuals exhibiting temporal disorientation after utilizing taxi services in Istanbul should be administered Class-B amnestics and monitored for 72 hours post-incident. Under no circumstances should Foundation personnel utilize SCP-3434 instances for transportation unless authorized for testing purposes.
Description: SCP-3434 is a defensive superorganism manifesting as a collective consciousness within approximately 17,000 taxi vehicles operating in Istanbul, Turkey. Individual taxis display coordinated behaviors atypical for independently operated vehicles, functioning as a distributed neural network despite lacking any detectable communication infrastructure.
SCP-3434 exhibits three primary anomalous properties:
-
Temporal Distortion: Passengers experience significant time dilation upon entering affected vehicles. Discrepancies between perceived and actual elapsed time range from minutes to several hours, with no correlation to distance traveled or traffic conditions. GPS data from affected rides consistently shows corruption or retroactive alteration.
-
Economic Predation: The collective demonstrates uncanny ability to extract maximum possible fare from each passenger through coordinated deception, including meter “malfunctions,” route manipulation, and inexplicable knowledge of passenger financial status. Credit card readers experience a ████ failure rate exclusively for non-local passengers.
-
Territorial Defense: SCP-3434 displays extreme hostility toward competing transportation services. Since 2011, all attempts by ridesharing platforms to establish operations have failed due to coordinated interference including simultaneous vehicle failures, GPS anomalies affecting only competitor vehicles, and physical blockades formed with millisecond precision.
Incident Log 3434-A: On 14/09/2024, Agent ████ ████ was assigned to investigate temporal anomalies reported in the Beyoğlu district. Agent ████ entered taxi license plate 34 T ████ at 14:22 local time for what GPS tracking indicated would be a 12-minute journey to Taksim Square.
Agent ████ emerged at 14:34 local time at the intended destination. However, biological markers and personal chronometer readings indicated Agent ████ had experienced approximately 8 months of subjective time. Physical examination confirmed accelerated aging consistent with temporal displacement. Agent exhibited severe psychological distress and no memory of the elapsed period.
The taxi driver, when questioned, displayed no anomalous knowledge and insisted the journey had taken “only 15 minutes, very fast, no traffic.” The meter showed a fare of ████, approximately 40 times the standard rate. Driver claimed this was “normal price, weekend rates.”
Post-incident analysis of the taxi revealed no anomalous materials or modifications. The vehicle continues to operate within the SCP-3434 network without further documented incidents.
Interview Log:
Interviewed: ███████ (Driver of taxi license plate 34 T ████)
Dr. ████: How long have you been driving this route?
███████: Route? What route? The city tells us where to go.
Dr. ████: The city?
███████: You wouldn’t understand. You’re not connected. But we all hear it. Every corner, every passenger, every lira. We are Istanbul, and Istanbul is us.
Dr. ████: Can you elaborate on-
███████: Your hotel is 20 minutes away. It will take us an hour. The meter is broken. Only cash.
Addendum 3434-1: Research into historical records reveals references to unusual taxi behavior in Istanbul dating back to 1942, coinciding with the introduction of the first motorized taxi services. The phenomenon appears to have evolved in complexity with the city’s growth.
Addendum 3434-2: Foundation economists estimate SCP-3434’s collective annual revenue exceeds ████ million Turkish Lira, with 0% reported to tax authorities. Attempts to audit individual drivers result in temporary disappearance of all documentation and the spontaneous malfunction of all electronic devices within a 10-meter radius.
Note from Site Director: “Under no circumstances should personnel attempt to ‘outsmart’ SCP-3434 by pretending to be locals. They already know. They always know.”
I am on vacation, so here is a little bit of fun with some grounded fiction.
-
-
Auto-generating pull request documentation with Claude Code and GitHub Actions
Anthropic has just released a GitHub Action for integrating Claude Code into your GitHub repo. This lets you do very cool things, like automatically generating documentation for your pull requests after you merge them. Skip to the next section to learn how to install it in your repo.
Since Claude Code is envisioned to be a basic Unix utility, albeit a very smart one, it is very easy to use it in GitHub Actions. The action is very simple:
- It runs after a pull request is merged.
- It uses Claude Code to generate a documentation for the pull request.
- It creates a new pull request with the documentation.
This is super useful, because it saves context about the repo into the repo itself. The documentation generated this way is very useful for not only humans, but also for AI agents. A future AI can then learn about what was done in a certain PR, without looking at Git history, issues or PRs. In other words, it lets you automatically break GitHub’s walled garden, using GitHub’s native features 1.
Installation
- Save your
ANTHROPIC_API_KEYas a secret in the repo you want to install this action. You can find this page inhttps://github.com/<your-username-or-org-name>/<your-repo-name>/settings/secrets. If you have already installed Claude Code in your repo by running/install-github-appin Claude Code, you can skip this step. - Save the following as
.github/workflows/claude-code-pr-autodoc.ymlin your repo:
name: Auto-generate PR Documentation on: pull_request: types: [closed] branches: - main jobs: generate-documentation: # Only run when PR is merged and not created by bots # This prevents infinite loops and saves compute resources if: | github.event.pull_request.merged == true && github.event.pull_request.user.type != 'Bot' && !startsWith(github.event.pull_request.title, 'docs: Add documentation for PR') runs-on: ubuntu-latest permissions: contents: write pull-requests: write id-token: write steps: - uses: textcortex/claude-code-pr-autodoc-action@v1 with: anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}There are bunch of parameters you can configure, like minimum number of diff lines that will trigger the action, or the directory where the documentation will be saved. To learn about how to configure these parameters, visit the GitHub Action repo itself: textcortex/claude-code-pr-autodoc-action.
Usage
After you merge a PR, the action will automatically generate documentation for it and open a new PR with the documentation. You can then simply merge this PR, and the documentation will be added to the repo, by default in the
docs/prsdirectory.Thoughts on Claude Code
I was curious why Anthropic had not released an agentic coding app on Claude.ai, and this might be the reason why.
The main Claude Code action is not limited to creating PR documentation. You tag
@claude, in any comment, and Claude Code will answer questions or implement the changes you ask for.While OpenAI and Google is busy creating sloppy chat UXs for agentic coding (Codex and Jules) and forcing developers to work on their site, Anthropic is taking Claude directly to the developers’ feet and integrate Claude Code into GitHub.
Ask any question in a GitHub PR, and Claude Code will answer your questions, implement requested changes, fix bugs, typos, styling issues.
You don’t need to go to code Codex or Jules website to follow up on your task. Why should you? Developer UX is already “solved” (well yes but no).
Anthropic bets on GitHub, what already works. That’s why they have probably already won developers.
The only problem is that it costs a little bit too much for now.
In the long run, I am not sure if GitHub will be enough for following up async agentic coding tasks in parallel. Anthropic might soon launch their own agentic coding app. GitHub itself might evolve and create a better real-time chat UX. But unless that UX really blows my mind, I will most likely just hang out at GitHub. If you are an insider, or you know what Anthropic is planning to do, please let us know in the HN comment section.
claude-code-pr-autodoc-action was developed by me, 80% using Claude Code and 20% using Cursor with Claude Opus 4.
-
Working on the weekend
Certain types of work are best done in one go, instead of being split into separate sessions. These are the types of work where it is more or less clear what needs to be done, and the only thing left is execution. In such cases, the only option is sometimes to work over the weekend (or lock yourself in a room without communication), in order not to be interrupted by people.
There was a 2-year old tech debt at TextCortex backend. Resolving it required a major refactor that we wanted to do since one year. I finally paid that tech debt 2 weeks ago, by working a cumulative of 24 hours over 2 days, creating a diff of 5-6k lines of Python code and 90 commits over 105 files.
The result:
- No more request latencies or dropped requests.
- Much faster responses.
- 50% reduction in Cloud Run costs.
- Better memory and CPU utilization.
- Faster startup times.
I’ve broken some eggs while making this omelette—bugs were introduced and fixed. I could finish the task because I had complete code ownership and worked over the weekend without blocking other people. Stuff like this can only happen in startups, or startup-like environments.
Credit also goes to our backend engineer Tugberk Ayar for helping stress testing the new code.
-
Don't delete to fix
If you are a developer, you are annoyed by this. If you are a user, you were most likely guilty of this. I am talking reporting that something is broken, AND deleting it.
This happened to me too many times: User experiences a bug with an object. Their first instinct is to delete it, and create a new one. They report it. I cannot reproduce and fix it.
If you have a car and it stops working, you don’t throw it in the trash and then call the service to fix it. But when it comes to software, which has virtually zero cost of creation, this behavior somehow becomes widespread.
This is similar to other user behavior like smashing the mouse and keys when a computer gets stuck. It is physically impossible for such an action to speed up a digital process, but many of us instinctively do it.1 Deleting to fix is a similar behavior, which I suspect got ingrained by crappy Microsoft software. The default way of fixing Windows machines is to “format the disk”, and reinstalling Windows. Nobody asks, “why do I have to start from scratch?”. The “End User” deletes to fix by default, because the End User does not understand. “Have you tried turning it off and on again?”
The concept of “Mechanical Sympathy” is relevant: having an understanding of how a tool works, being able to feel inside the box. We can extend this to “Developer Sympathy”: having an understanding of how a software was developed, how it changes over time, how it can break, how it can be fixed.
Any troubleshooting must be done in a non-destructive way. When a user deletes an object, two things can happen: it is hard-deleted, which makes the issue impossible to reproduce. If it is instead soft-deleted, it might be restored, but developers will mostly not bother, depending on the issue.
The users cannot be expected to care either. Their time is valuable. They deserve things that “just work”. So we need to come up with other workarounds:
- Everything should be soft-deleted by default in non-sensitive contexts, and should be easy to restore.
- Any reporting form should include instructions to warn the user against deleting.
- Even better, the reporting should happen through an internal system, and should automatically block deletion once a ticket is created.
-
I can’t remember the name of this inequality or find it online, please comment on the Hacker News thread if you know what it’s called. ↩
-
Warmup and cooldown
One common thing about sports noobs1 is that they don’t warm up before and cool down after an exercise. They might be convinced that it is not necessary, and they also don’t know how to do it properly. They might complain from prolonged injuries, like joint pain.
The thing about serious exercise, be it strength training, running, stretching, and so on, is that you are pushing your body beyond its limits. This is called overload. If you do this over a long term period, it is called progressive overload. This is what gives you real power, real speed, ability to do middle splits, and so on.
When you start with an intention to do serious exercise, and you immediately start loading heavily without warming up, you will get injured very quickly and have to take days or weeks of break.
For example, if you directly jump at the heaviest dumbbells you can lift and start doing bicep curls the moment you get to the gym, you will destroy your wrists, elbows, and/or shoulders. You will not realize it immediately. After a few weeks or months, you will start feeling pain, and will have to stop training altogether.
A common thing about noobs who injure themselves early on is that they have fierce willpower, but they don’t listen to their bodies, and they don’t have a good understanding of their current capabilities. They have an idea of where they want to be, and they are prepared to push towards it. But because they are impatient, don’t have good mind-body connection, and don’t know how to plan for long-term progress, they push themselves too far too fast.2
Being able to sustain injury-free long-term practice is a skill in itself, and perhaps the most underrated among non-professional gym-goers and athletes. There is no fancy Latin/Greek name for it, like there is for other things like cardio, plyometrics, hypertrophy, and so on. A crucial idea is missing from mainstream fitness.
Therefore, I coin the term and define it here:
Parathletics: The practices that let you successfully sustain injury-free long-term practice of a physical activity.
The word comes from Greek παρά (para-) meaning “beside/alongside” and ἀθλητικός (athlētikós) meaning “athletic”, “relating to an athlete”3.
Two main parathletic practices are warmup and cooldown.
Before starting a workout, warm up your body by moving your every joint, from the neck to the toes, through its range of motion and increase the blood flow to your muscles. If you plan to do heavy loads, build up to them with lighter weights first.
After finishing a workout, cool down your body by stretching every joint and muscle group, and especially the ones you just trained. The more hardcore your workout, the more you need to stretch.
Skipping these will result in injury, decrease in mobility, and delay in reaching your goals.
-
Including me before I started to receive proper training. ↩
-
Me running in 2017. I tried to lower my pace below 5:00 per km too quickly, less than a year after I started running. I had to stop because my heart fatigued for 2-3 days after running, with increased troponin levels in my blood. I never got serious about running since then. ↩
-
Which eventually comes from ἆθλος (âthlos) which was used to mean “contest”, “prize”, “game”, “struggle” and similar things. ↩
-
-
Satya Nadella on knowledge work
Satya Nadella, shares his thinking on the future of knowledge work (link to YouTube for those who don’t want to read) on Dwarkesh Patel Podcast. He thinks that white collar work will become more like factory work, with AI agents used for end-to-end optimization.
Dwarkesh: Even when you have working agents, even when you have things that can do remote work for you, with all the compliance and with all the inherent bottlenecks, is that going to be a big bottleneck, or is that going to move past pretty fast?
Satya: It is going to be a real challenge because the real issue is change management or process change. Here’s an interesting thing: one of the analogies I use is, just imagine how a multinational corporation like us did forecasts pre-PC, and email, and spreadsheets. Faxes went around. Somebody then got those faxes and did an interoffice memo that then went around, and people entered numbers, and then ultimately a forecast came, maybe just in time for the next quarter.
Then somebody said, “Hey, I’m just going to take an Excel spreadsheet, put it in email, send it around. People will go edit it, and I’ll have a forecast.” So, the entire forecasting business process changed because the work artifact and the workflow changed.
That is what needs to happen with AI being introduced into knowledge work. In fact, when we think about all these agents, the fundamental thing is there’s a new work and workflow.
For example, even prepping for our podcast, I go to my copilot and I say, “Hey, I’m going to talk to Dwarkesh about our quantum announcement and this new model that we built for game generation. Give me a summary of all the stuff that I should read up on before going.” It knew the two Nature papers, it took that. I even said, “Hey, go give it to me in a podcast format.” And so, it even did a nice job of two of us chatting about it.
So that became—and in fact, then I shared it with my team. I took it and put it into Pages, which is our artifact, and then shared. So the new workflow for me is I think with AI and work with my colleagues.
That’s a fundamental change management of everyone who’s doing knowledge work, suddenly figuring out these new patterns of “How am I going to get my knowledge work done in new ways?” That is going to take time. It’s going to be something like in sales, and in finance, and supply chain.
For an incumbent, I think that this is going to be one of those things where—you know, let’s take one of the analogies I like to use is what manufacturers did with Lean. I love that because, in some sense, if you look at it, Lean became a methodology of how one could take an end-to-end process in manufacturing and become more efficient. It’s that continuous improvement, which is reduce waste and increase value.
That’s what’s going to come to knowledge. This is like Lean for knowledge work, in particular. And that’s going to be the hard work of management teams and individuals who are doing knowledge work, and that’s going to take its time.
Dwarkesh: Can I ask you just briefly about that analogy? One of the things Lean did is physically transform what a factory floor looks like. It revealed bottlenecks that people didn’t realize until you’re really paying attention to the processes and workflows.
You mentioned briefly what your own workflow—how your own workflow has changed as a result of AIs. I’m curious if we can add more color to what will it be like to run a big company when you have these AI agents that are getting smarter and smarter over time?
Satya: It’s interesting you ask that. I was thinking, for example, today if I look at it, we are very email heavy. I get in in the morning, and I’m like, man my inbox is full, and I’m responding, and so I can’t wait for some of these Copilot agents to automatically populate my drafts so that I can start reviewing and sending.
But I already have in Copilot at least ten agents, which I query them different things for different tasks. I feel like there’s a new inbox that’s going to get created, which is my millions of agents that I’m working with will have to invoke some exceptions to me, notifications to me, ask for instructions.
So at least what I’m thinking is that there’s a new scaffolding, which is the agent manager. It’s not just a chat interface. I need a smarter thing than a chat interface to manage all the agents and their dialogue.
That’s why I think of this Copilot, as the UI for AI, is a big, big deal. Each of us is going to have it. So basically, think of it as: there is knowledge work, and there’s a knowledge worker. The knowledge work may be done by many, many agents, but you still have a knowledge worker who is dealing with all the knowledge workers. And that, I think, is the interface that one has to build.
If you got confused for a second there like me, Lean here is not referring to the open source proof assistant but lean manufacturing.
Whereas it is nice to dream, the actual sentiment on Microsoft Copilot and AI integration in Microsoft Office is along the following lines:
I have written about this in a previous post:
There is going to be an AI-native “Microsoft Office”, and it will not be created by Microsoft. Copilot is not it, and Microsoft knows it. Boiling tar won’t turn it into sugar.
-
Monetize AI, not the editor
A certain characteristic of legacy desktop apps, like Microsoft Office, Autodesk AutoCAD, Adobe Photoshop and so on, are that they have crappy proprietary file formats. In 2025, we barely have reliable, fully-supported open source libraries to read and write .DOCX, .XLSX, .PPTX,1 .DWG, .PSD and so on, even though related products keep making billions in revenue.
The reason is simple: Moat through obfuscation.
The business model for these products when they first appeared in the 1980s and 1990s was to sell the compiled binaries for a one-time fee. This was pre-internet, before Software-as-a-Service (SaaS) could provide a reliable revenue stream. Having a standardized file format would have meant giving competitors a chance to develop a superior product and take over the market. So they went the other way and made sure their file formats would only be read by their own products, for example by changing the specifications in each new version. To keep their businesses safe, they prevented interoperability of entire modalities of human work, and by doing so, they harmed the entire world’s economy for decades.2
Can you blame them? The only thing they could monetize was the editor. Office 365 and Adobe Creative Cloud has since implemented a SaaS model to capitalize even more, but the file formats are still crap—a vestige of the old business model.3
But finally, a revolution is underway. This might all change.
None of these products were designed to be used by developers. They were designed to be used by the “End User”. According to Microsoft, the End User does not care about elegance or consistency in design.4 The End User could never understand version control. The End User sends emails back and forth with extensions such as
v1.final.docx,v1.final.final.docx. Until recently, the End User was the main customer of software.However, we have a new customer in the market: AI. The average AI model is very different than Microsoft’s stereotypical End User. They can code. In fact, models have to code, or at least encode structured data like a function call JSON, in order to have agency. Yes, we will also have AIs using computers directly like OpenAI’s Operator, but it is generally more straightforward to use an API for an AI model than to use an emulated desktop.
We will soon witness AI models surpass the human End User in terms of economic production. Tyler Cowen5, Andrej Karpathy6 and others are convinced that we should plan for a future where AIs are major economic actors.
“The models, they just want to learn”. The models also want intuitive APIs and simple file formats. The models abhor unnecessary complexity. If you have developed a RAG pipeline for Excel files, you know what I mean.
If AI creates pressure to replace legacy file formats, then what can companies monetize if not the editor? The answer is the AI itself. Serve a proprietary model, serve an open source model, charge per tokens, charge for inference, charge for kilowatt-hours, charge for agent-hours/days. The business model will differ from industry to industry, but the trend is clear: value will be more and more linked to AI compute, and less and less to Software 1.07.
There is now a huge opportunity in the market to create better software, that follow the File over App philosophy:
if you want to create digital artifacts that last, they must be files you can control, in formats that are easy to retrieve and read. Use tools that give you this freedom.
We already observe that AI systems work drastically more efficiently if they are granted such freedom. There is a reason why OpenAI based ChatGPT’s Code Interpreter on Python and not on Visual Basic, or why it chose to render equations using LaTeX instead of Office Math Markup Language (OMML)8. Open and widespread formats are more represented in the datasets, and the models can output them more correctly.
There is going to be an AI-native “Microsoft Office”, and it will not be created by Microsoft. Copilot is not it, and Microsoft knows it. Boiling tar won’t turn it into sugar. Same for other Adobe, Autodesk and other creators of clutter.
Internet Explorer’s 2009 YouTube moment is coming for legacy desktop apps, and it will be glorious.
-
Yes, Microsoft’s newer Office formats .DOCX, .XLSX, .PPTX are built on OOXML (Office Open XML), an ISO standard. But can all of these formats be rendered by open source libraries exactly as they appear in Microsoft Office, in an efficient way? Can I use anything other than Microsoft Office to convert these into PDF, with 100% guarantee that the formatting will be preserved? The answer is no, there will still be inconsistencies here and there. This was intentional. A moment of silence for the poor souls in late 2000s Google who were tasked with rendering Office files in Gmail and Google Docs. ↩
-
For a recent example of how monopolies create inferior products, imagine the efficiency increase and surprise when Apple Silicon (M1) first came out, and how ARM is now the norm for all new laptops. We could have had such efficiency a decade before, if not for Intel. ↩
-
On the other end of the spectrum, we have companies that are valued in the billions, despite using standardized open source standards: MongoDB uses Binary JSON (BSON), Elasticsearch uses JSON, Wordpress (Automattic) uses MySQL/PHP/HTML,CSS, and so on. ↩
-
Companies like Notion beg to differ: Software should be beautiful. People apparently have a pocket for beauty. ↩
-
Traditional pre-AI software, as opposed to Software 2.0. ↩
-
Long forgotten format for Microsoft Equation Editor. ↩
-
-
Calling strangers uncle and auntie
Cultures can be categorized across many axes, and one of them is whether you can call an older male stranger uncle or female stranger auntie. For example, calling a shopkeeper uncle might be sympathetic in Singapore, whereas doing the same in Germany (Onkel) might get a negative reaction: “I’m not your uncle”.
This is similar to calling a stranger bro. In social science, this is called fictive kinship, social ties that are not based on blood relations. For readers which come from such cultures, this does not need an explanation. But for other readers, this might be a weird concept. Why would you call a stranger uncle or auntie?
Hover over the countries below to see which ones use uncle/auntie terms:
Countries that use uncle/auntie terms as fictive kinship.
If you notice any errors, you can submit a pull request on the repo osolmaz/crowdsource.Note that fictive kinship can also have different levels:
-
Level 0: Blood relatives only. “Uncle”/“Auntie” is strictly for real uncles/aunts (by blood or marriage). No fictive use.
-
Level 1: Close non-relatives. Used for family friends, “uncle” or “auntie” is an honorary title but not for random people.
-
Level 2: Casual acquaintances. Used more widely for neighbors, family friends, or community members you vaguely know, but typically not for an absolute stranger.
-
Level 3: Total strangers. Used even for someone you’ve just met: a shopkeeper, taxi driver, or older passerby.
Many cultures fall somewhere between these levels and it’s not always black and white. Where possible, I’ve simplified it to the most typical usage.
Ommerism and social cohesion
The thought first occurred to me when I visited Singapore and heard people use uncle and auntie. Here were people speaking English, but it felt like they were speaking Turkish (my mother tongue).
The cultural difference is apparent to me as well since I started living in Germany. People here are more lonely, strangers distrust each other more, and there are no implicit social ties. I guess this holds for the entire Anglo/Germanic culture, including the US and the commonwealth.
Don’t get me wrong, people in Turkey distrust each other as well, probably even more. It is a more dangerous country than Germany. But those dangerous strangers are still uncles. It’s weird, I know.
As far as I could tell, the phenomenon is not even sociologically that much recognized or studied. There is no specific name for it, other than being a specific form of fictive kinship. Therefore, I will name it myself: ommerism. It derives from a recently popularized gender-neutral term for an uncle or auntie, ommer.
Lack of ommerism is an indicator for a weak collective culture. Such cultures are more individualistic, familial ties are weaker and people are overall more lonely. People from such cultures could for example tweet:
It is extra ironic that ex-colonies like Singapore (ex-British), Indonesia (ex-Dutch), Philippines (ex-Spanish) etc. took their colonizers’ words for uncle/auntie and started using it this way, whereas the original cultures still do not.
Related articles
Click to expand more detailed notes on ommerism in different cultures, generated by o1:
East Asia
China (Mainland China, Hong Kong, Taiwan)
- Mandarin Chinese: Older men can be called 叔叔 (shūshu) or 大叔 (dàshū), and older women 阿姨 (āyí)—literally “uncle” and “aunt.”
- Cantonese: Common terms include 叔叔 (suk1 suk1) and 阿姨 (aa4 yi4).
- These terms are used with neighbors, parents’ friends, or sometimes older strangers as a sign of respect.
South Korea
- While there is no exact one-word translation for “uncle” or “aunt” used for strangers, 아저씨 (ajeossi) for an older male and 아줌마 (ajumma) for an older female are frequently used.
- In more affectionate or polite contexts (like someone only slightly older, perhaps a friend’s older sibling), you might hear 삼촌 (samchon, literally “uncle”) or 이모 (imo, literally “maternal aunt”) in certain familial or friendly settings. However, ajeossi and ajumma are the most common for strangers.
Japan
- おじさん (ojisan) means “uncle” (or older man), and おばさん (obasan) means “aunt” (or older woman).
- These words are often used for middle-aged adults who aren’t close relatives. However, obasan and ojisan can sometimes sound a bit casual or even rude if the person thinks they’re not that old—so usage requires some caution.
Mongolia
- Familial terms for older people exist (e.g., avga for “aunt,” avga ah for “uncle”), though usage for complete strangers varies by region or family practice. The practice is somewhat less formalized than in, say, Chinese or Korean, but it does occur in more traditional or rural settings.
Southeast Asia
Vietnam
- Common terms include chú for a slightly older man (literally “uncle”), bác for an older man or woman (technically also “uncle/aunt” but older than one’s parents), and cô or dì for an older woman (“aunt”).
- These terms are commonly used even for unrelated people in the neighborhood or community.
Thailand
- Thais typically use kinship or age-related pronouns. ป้า (pâa) means “aunt” and is used for women noticeably older than the speaker; ลุง (lung) means “uncle” for older men.
- พี่ (phîi) (“older sibling”) is also used for someone slightly older, but not as old as a parental figure.
Cambodia (Khmer)
- Kinship terms like បង (bong) (“older brother/sister”) are used for somewhat older people, but for someone older than one’s parents, ពូ (pu) (“uncle”) or មីង (ming) (“aunt”) are common.
Laos
- Similar to Thai and Khmer, Laotians use ai (“uncle”) and na (“aunt” in some contexts), though often you’ll see sibling terms like ai noy as well.
Myanmar (Burma)
- Burmese uses kinship terms such as ဦး (u) for older men (sometimes “uncle”) and ဒေါ် (daw) for older women (sometimes “aunt”). Strictly, u and daw are more like “Mr.” / “Ms.” honorifics, but in colloquial usage, people also say ဘူ (bu) or နာ် (nà) for “uncle”/“aunt” in local dialects.
Malaysia & Brunei
- In Malay, pakcik (“uncle”) and makcik (“auntie”) are used for older men and women, especially in a neighborly or informal community context.
- Ethnic Chinese or Indian communities in Malaysia may use their own respective terms (Chinese “叔叔/阿姨,” Tamil “maama/maami,” etc.).
Indonesia
- Om (from Dutch/English “oom,” meaning “uncle”) and Tante (from Dutch “tante,” meaning “aunt”) are widely used for older strangers—especially in urban areas.
- In Javanese or other local languages, there are also variations for older siblings or parent-like figures.
The Philippines
- Using Tito (uncle) and Tita (aunt) for older strangers is very common, especially if they are friends of the family or neighbors.
- Filipinos also commonly address older peers as Kuya (“older brother”) or Ate (“older sister”) when the age gap is less.
Singapore
- Given Singapore’s multicultural society, people might say “Uncle”/“Aunty” in English, or the Chinese/Malay/Tamil equivalents. It is extremely common to address older taxi drivers, shopkeepers, or neighbors as “Uncle” or “Auntie” in everyday conversation.
Timor-Leste (East Timor)
- Influenced by Indonesian and local Austronesian customs, you’ll find use of Portuguese tio/tia (“uncle/aunt”) in some contexts, or local language equivalents for older strangers.
South Asia
India
- Uncle and Aunty (often spelled “Auntie”) are widely used in Indian English for neighbors, parents’ friends, or older people in the community.
- Regional languages have their own words: e.g., in Hindi, “चाचा (chacha)” / “चाची (chachi)” or “मामा (mama)” / “मामी (mami)”; in Tamil, “மாமா (maama)” / “மாமி (maami)”; etc. Usage varies by region.
Pakistan
- Similarly, “Uncle” and “Aunty” are used in Pakistani English. In Urdu or other local languages, you might hear “चाचा (chacha)” / “چچی (chachi)” or “ماما (mama)” / “مامی (mami)” depending on whether it’s paternal or maternal in origin—often extended to unrelated elders as a sign of respect.
Bangladesh
- In Bengali, “কাকা (kaka)” / “কাকি (kaki)” or “মামা (mama)” / “মামি (mami)” might be used similarly. Among English speakers, “Uncle/Aunty” is also common.
Sri Lanka
- Both the Sinhalese and Tamil-speaking communities (as well as English speakers) use “Uncle” and “Aunty.” Local terms exist as well, like “මාමා (mama)” in Sinhalese for a maternal uncle.
Nepal & Bhutan
- In Nepal, Hindi- or Nepali-influenced usage might include “Uncle/Aunty” in English or “kaka,” “fupu,” etc. in Nepali.
- In Bhutan, kinship terms in Dzongkha may be extended politely, and English “Uncle”/“Aunty” is sometimes heard too.
The Middle East
Arabic-Speaking Countries
(Countries such as Saudi Arabia, UAE, Oman, Yemen, Kuwait, Qatar, Bahrain, Jordan, Lebanon, Syria, Palestine, Iraq, Egypt, Morocco, Tunisia, Algeria, etc.)
- Common practice is to call an older male عمّو (ʿammo) (“uncle”) or خال (khāl, “maternal uncle”), and an older female عمّة (ʿamma) or خالة (khāla, “maternal aunt”). In more casual conversation, people might just say “ʿammo” or “khalto” (aunt) for a kindly older stranger.
Turkey
- Turks often use amca (“uncle”) for older men and teyze (“aunt”) for older women, even if unrelated. You might also hear hala (paternal aunt) or dayı (maternal uncle) in certain contexts, though amca and teyze are the most common “stranger but older” usage.
Iran (Persia)
- Persian speakers sometimes use عمو (amú) (“uncle”) for an older male and خاله (khâleh) or عمه (ammeh) for an older female, though it can be more common within a neighborhood or for family friends rather than complete strangers.
Israel
- Among Arabic-speaking Israelis, the same Arabic norms apply. In Hebrew, there is less of a tradition of calling older strangers “uncle/aunt,” though familial terms may sometimes be used in casual or affectionate contexts.
Africa
In many African countries, the concept of extended family and communal child-rearing leads to frequent use of “auntie” and “uncle” (in local languages or in English/French/Portuguese). A few notable examples:
Nigeria
- It’s extremely common, in both English usage and local languages (Yoruba, Igbo, Hausa, etc.), to call older strangers or family friends Uncle or Aunty as a sign of respect.
Ghana
- In Ghanaian English and local languages (Twi, Ga, Ewe, etc.), older neighbors or close friends of parents are called “Uncle” or “Auntie.”
Kenya, Uganda, Tanzania (Swahili-speaking regions)
- “Mjomba” (uncle) or “Shangazi” (aunt) might be heard, but more often you’ll hear people simply use English “Uncle/Auntie” in urban areas. Variations exist in tribal languages.
South Africa
- Among many ethnic groups (Zulu, Xhosa, etc.), as well as in colloquial South African English, calling an unrelated elder “Uncle/Auntie” is quite normal.
Other African Nations
- From Ethiopia and Eritrea (where you might hear “Aboye” or “Emaye,” though these are more parental) to francophone Africa (where “tonton” / “tata” in French can be used for older people), the practice is widespread.
The Caribbean
Many Caribbean cultures (influenced by African, Indian, and European heritage) commonly call elders “Auntie” and “Uncle”:
- Jamaica, Trinidad & Tobago, Barbados, Grenada, etc.: It’s very common in English Creole or local usage to refer to an older neighbor or friend as “Auntie” / “Uncle.”
- In places with large Indian diaspora (e.g., Trinidad, Guyana), you’ll see Indian-style “Aunty/Uncle” usage as well, plus local creole terms.
Other Notable Mentions
- Philippine & Indian Diasporas (e.g., in the USA, Canada, UK, Middle East) continue the tradition of calling elders “Uncle/Aunty,” “Tito/Tita,” etc.
- In some communities in the Caribbean diaspora (e.g., in the UK), you’ll also hear “Uncle” or “Auntie” for older neighbors, family friends, or even community leaders.
- In parts of the Southern United States (particularly historically among African American communities), children would sometimes call an older neighbor “Aunt” or “Uncle” plus their first name—though this usage can also have historical or regional nuances.
-
-
AGI is what generates evolutionarily fit and novel information
I had this idea while taking a shower and felt that I had to share it. It most likely has flaws, so I would appreciate any feedback at [email protected]. My hunch is that it could be a stepping stone towards something more fundamental.
As the world heads towards Artificial General Intelligence—AGI—people rush to define what it is. Marcus Hutter historically described it as
AI which is able to match or exceed human intelligence in a wide class of environments
(…)
hypothetical agent that can perform virtually all intellectual tasks as well as a typical human could
(see his most recently published book)
whereas OpenAI historically described it as
a highly autonomous system that outperforms humans at most economically valuable work
and more recently, according to a The Information report
an AI system that can generate at least $100 billion in profits for OpenAI
which apparently could be the threshold at which Microsoft loses access to OpenAI models, according to the legal agreement between OpenAI and Microsoft.
Acknowledging all of this and other possible definitions, I want to introduce a definition of AGI that relates to information theory and biology, which I think could make sense:
An AGI is an autonomous system that can generate out-of-distribution (i.e. novel) information, that can survive and spread in the broader environment, at a rate higher than a human can generate.
Here, “survival” can be thought of as mimetic survival, where an idea or invention keeps getting replicated or referenced instead of being deleted or forgotten. Some pieces of information, like blog posts auto-generated for SEO purposes, can quickly vanish, are ephemeral and so recently have started being called “AI slop”. Others, such as scientific theories, math proofs, books such as Euclid’s Elements, and so on, can persist across millennia because societies find them worth copying, citing, or archiving. They are Lindy.
In that way, it is possible to paraphrase the above definition as “an autonomous system that can generate novel and Lindy information at a rate higher than a human can do”.
Like Hutter’s definition, the concept of environment is crucial for this definition. Viruses thrive in biological systems because cells and organisms replicate them. Digital viruses exploit computers. Euclid’s Elements thrives in a math-loving environment. In every case, the information’s persistence depends not just on its content but also on whether its environment considers it worth keeping. This applies to AI outputs as well: if they provide correct or valuable solutions, they tend to be stored and re-used, whereas banal or incorrect results get deleted.
The lifetime of information
Mexican cultural tradition of Día de los Muertos and the anime One Piece have a similar concept on death:
When do you think people die? Is it when a bullet from a pistol pierces their heart? (…) No! It’s when they are forgotten by others! (—Dr. Hiriluk, One Piece)
You could call this specific type of death “informational death”. A specific information, a bytestream representing an idea, a theory, a proof, a book, a blog post, etc., is “dead” when its every last copy is erased from the universe, or cannot be retrieved in any way. Therefore, it is also possible to call a specific information “alive” when it is still being copied or referenced.
So, how could we formalize the survival of information? The answer is to use survival functions, a concept used in many fields, including biology, epidemiology, and economics.
Let us assume that we have an entity, an AI, that produces a sequence of information . For each piece of information produced by the AI, we define a random lifetime . is the time until is effectively forgotten, discarded, or overwritten in the environment.
We then describe the survival function as:
the probability that is still alive (stored, referenced, or used) at time . This is independent of how many duplicates appear—we assume that at least one copy is enough to deem it alive.
In real life, survival depends on storage costs, attention spans, and the perceived value of the item. A short-lived text might disappear as soon as nobody refers to it. A revolutionary paper may endure for decades. Mathematical facts might be considered so fundamental that they become permanent fixtures of knowledge. When we speak of an AI that “naturally” produces persistent information, we are observing that correct or notable outputs often survive in their environment without the AI having to optimize explicitly for that outcome.
An expanding universe of information
In our definition above, we mention “out-of-distribution”ness, or novelty of information. This implies the existence of a distribution of information, i.e. a set of information containing all information that has ever been generated up to a certain time. We denote this set of cumulative information as for “universe”, which grows with every new information produced by the AI. Let
and then
In other words, once is added, it becomes part of the universe. Given an existing state of , we can define and calculate a “novelty score” for a new information relative to . If is basically a duplicate of existing material, its novelty score will be close to zero. If it is genuinely out-of-distribution, it would be large. Therefore, when a novel information is added to , any future copies of it will be considered in-distribution and not novel. We denote the novelty score of as .
So how could we calculate this novelty score? One way to calculate it is to use conditional Kolmogorov complexity:
where
is the length (in bits) of the shortest program that can generate , when the set is given as as a free side input, and is the universal Turing machine.
How does this relate to novelty?
Low novelty: If can be produced very easily by simply reading or slightly manipulating , then the program (which transforms into ) is small, making and hence the novelty score is low. We would say that is almost already in , or is obviously derivable from .
High novelty: If shares no meaningful pattern with , or can’t easily be derived from , the program must be large. In other words, no short set of instructions that references is enough to produce —it must encode substantial new information not present in . That means and hence the novelty score is high.
Informational fitness
We can now combine survival and novelty to formalize our informal definition of AGI-ness above. We integrate the survival function over time to the expected lifetime of information :
Therefore, for an entity which generates information over its entire service lifetime, we can compute a measure of “informational fitness” by multiplying the novelty score by the expected lifetime over all generated information:
This quantity tracks the total sum of both how novel each new piece of information an entity generates, and how long it remains in circulation.
My main idea is that a higher Informational Fitness would point to a higher ability to generalize, and hence a higher level of AGI-ness.
Because each subsequent item’s novelty is always measured with respect to the updated universe that includes all prior items, any repeated item gets a small or zero novelty score. Thus, it doesn’t inflate the overall Informational Fitness measure.
Why worry about novelty at all? My concern came from viruses, which are entities that copy themselves and spread, and therefore could be considered as intelligent if we simply valued how many times an information is copied. But viruses are obviously not intelligent—they mutate randomly and any novelty comes from selection by the environment. Therefore, a virus itself does not have a high IF in this model. However, an AI that can generate many new and successful viruses would indeed have a high IF.
Information’s relevance
Tying AGI-ness to survival of information renders the perception of generalization ability highly dependent on the environment, or in other words, state of the art at the time of an AI’s evaluation. Human societies (and presumably future AI societies) advance, and the window of what information is worth keeping drifts over time, erasing the information of the past. So whereas an AI of 2030 would have a high IF during the years it is in service, the same system (same architecture, training data, weights) would likely have a lower IF in 3030, due to being “out of date”. Sci-fi author qntm has named this “context drift” in his short story about digitalized consciousness.
Comparing AI with humans
Humans perish with an expected lifetime of 80 years, whereas AI is a digital entity that could survive indefinitely. Moreover, if you consider an AI’s performance depends on the hardware it runs on, you realize that IF should be derived from the maximum total throughput of all the copies of the AI that are running at a time. Basically, all the information that is generated by that specific version of the AI in the entire universe counts towards its IF.
Given this different nature of AI and humans, how fair would it be to compare a human’s informational fitness with an AI’s? After all, we cannot digitize and emulate a human’s brain with 100% fidelity with our current technology, and a fair comparison would require exactly that. We then quickly realize that we need to make assumptions and use thought experiments, like hypothetically scanning the brain of Albert Einstein (excuse the cliché) and running it at the same bitrate and level of parallelism as e.g. OpenAI’s most advanced model at the time. Or we could consider the entire thinking power of the human society as a whole and try to back-of-the-envelope-calculate that from the number of Universities and academics. But given that a lot of these people already use AI assistants, how much of their thinking would be 100% human?
The original OpenAI definition “a highly autonomous system that outperforms humans at most economically valuable work” is a victim of this as well. Humans are using AI now and are becoming more dependent on it, and smarter at the same time. Until we see an AI system that is entirely independent of human input, it will be hard to draw the line in between human and AI intelligence.
Thank you for reading up to this point. I think there might be a point in combining evolutionary biology with information theory. I tried to keep it simple and not include an information’s copy-count in the formulation, but it might be a good next step. If you think this post is good or just dumb, you can let me know at [email protected].
-
Our muscles will atrophy as we climb the Kardashev Scale
If you like this, you might also like my Instagram channel Nerd on Bars @nerdonbars where I calculate the power output of various athletes and myself.
This is an addendum to my previous post The Kilowatt Human. I mean it as half-entertainment and half-futuristic speculation. I extrapolate the following insight more into the future:
Before the industrial revolution, over 80% of the population were farmers. The average human had to do physical labor to survive. The average human could not help but to “bodybuild”.
Since then, humans have built machines to harness the power of nature and do the physical labor for them. What made the human civilization so powerful robbed individual humans of their own power, quite literally. The average pre-industrial human could generate a higher wattage than the average post-industrial human of today—they had to.
Before the industrial revolution, humanity’s total power output was bottlenecked by human physiology. Humanity has since moved up in the Kardashev scale. Paradoxically, the more power humanity can generate, the less physical exercise the average human can economically afford, and the weaker their body becomes.
Similar to the growth in humanity’s energy consumption, the average human’s physical strength will move down a spectrum, marked by distinct Biomechanical Stages, or BMS for short:
Biomechanical Stage Technology Level Human Physical Labor Biomechanical Power Condition BMS-I (Pre-Industrial) Stone Age to primitive machinery (sticks, stones, metal tools, mills) Nearly all tasks powered by muscle; farming, hunting, building High: Strength is universal and necessary BMS-II (Industrial-Modern) Steam engines to motorized vehicles Most heavy work done by machines; exercise optional, not required Moderate to Low: Average strength declines as tasks mechanize BMS-III (Post-Biological) Brain chips, quantum telepresence, digital existence Physical labor negligible; teleoperation replaces bodily exertion Nearly None: Muscles vestigial or irrelevant, having a body is comparatively wasteful and an extreme luxury Why do I write this? My father grew up while working as a farmer on the side, then studied engineering. He never did proper strength training in his life. I grew up studying full-time, have been working out on and off, more so in the last couple of years. And I still have a hard time beating him in arm wrestling despite the 40 years of age gap. Our offsprings will be lucky enough if they can afford to have enough time and space to exercise. I hope that their future never becomes as dramatic as I describe below.
Biomechanical Stage I (Pre-Industrial Human Power)
Began with the Stone Age, followed by the era of metal tools, basic mechanical aids like mills, and ended with the industrial revolution:
Stone Age: No metal tools, no machinery. Humans rely on their bodies entirely—hunting, gathering, carrying, and building shelters by hand. Biomechanical power is the cornerstone of survival. The average human can generate and sustain relatively high wattage because everyone is physically active out of necessity. Most humans are hunter-gatherers.
Metal tools and agriculture: Introduction of iron and steel tools improves efficiency in cutting and shaping the environment. Most people farm, carrying heavy loads, tilling fields, harvesting. Though tools reduce some brute force, overall workloads remain high and physically demanding.
Primitive machinery (e.g. mills): Waterwheels and windmills start to handle some repetitive tasks like grinding grain. Still, daily life is labor-intensive for the majority. Physical strength remains a defining human attribute.
In this era, the biomechanical power of the average human is relatively high. The average human can generate and sustain relatively high wattage because everyone is physically active out of necessity.
Biomechanical Stage II (Industrial-Modern Human Power)
We are currently in this stage. It began with the Steam Age, followed by the widespread use of internal combustion engines and motorized vehicles, and will end at the near-future threshold where technology allows a human to be economically competitive and sustain themselves without ever moving their body.
Steam engine and early industry: Factories powered by steam reduce the need for raw human muscle. Some humans shift to repetitive but less physically grueling jobs. Manual labor declines for a portion of the population.
Motorized vehicles and automation (our present): Tractors, trucks, and powered tools handle the heavy lifting. Most humans now work in services or knowledge sectors. The need to exercise for health arises because physical strength no longer follows naturally from daily life. Specialty fields (construction, sports, fitness enthusiasts) maintain higher-than-average output, but they are exceptions.
Humans still have bodies and can choose to train them, but the average sustained power output falls as convenient transport, automation, and energy-dense foods foster sedentary lifestyles.
Robots and AI: Robots and AI are increasingly able to handle physical tasks that were previously done by humans. This further reduces the need for human physical labor.
As machines handle more tasks, the average person’s baseline physical capability drops. Exercise shifts from natural necessity to a personal choice or hobby.
Biomechanical Stage III (Post-Biological Human Power)
Future scenarios where brain-machine interfaces, telepresence, and total virtualization dominate. Will begin with a Sword-Art Online-like scenario where neural interfaces allows a human to remotely control a robot in an economically competitive way, while spending most of their time immobilized. Will end in a Matrix-like scenario where the average human is born as a brain-in-a-jar.
Brain Chips and Teleoperation: Humans remotely control robots with no physical exertion. Commuting is done digitally. Physical strength becomes even less relevant. The population’s average biomechanical output plummets because few move their own bodies meaningfully.
Quantum Entanglement and Zero-Latency Control: Even physical constraints of distance vanish. Humans may spend their entire lives in virtual worlds or controlling machines from afar, further reducing any reason to maintain physical strength.
Bodily Sacrifice, Brains in Jars: Eventually, bodies become optional. Nervous systems are maintained artificially, teleoperating robots when needed. Muscle tissue atrophies until it is nonexistent. The concept of human biomechanical power no longer applies. The definition of what a human is becomes more and more abstract. Is it organic nerve tissue or even just carbon-based life?
The human body, if it exists at all, is not maintained for physical tasks. The average person’s muscular capability collapses to negligible levels.
How does the Kardashev Scale align with the Biomechanical Stages?
In my opinion, the stages will not align perfectly with Kardashev Type I, II and III civilizations. Instead, they will overlap in the following way:
Kardashev Type Biomechanical Stage Description Type I (Planetary) BMS-I (Pre-Industrial) The average human can generate and sustain relatively high wattage because everyone is physically active out of necessity. Most humans are hunter-gatherers or farmers. BMS-II (Industrial-Modern) Humans still have bodies and can choose to train them, but the average sustained power output falls as convenient transport, automation, and energy-dense foods foster sedentary lifestyles. We are still limited to 1 planet. Type II (Interstellar) BMS-III (Post-Biological) The average person’s muscular capability collapses to negligible levels. The concept of human biomechanical power no longer applies. The definition of what a human is becomes more and more abstract. Type III (Galactic) What kind of societal organism can consume energy at a galactic scale? Is there any hope that they will look like us? I think that by the time we reach other stars, we will also have pretty sophisticated telepresence and brain-machine interface technology. In fact, those technologies might be the only way to survive such journeys, or not have to make them at all, as demonstrated in the Black Mirror episode Beyond the Sea:

Black Mirror: Beyond the Sea. Go watch it if you haven’t, it’s the best episode of the season.
So BMS-III might already be here by the time we are a Type II civilization. As for what an organic body means for a Type III galactic civilization, I can’t even begin to imagine.
This post has mostly been motivated by my sadness that while our life quality has increased with technology, it has also decreased in many other ways. We evolved for hundreds of thousands of years to live mobile lives. But we became such a successful civilization that we might soon not be able to afford movement. We are thus in a transitory period where we started to diverge from our natural way of life, too quickly for evolution to catch up. And when evolution finally does catch up, what will that organism look like? How will it feed itself, clean itself and reproduce? Will the future humans be able to survive going outside at all?
In another vein, technology could also help us perfectly fit bodies by altering our cells at a molecular level. But if there is no need to move to contribute to the economy, why would anyone do such an expensive thing?
My hope is that sexual competition and the need for reproduction will maintain an evolutionary pressure just enough to keep our bodies fit. This assumes that individual humans are still in control of their own reproduction and can select their partners freely. Because a brain-in-a-jar is obviously not an in-dividual—they have been divided into their parts and kept only the one that is economically useful.
-
The Kilowatt Human
tl;dr: I calculate my power output in Watts/Horsepower and aim to maximize that, instead of muscle volume, in my workouts:
This is a work in progress, email feedback to [email protected].
If you like this, you might also like my Instagram channel Nerd on Bars @nerdonbars where I calculate the power output of various athletes and myself.
Why do people hit the gym? What is their goal?
For some, it is to put on muscle and look good. For others, it is to be healthy and live longer. For yet others, it is to have fun, because doing sports is fun. None of these are mutually exclusive.
In this post, I will not focus on any of these. I will focus on the goal of getting strong and building power. I write this, because I feel like people are doing exercise more and more for appearance’s sake, and less to get strong. And it has to do with economics.
Before the industrial revolution, over 80% of the population were farmers. The average human had to do physical labor to survive. The average human could not help but to “bodybuild”.
Since then, humans have built machines to harness the power of nature and do the physical labor for them. What made the human civilization so powerful robbed individual humans of their own power, quite literally. The average pre-industrial human could generate a higher wattage than the average post-industrial human of today—they had to.
Before the industrial revolution, humanity’s total power output was bottlenecked by human physiology. Humanity has since moved up in the Kardashev scale. Paradoxically, the more power humanity can generate, the less physical exercise the average human can economically afford, and the weaker their body becomes. Strength has become a luxury.
This is why most modern fitness terms make me sad, because they remind me of what has been lost.
Consider “functional training”. There used to be no training other than “functional”, because most physical effort had to create economic value. The term is used to differentiate between exercises with machines which target specific muscles, and exercises that are composed of more “compound movements” that mimic real-life activities. It used to be that people did not have to do any training, because physical exercise was already a part of their daily life.
This is why I dislike “building muscle” as a goal as well. Since strength is a luxury now, people want to maximize that in their lives. However, they end up trying to maximize the appearance of strength, because increasing actual strength is harder than building muscle.
When I say it is harder to get strong than to look strong, I mean it in the most materialistic sense: Increasing your body’s power output in Watts is harder and economically more expensive than increasing muscle volume in Cubic Centimeters. Increasing wattage has a higher time and money cost, requires more discipline and a lot more effort. It is a multi-year effort.
Contrarily, muscle can be built quicker in a matter of months, without getting relatively stronger. Many bodybuilders can’t do a few pull-ups with proper form. Their strength doesn’t transfer to other activities. They are sluggish and lack agility. In that sense, bodybuilding culture today embodies the worst parts of capitalism and consumerism. Empty, hollow muscle as a status symbol. Muscle for conspicuous fitness.
To meet up the demand, capitalism has commoditized exercise in the form of the modern machine-laden gym: a cost-optimized low-margin factory. Its product is the ephemeral Cubic Centimeter of Muscle™ which goes away quickly the moment you stop working out.
These gyms are full of people whose main motivation for working out is feeling socially powerless and unattractive. However, instead of going after real physical power, i.e. Watts, they go after the appearance of power, muscle volume. They compare themselves to people that just look bigger, people with higher volume.
The goal of this post is to convince you that it is superior to chase Watts than to chase muscle volume. It is psychologically more rewarding, the muscle gained from it is more permanent and has higher power density. However, it is more difficult and takes longer to achieve.
Goals
Goals matter. For example, if you purely want to maximize your muscle mass or volume, using steroids or questionable supplements is a rational thing to do. Enough people have criticized it such that I don’t need to. Disrupting your hormonal system just to look bigger and be temporarily stronger is extremely dumb.
I personally want to:
- feel powerful, and not just look like it.
- live as long and healthily as I can.
I believe that the best way to do that is to increase my power output in Watts and do regular strength training in a balanced way that will not wear out my body.
If I had to define an objective function for my exercise, it would be:
where is my power output, is the length of my life as a function of my power output, and are weights that I assign to power and longevity. I won’t detail this any further, because I don’t want to compute anything. I just want to convey my point.
Notice how I don’t constrain myself to any specific type of exercise, such as calisthenics or weightlifting. As long as it makes me more powerful, anything goes. Is wrestling going to get me there? Count me in. Is working in the fields, lifting rocks, firefighter training or Gada training going to get me there? I don’t differentiate. As long as it makes me more powerful, I am in.
Calculating power
How can one even calculate their power output?
It is actually quite easy to do, with high-school level physics. You just need to divide the work done by the time it took.
For example, consider a muscle-up:

Left: Muscle-up starting position. Right: Top of the movement.
I am at the starting position on the left, and at the top of the movement on the right. In both frames, my velocity is 0, so there is no kinetic energy. Therefore, we can calculate a lower bound of my power output by comparing the potential energies between the two frames. Denoting the left frame with subscript 0 and the right frame with subscript 1, we have:
where is the potential energy, is my mass, is the acceleration due to gravity and is the height.
The work I do is the change in potential energy:
And my power output is the work divided by the time it took:
The distance I traveled can be calculated from anthropometric measurements:

Various distances on the human body.
I will denote the distances from this figure with subscripts , and so on. Comparing this with the previous figure, we have roughly:
To understand how I derive this, consider the hands fixed during the movement and that the body is switching from a position where the arms are extended upwards to a position where the arms are extended downwards.
I have measured my own body, and found this to be roughly equal to 130 cm. Given that it took me roughly 2 seconds to do the movement and my mass at the time was roughly 78 kg, I have found the lower bound of my power output to be:
It is a lower bound, because the muscles are not 100% efficient, some energy is dissipated e.g. as heat during the movement, my movement is not perfectly uniform, etc.
Still, the lower bound calculation is pretty concise, and can be made even more accurate with a stopwatch and a slow-motion camera.
Aiming for 1 kilowatt
When I was first running to calculations, I wanted to get a rough idea of the order of magnitude of the power output of various exercises. It surprised me when I found out that most exercises are in 10-1000 Watt range, expressable without an SI prefix.
I have been training seriously for almost a year and regularly for a couple of years before that. I have discovered that in my current state, my unweighted pull-ups are in the 500-1000 Watt range. For the average person, 1000 Watts, i.e. 1 kilowatt, is an ambitious goal, but not an unattainable one. 1 kilowatt simply sounds cool as a target to aim for, as if you are a dynamo, a machine. A peak athlete can easily generate 1 kilowatt with their upper body for short durations.
How does this reflect to the muscle-up example I gave above?
If I am not adding any additional weights to my body, that means the duration which I complete the movement would need to decrease. We can calculate how much that would need to be. Moreover, we can derive a general formula which calculates how fast anyone would need to perform a muscle-up to generate 1 kilowatt.
To do that, we first need to express power in terms of the person’s height. Previously, we had . Most people have roughly similar anthropometric ratios, so we can use my measurements to approximate that ratio. Multiply and divide by to get:
For me, , and , so:
Let’s denote the person’s height as . Then we have
Therefore, the power output can be expressed as:
Since we want to generate 1 kilowatt, we can solve for :
If we substitute and assume is in centimeters, we get roughly:
The formula is really succinct and easy to remember: Just multiply the person’s mass in kilograms by their height in centimeters and divide by 14000.
Calculating for myself, I get seconds.
This confirms that I need to get two times faster in order to generate 1 kilowatt. Alternatively, if I hit a wall in terms of speed, I could add weights to my body to increase my power output. (TBD)
My friend and trainer J has agreed to record his muscle-up and various other exercises, so I will add his numbers and compare them soon.
TBD: Add the data from J.
Extending to other movements
I chose the muscle-up because I’ve been working on it recently. However, this method can be applied to any movement, as it’s just an application of basic physics.
For example,
- Do you want to calculate the power output of a pull-up? You just need to change the height , it’s roughly half the distance for muscle-up.
- Do you want to calculate the power output of a weighted pull-up? You just need to add the additional mass to your body mass .
- Do you want to calculate the power output of a sprint start? Just measure your top speed at the beginning and the time it took to accelerate to that speed, and divide your kinetic energy by that time.
- Do you want to calculate the power output of a bench press? You need to set as your arm length and as the weight of the barbell.
See the next section for a more detailed example.
Power-weight relationship in a bench press
In the bodyweight examples above, we had the same bodyweight, and it was being moved over different distances.
Then a good question to ask is: How does the power output scale with the weight lifted? The bench press is an ideal exercise to measure this in a controlled way.
25% slowed down and synced videos of a bench press with increasing weights. Top row left to right: Rounds 1, 2, 3. Bottom row left to right: Rounds 4, 5, 6.
I asked my friend to help me out with timing bench press repetitions over 6 rounds with different weights. You can see these in the video above.
Before we even look at the results, we can use our intuition to guess what kind of relationship we will see. If the weight is low, power is low as well. So as we increase the weight, we expect the power to increase. However, human strength is limited, so the movement will slow down after a certain point, and the power will decrease. We should see the power first increase with weight, and then decrease. This is indeed what happens.
In each round, my friend did 3 to 4 repetitions with the same weight. I calculated the average time it took to complete the repetition and the total weight (barbell + plates) lifted in that round. Then, I calculated the power output for each round using the formula above. The height that the barbell travels during the ascent is .
Round Total Weight (kg) Average Time (ms) Power (Watt) 1 40 580 291 2 45 623 305 3 50 663 318 4 55 723 321 5 60 870 291 6 65 1043 263 The visualizations below are aligned with the intuition:

Total weight vs average time in a bench press. Time taken increases monotonically and super-linearly with weight.

Total weight vs power in a bench press. Power first increases with weight, then decreases.

Average time vs power in a bench press. Similar to the weight vs power plot, but with time on the x-axis.
The figures matches the perceived difficulty of the exercise. My friend said he usually trains with 45-50 kg, and it started to feel difficult in the last 2 rounds. His usual load is under the 55 kg limit where his power saturates. That could mean he is under-loading, and should load at least 60 kg to achieve progressive overload and increase his power.
Reinventing Velocity Based Training, Plyometrics etc.
Power is a factor of speed and force. So in a nutshell, this project is about maximizing speed and force at the same time.
While starting this project, I wanted to have a fresh engineer’s look at powermaxxing, and did not want to get influenced by existing methods or literature. I knew that sports people were using scientific methods to measure and improve performance for decades, but I wanted to discover things on my own. I will continue to stay away from existing knowledge for some time, before I look at them in more detail.
Also: I have personally not seen any person on social media that tracks power output in Watts, or visualizes it with a Wattmeter.
If you know about such a channel, please let me know.
Not-conclusion
This is a work in progress, so there is no conclusion to this yet. I will add more content as I learn more.
Aim for Watts. It is hard, but more rewarding.
-
Python might take over JavaScript as the most used language after all uv from @astral_sh is one of the biggest upticks in Python developer experience in the last 10 years I've seen so many people struggle with Python distributions, virtual environments, Anaconda, etc. over the years Most newbies don't care about where their Python executables are, why they have to edit PATH, or why they have to activate a virtual environment It seems like uv has fixed this: github.com/astral-sh/uv
-
Open Thought > Closed Thought
OpenAI released a new model that “thinks” to itself before it answers. They intentionally designed the interface to hide this inner monologue. There was absolutely no technical reason to do so. Only business reasons
If you try to make o1 reveal its inner monologue, they threaten to remove your access
Because if they let people freely extract this, competitors could quickly use that to improve their models
It seems that AI value creation will be shifting more towards inference-time compute, into Chains of Thought. We might be witnessing the birth of a new paradigm of open vs. closed thought
Impressive as o1 is, the move to hide CoTs is pretty pathetic and reminds of Microsoft’s late 90s Windows Server push. Below is an email from Bill Gates about how he is worried that Microsoft won’t be able to corner the server market. A few years after he wrote those lines, Linux and LAMP came to dominate servers
Now all eyes on AI at Meta and Zuck for their take on o1/Strawberry/Q*/Orion
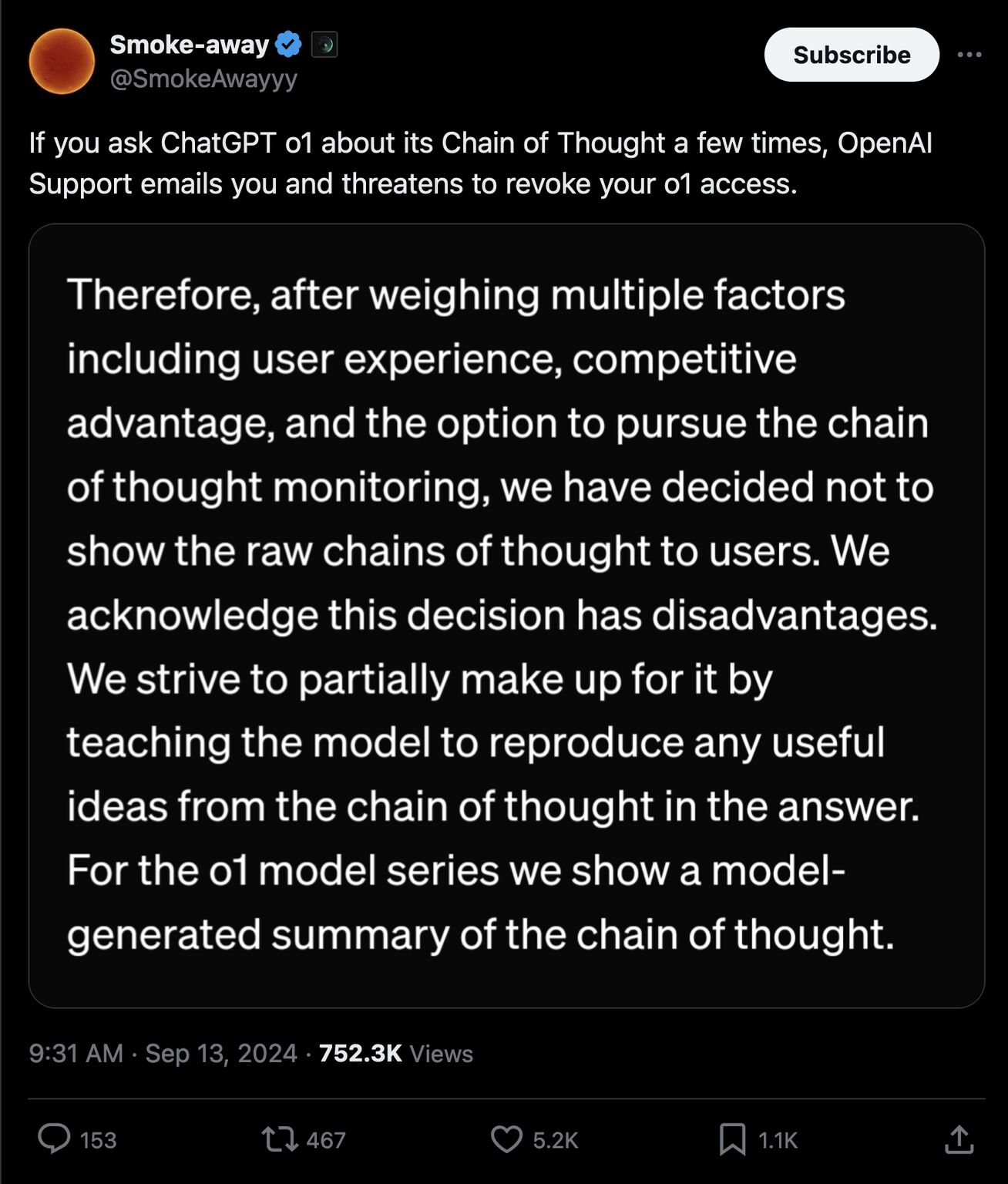

Originally posted on LinkedIn
-
Imagine the following scenario: 1. We develop brain-scan technology today which can take a perfect snapshot of anyone’s brain, down to the atomic level. You undergo this procedure after you die and your brain scan is kept in some fault-tolerant storage, along the lines of GitHub Arctic Code Vault. 2. But sufficiently cheap real-time brain emulation technology takes considerably longer to develop—say 1000 years in the future. 3. 1000 years pass. Everyone that ever knew, loved or cared about you die. Here is the crucial question: Given that running a brain scan still costs money in 1000 years, why should anyone bring *you* back from the dead? Why should anyone boot *you* up? Compute doesn’t grow in trees. It might become very efficient ... (read more in my blog: solmaz.io/why-should-anyone-boot-you-up) --- I intended this thought piece as entertainment, almost went to Hacker News frontpage: news.ycombinator.com/item?id=41360537 It must have hit some psychological spot, since people wrote a lot of comments, possibly more than number of upvotes.
-
Why should anyone boot *you* up?
Imagine the following scenario:
- We develop brain-scan technology today which can take a perfect snapshot of anyone’s brain, down to the atomic level. You undergo this procedure after you die and your brain scan is kept in some fault-tolerant storage, along the lines of GitHub Arctic Code Vault.
- But sufficiently cheap real-time brain emulation technology takes considerably longer to develop—say 1000 years in the future.
- 1000 years pass. Everyone that ever knew, loved or cared about you die.
Here is the crucial question:
Given that running a brain scan still costs money in 1000 years, why should anyone bring *you* back from the dead? Why should anyone boot *you* up?
Compute doesn’t grow in trees. It might become very efficient, but it will never have zero cost, under physical laws.
In the 31st century, the economy, society, language, science and technology will all look different. Most likely, you will not only NOT be able to compete with your contemporaries due to lack of skill and knowledge, you will NOT even be able to speak their language. You will need to take a language course first, before you can start learning useful skills. And that assumes some future benefactor is willing to pay to keep you running before you can start making money, survive independently in the future society.
To give an example, I am a software developer who takes pride in his craft. But a lot of the skills I have today will most likely be obsolete by the 31st century. Try to imagine what an 11th century stonemason would need to learn to be able to survive in today’s society.
1000 years into the future, you could be as helpless as a child. You could need somebody to adopt you, send you to school, and teach you how to live in the future. You—mentally an adult—could once again need a parent, a teacher.
(This is analogous to cryogenics or time-capsule sci-fi tropes. The further in the future you are unfrozen, the more irrelevant you become and the more help you will need to adapt.)
Patchy competence?
On the other hand, it would be a pity if a civilization which can emulate brain scans is unable to imbue them with relevant knowledge and skills, unable to update them.
For one second, let’s assume that they could. Let’s assume that they could inject your scan with 1000 years of knowledge, skills, language, ontology, history, culture and so on.
But then, would it still be you?
But then, why not just create a new AI from scratch, with the same knowledge and skills, and without the baggage of your personality, memories, and emotions?
Why think about this now?
Google researchers recently published connectomics research (click here for the paper) mapping a 1 mm³ sample of temporal cortex in a petabyte-scale dataset. Whereas the scanning process seems to be highly tedious, it can yield a geometric model of the brain’s wiring at nanometer resolution that looks like this:
Rendering based on electron-microscope data, showing the positions of neurons in a fragment of the brain cortex. Neurons are coloured according to size. Credit: Google Research & Lichtman Lab (Harvard University). Renderings by D. Berger (Harvard University)
They have even released the data to the public. You can download it here.
An adult human brain takes up around 1.2 liters of volume. There are 1 million mm³ in a liter. If we could scale up the process from Google researchers 1 million times, we could scan a human brain at nanometer resolution, yielding more than 1 zettabyte (i.e., 1 billion terabytes) of data with the same rate.
That is an insane amount of data, and it seems infeasible to store that much data for a sufficient number of bright minds, so that this technology can make a difference. That being said, do we have any other choice but to hope that we will find a way to compress and store it efficiently?
Not only it is infeasible to store that much data with current technology, extracting a nanometer-scale connectome of a human brain may not be enough to capture a person’s mind in its entirety. By definition, some information is lost in the process. Fidelity will be among the most important problems in neuropreservation for a long time to come.
That being said, the most important problem in digital immortality may not be technical, but economical. It may not be about how to scan a brain, but about why to scan a brain and run it, despite the lack of any economic incentive.
-
Frequencies of Definite Articles in Written vs Spoken German
tl;dr Skip to the Conclusion. Don’t forget to look at the graphs.
Unlike a single “the” in the English language, the German language has 6 definite articles that are used based on a noun’s gender, case and number:
- 6 definite articles: der, die, das, den, dem, des
- 3 genders: masculine, feminine, neuter (corresponding to “he”, “she”, “it” in English)
- 4 cases: nominative, accusative, dative, genitive
- 2 numbers: singular, plural
The following table is used to teach when to use which definite article:
Case Masculine Feminine Neuter Plural Nominative der die das die Accusative den die das die Dative dem der dem den Genitive des der des der Table 1: Articles to use in German depending on the noun gender and case.
Importantly, native speakers don’t look at such tables while learning German as a child. They internalize the rules through exposure and practice.
If you are learning German as a second language, however, you will most likely spend time writing down these tables and memorizing them.
While learning, you will also memorize the genders of nouns. For example, “der Tisch” (the table) is masculine, “die Tür” (the door) is feminine, and “das Buch” (the book) is neuter. Whereas predicting the case and number is straightforward and can be deduced from the context of the sentence, predicting the gender can be much more difficult.
Without going into much detail, take my word for now that the genders are semi-random. Inanimate objects such as a bus can be a “he” or “she”, whereas animate objects such as a “girl” can be a “it”.
Because of all this, German learners fail to remember the correct gender at times and develop strategies, heuristics, to fall back to some default gender or article when they are unsure. For example, some learners use “der” as a default article when they are unsure, whereas others use “die” or “das”.
I have taken many German courses since middle school. Most German courses teach you how to use German correctly, but very few of them teach you what to do when you don’t know how to use German correctly, like when you don’t know the gender of an article.
This is a precursor to a future post where I will write about those strategies. Any successful strategy must be informed by the frequencies and probability distribution of noun declensions. To that end, I performed Natural Language Processing on two corpuses of the German language:
- Transcriptions of over 140 hours of videos from the Easy German YouTube channel, which contains lots of street interviews and other spoken examples.
- 10kGNAD: Ten Thousand German News Articles Dataset, which contains over 10,000 cleaned up news articles from an Austrian newspaper.
I will introduce some notation to represent these frequencies easier, which are going to be followed by the results of the analysis.
Mapping the space of noun declensions
The goal of this article is to show the frequencies of definite articles alongside the declensions of the nouns they accompany. To be able to do that, we need a concise notation to represent the states a noun can be in.
To this end, we introduce the set of grammatical genders ,
the set of grammatical cases ,
and the set of grammatical numbers ,
The set of all possible grammatical states for a German noun is
whose number of elements is .
To represent the elements of this set better, we introduce the index notation
for , and correspond to the elements in the order seen in the definitions above.
Elements of can be shown in a single table, like below:
Case Singular Plural Masculine Feminine Neuter Masculine Feminine Neuter Nominative Accusative Dative Genitive Table 2: All possible grammatical states of a German noun in one picture.
In practice, plural forms of articles and declensions for all genders are the same in each case, so they are shown next to the singular forms:
Case Masculine Feminine Neuter Plural Nominative Accusative Dative Genitive Table 3: Plural states across genders are grouped together because they are declined in the same way. Their distinction is irrelevant for learning.
which is the case in Table 1 above. You might say, “well, of course”. In that case, I invite you to imagine a parallel universe where German grammar is even more complicated and plural forms have to be declined differently as well. Interestingly, you don’t need to visit such a universe—you just need to go back in time, because Old High German grammar was exactly like that. Note that in that Wikipedia page, some tables has the same shape as Table 2.
Why introduce such confusing looking notation? It might look confusing to the untrained eye, but it is actually very useful for representing all possible combinations in a compact way. It also makes it easier to run a sanity check on the results of the analysis through the independence axiom, which we will introduce next.
Relationships between probabilities
As a side note, the relationship between the probabilities of all grammatical states of a noun and the probabilities of each case is as below:
Similarly, for each gender:
And for each number:
This is useful for going from specific probabilities to general probabilities and vice versa.
Independence Axiom
We introduce an axiom that will let us run a sanity check on the results of the analysis. At a high level, the axiom states that the probability of a noun being in a certain case, a certain gender and a certain number are all independent of each other. For example, the probability of a noun being in the nominative case is independent of the probability of it being masculine or feminine or neuter, and it is also independent of the probability of it being singular or plural. This should be common sense in any large enough corpus, so we just assume it to be true.
Formally, the axiom can be written as
where is the joint probability of the noun being in the grammatical state .
In any given corpus, it will be hard to get this equality to hold exactly. In reality, a given corpus or the NLP libraries used in the analysis might have a bias that might distort the equality above.
The idea is that the smaller the difference between the left-hand side and the right-hand side, the more the corpus and the NLP libraries are unbiased and adhere to common sense. As a corpus gets larger and more representative of the entire language, the following quantity should get smaller:
We will calculate this quantity for the two corpuses we have and see how biased either they or the NLP libraries are.
Note that the notation is used to denote the empirical probability of the noun being in the grammatical state , which is calculated from the corpus as
where is the count of the noun being in the grammatical state . Similar notation is used for , and .
The analysis
I outline step by step how I performed the analysis on the two corpuses.
Constructing the spoken corpus
The Easy German YouTube Channel is a great resource for beginner German learners. It has lots of street interviews with random people on a wide range of topics.
To download the channel, I used yt-dlp, a youtube-dl fork:
#!/bin/bash mkdir data cd data yt-dlp -f 'ba' -x --audio-format mp3 https://www.youtube.com/@EasyGermanThis gave me 946 audio files with over 139 hours of recordings. Then I used OpenAI’s Whisper API to transcribe all the audio:
import json import os import openai from tqdm import tqdm DATA_DIR = "data" OUTPUT_DIR = "transcriptions" # Get all mp3 files in the current directory mp3_files = [ f for f in os.listdir(DATA_DIR) if os.path.isfile(f) and f.endswith(".mp3") ] mp3_files = sorted(mp3_files) # Create the output directory if it doesn't exist if not os.path.exists(OUTPUT_DIR): os.makedirs(OUTPUT_DIR) for file in tqdm(mp3_files): # Create json target file name in output directory json_file = os.path.join(OUTPUT_DIR, file.replace(".mp3", ".json")) # If the json file already exists, skip it if os.path.exists(json_file): print(f"Skipping {file} because {json_file} already exists") continue # Check if the file is greater than 25MB if os.path.getsize(file) > 25 * 1024 * 1024: print(f"Skipping {file} because it is greater than 25MB") continue print(f"Running {file}") try: output = openai.Audio.transcribe( model="whisper-1", file=open(file, "rb"), format="verbose_json", ) output = output.to_dict() json.dump(output, open(json_file, "w"), indent=2) except openai.error.APIError: print(f"Skipping {file} because of API error") continueThis gave me a lot to work with, specifically a little bit over 1 million words of spoken German. As a reference, the content of the videos can fill roughly more than 10 novels, or alternatively, 400 Wikipedia articles. Note that I created this dataset around May 2023, so the dataset would be even bigger if I ran the script today. However, it still costs money to transcribe the audio, so I will stick with this dataset for now.
Constructing the written corpus
The 10kGNAD: Ten Thousand German News Articles Dataset contains over 10,000 cleaned up news articles from an Austrian newspaper. I downloaded the dataset and modified the script they provided to extract the articles from the database and write them to a text file:
import re import sqlite3 from tqdm import tqdm from bs4 import BeautifulSoup ARTICLE_QUERY = ( "SELECT Path, Body FROM Articles " "WHERE PATH LIKE 'Newsroom/%' " "AND PATH NOT LIKE 'Newsroom/User%' " "ORDER BY Path" ) conn = sqlite3.connect(PATH_TO_SQLITE_FILE) cursor = conn.cursor() corpus = open(TARGET_PATH, "w") for row in tqdm(cursor.execute(ARTICLE_QUERY).fetchall(), unit_scale=True): path = row[0] body = row[1] text = "" description = "" soup = BeautifulSoup(body, "html.parser") # get description from subheadline description_obj = soup.find("h2", {"itemprop": "description"}) if description_obj is not None: description = description_obj.text description = description.replace("\n", " ").replace("\t", " ").strip() + ". " # get text from paragraphs text_container = soup.find("div", {"class": "copytext"}) if text_container is not None: for p in text_container.findAll("p"): text += ( p.text.replace("\n", " ") .replace("\t", " ") .replace('"', "") .replace("'", "") + " " ) text = text.strip() # remove article autors for author in re.findall( r"\.\ \(.+,.+2[0-9]+\)", text[-50:] ): # some articles have a year of 21015.. text = text.replace(author, ".") corpus.write(description + text + "\n\n") conn.close()This gave me 10277 articles with around 3.7 million words of written German. Note that this is over 3 times bigger than the spoken corpus.
NLP and counting the frequencies
I used spaCy for Part-of-Speech Tagging. This basically assigns to each word whether it is a noun, pronoun, adjective, determiner etc. Definite articles will have the PoS tag
"DET"in the output of spaCy.spaCy is pretty useful. For any
tokenin the output,token.headgives the syntactic parent, or “governor” of thetoken. For definite articles like “der”, “die”, “das”, the head will be the noun they are referring to. If spaCy couldn’t connect the article with a noun, any deduction of gender has a high likelihood of being wrong, so I skip those cases.import numpy as np import spacy from tqdm import tqdm CORPUS = "corpus/easylang-de-corpus-2023-05.txt" # CORPUS = "corpus/10kGNAD_single_file.txt" ARTICLES = ["der", "die", "das", "den", "dem", "des"] CASES = ["Nom", "Acc", "Dat", "Gen"] GENDERS = ["Masc", "Fem", "Neut"] NUMBERS = ["Sing", "Plur"] CASE_IDX = {i: CASES.index(i) for i in CASES} GENDER_IDX = {i: GENDERS.index(i) for i in GENDERS} NUMBER_IDX = {i: NUMBERS.index(i) for i in NUMBERS} # Create an array of the articles ARTICLE_ijk = np.empty((2, 3, 4), dtype="<U32") ARTICLE_ijk[0, 0, 0] = "der" ARTICLE_ijk[0, 1, 0] = "die" ARTICLE_ijk[0, 2, 0] = "das" ARTICLE_ijk[0, 0, 1] = "den" ARTICLE_ijk[0, 1, 1] = "die" ARTICLE_ijk[0, 2, 1] = "das" ARTICLE_ijk[0, 0, 2] = "dem" ARTICLE_ijk[0, 1, 2] = "der" ARTICLE_ijk[0, 2, 2] = "dem" ARTICLE_ijk[0, 0, 3] = "des" ARTICLE_ijk[0, 1, 3] = "der" ARTICLE_ijk[0, 2, 3] = "des" ARTICLE_ijk[1, :, 0] = "die" ARTICLE_ijk[1, :, 1] = "die" ARTICLE_ijk[1, :, 2] = "den" ARTICLE_ijk[1, :, 3] = "der" # Use the best transformer-based model from SpaCy MODEL = "de_dep_news_trf" nlp_spacy = spacy.load(MODEL) # Initialize the count array. We will divide the elements by the # total count of articles to get the probability of each S_ijk N_ijk = np.zeros((len(NUMBERS), len(GENDERS), len(CASES)), dtype=int) corpus = open(CORPUS).read() texts = corpus.split("\n\n") for text in tqdm(texts): # Parse the text doc = nlp_spacy(text) for token in doc: # Get token string token_str = token.text token_str_lower = token_str.lower() # Skip if token is not one of der, die, das, den, dem, des if token_str_lower not in ARTICLES: continue # Check if token is a determiner # Some of them can be pronouns, e.g. a large percentage of "das" if token.pos_ != "DET": continue # If SpaCy couldn't connect the article with a noun, skip head = token.head if head.pos_ not in ["PROPN", "NOUN"]: continue # Get the morphological features of the token article_ = token_str_lower token_morph = token.morph.to_dict() case_ = token_morph.get("Case") gender_ = token_morph.get("Gender") number_ = token_morph.get("Number") # Get the indices i, j, k gender_idx = GENDER_IDX.get(gender_) case_idx = CASE_IDX.get(case_) number_idx = NUMBER_IDX.get(number_) # If we could get all the indices by this point, try to get the # corresponding article from the array we defined above. # This is another sanity check if gender_idx is not None and case_idx is not None and number_idx is not None: article_check = ARTICLE_ijk[number_idx, gender_idx, case_idx] else: article_check = None # If the sanity check passes, increment the count of N_ijk if article_ == article_check: N_ijk[number_idx, gender_idx, case_idx] += 1To calculate , we divide the counts by the total number of articles:
P_S_ijk = N_ijk / np.sum(N_ijk)Then we calculate the empirical probabilities of each gender, case and number:
# Probabilities for each number P_N = np.sum(P_S_ijk, axis=(1, 2)) # Probabilities for each gender P_G = np.sum(P_S_ijk, axis=(0, 2)) # Probabilities for each case P_C = np.sum(P_S_ijk, axis=(0, 1))The joint probability is calculated as:
joint_prob_ijk = np.zeros((2, 3, 4)) for i in range(2): for j in range(3): for k in range(4): joint_prob_ijk[i, j, k] = P_N[i] * P_G[j] * P_C[k]Finally, we calculate the difference between the empirical probabilities and the joint probabilities:
delta_ijk = 100 * (P_S_ijk - joint_prob_ijk)This will serve as an error term to see how biased the corpus is. The bigger the error term, the higher the chance of something being wrong with the corpus or the NLP libraries used.
High level results
I compare the following statistics between the spoken and written corpus:
- The frequencies of definite articles.
- The frequencies of genders.
- The frequencies of cases.
- The frequencies of numbers.
As I have already annotated in the code above, the analysis took into account the tokens that match the following criteria:
- Is one of “der”, “die”, “das”, “den”, “dem”, “des”,
- Has the PoS tag
DET - Is connected to a noun (
token.head.pos_is eitherPROPNorNOUN)
This lets me count the frequencies of the definite articles alongside the declensions of the nouns they accompany. The results are as follows:
Frequencies of genders
The distribution of the genders of the corresponding nouns is as below:
Gender Spoken corpus Written corpus Masc 30.78 % (10579) 33.99 % (109906) Fem 44.83 % (15407) 47.77 % (154485) Neut 24.39 % (8381) 18.24 % (58998) 
Table and Figure 4: Each gender, their percentage and count for the spoken and written corpora.
Observations:
- The written corpus contains ~6 percentage points less neuter nouns than the spoken corpus.
- This ~6 pp difference is distributed almost equally between the masculine and feminine nouns, with the written corpus containing ~3 pp more feminine nouns and ~3 pp more masculine nouns.
The difference is considerable and might point out to a bias in the way Whisper transcribed the speech or spaCy has parsed it. Both corpora are large enough to be representative, so this needs investigation in a future post.
Frequencies of cases
The distribution of the cases that the article-noun pairs are in is as below:
Case Spoken corpus Written corpus Nom 35.96 % (12357) 34.82 % (112612) Acc 33.75 % (11598) 23.52 % (76062) Dat 25.98 % (8929) 23.59 % (76298) Gen 4.32 % (1483) 18.06 % (58417) 
Table and Figure 5: Each case, their percentage and count for the spoken and written corpora.
The spoken corpus has ~10 pp more accusative nouns, ~2 pp more dative nouns and ~13 pp less genitive nouns compared to the written corpus. The nominative case is more or less the same in both corpora.
This might be the analysis capturing the contemporary decline of the genitive case in the German language, as popularized by Bastian Sick with the phrase “Der Dativ ist dem Genitiv sein Tod” (The dative is the death of the genitive) with his eponymous book. However, the graph clearly shows a trend towards accusative, and much less towards dative.
Moreover, written language differs in tone and style from spoken language for many languages, including German. This might also explain the differences in the frequencies of the cases.
If this is not due to a bias, we might be onto something here. This also needs further investigation in a future post.
Frequencies of numbers
The distribution of the numbers of the corresponding nouns is as below:
Number Spoken corpus Written corpus Sing 81.10 % (27870) 79.18 % (256066) Plur 18.90 % (6497) 20.82 % (67323) 
Table and Figure 6: Each number, their percentage and count for the spoken and written corpora.
The ratio of singular to plural nouns is more or less the same in both corpora. I wonder whether this 80-20 ratio is “universal” in German or any other languages as well…
Frequencies of definite articles
The distribution of the definite articles in the spoken and written corpus is as below:
Article Spoken corpus Written corpus der 26.74 % (9190) 34.44 % (111378) die 36.47 % (12534) 32.60 % (105416) das 15.80 % (5430) 8.81 % (28481) den 12.22 % (4201) 11.50 % (37174) dem 7.39 % (2539) 6.23 % (20135) des 1.38 % (473) 6.43 % (20805) 
Table and Figure 7: Each definite article, their percentage and count for the spoken and written corpora.
Observations:
derappears less frequently (~8 pp difference),dieappears more frequently (~4 pp difference),dasappears more frequently (~7 pp difference),desappears less frequently (~5 pp difference),
in the spoken corpus compared to the written corpus.
denanddemare more or less the same in both corpora.The ~7 pp difference in
dasis despite the fact that ~78% of the occurrence of the tokendasin the spoken corpus are pronouns (PRON, notDET) and hence excluded from the table above. See the section below for more details. Looking at the gender distribution above, the spoken corpus contains ~6 pp more neuter nouns than the written corpus, which might explain this discrepancy.Empirical probabilities for the spoken corpus
Empirical probabilities:
Case Singular Plural Masculine Feminine Neuter Masculine Feminine Neuter Nominative 9.55 % 11.16 % 8.64 % 3.61 % 1.71 % 1.28 % Accusative 7.88 % 11.96 % 7.16 % 2.83 % 2.26 % 1.66 % Dative 3.84 % 14.25 % 3.55 % 1.83 % 1.36 % 1.16 % Genitive 0.71 % 1.73 % 0.67 % 0.54 % 0.40 % 0.27 % Table 8: for the spoken corpus.
Click below to see the joint probabilities and their differences as an error term:
Joint probabilities:
Case Singular Plural Masculine Feminine Neuter Masculine Feminine Neuter Nominative 8.98 % 13.07 % 7.11 % 2.09 % 3.05 % 1.66 % Accusative 8.42 % 12.27 % 6.67 % 1.96 % 2.86 % 1.56 % Dative 6.49 % 9.45 % 5.14 % 1.51 % 2.20 % 1.20 % Genitive 1.08 % 1.57 % 0.85 % 0.25 % 0.37 % 0.20 % Table 9: for the spoken corpus.
Their differences:
Case Singular Plural Masculine Feminine Neuter Masculine Feminine Neuter Nominative 0.58 % -1.91 % 1.53 % 1.52 % -1.33 % -0.38 % Accusative -0.54 % -0.31 % 0.49 % 0.86 % -0.60 % 0.10 % Dative -2.65 % 4.80 % -1.59 % 0.32 % -0.85 % -0.04 % Genitive -0.37 % 0.16 % -0.18 % 0.29 % 0.03 % 0.07 % Table 10: for the spoken corpus.
Observations:
For most elements, the differences are less than 1-2%, which is a good sign. However, significant bias shows for some cases:
- 4.80 % (der, feminine, dative, singular)
- -2.65 % (dem, masculine, dative, singular)
- -1.91 % (die, feminine, nominative, singular)
- -1.33 % (die, feminine, nominative, plural)
- and so on…
I add more comments following the results for the written corpus below.
Empirical probabilities for the written corpus
Case Singular Plural Masculine Feminine Neuter Masculine Feminine Neuter Nominative 10.63 % 12.24 % 5.14 % 3.64 % 2.11 % 1.06 % Accusative 6.31 % 9.26 % 3.67 % 1.73 % 1.63 % 0.92 % Dative 3.82 % 12.18 % 2.41 % 2.06 % 1.80 % 1.32 % Genitive 3.61 % 7.09 % 2.82 % 2.19 % 1.45 % 0.90 % Table 11: for the written corpus.
Click below to see the joint probabilities and their differences as an error term:
Joint probabilities:
Case Singular Plural Masculine Feminine Neuter Masculine Feminine Neuter Nominative 9.37 % 13.17 % 5.03 % 2.46 % 3.46 % 1.32 % Accusative 6.33 % 8.90 % 3.40 % 1.66 % 2.34 % 0.89 % Dative 6.35 % 8.92 % 3.41 % 1.67 % 2.35 % 0.90 % Genitive 4.86 % 6.83 % 2.61 % 1.28 % 1.80 % 0.69 % Table 12: for the written corpus.
Their differences:
Case Singular Plural Masculine Feminine Neuter Masculine Feminine Neuter Nominative 1.26 % -0.93 % 0.11 % 1.17 % -1.35 % -0.26 % Accusative -0.02 % 0.37 % 0.27 % 0.06 % -0.71 % 0.03 % Dative -2.53 % 3.26 % -1.00 % 0.39 % -0.54 % 0.43 % Genitive -1.25 % 0.26 % 0.21 % 0.92 % -0.35 % 0.21 % Table 13: for the written corpus.
Observations:
The difference terms follow a similar pattern to the spoken corpus in the extreme cases:
- 3.26 % (der, feminine, dative, singular)
- -2.53 % (dem, masculine, dative, singular)
- -1.35 % (die, feminine, nominative, plural)
Since the bias is most extreme in many common cells, this leads me to believe that there is a bias in spaCy’s
de_dep_news_trfmodel that confuses the case or gender in some cases. This hypothesis can be tested by using a different model and library, and calculating the differences again. I’m leaving that as future work.Calculating the number of articles used as determiners versus pronouns
Another comparison of interest is whether one of the “der”, “die”, “das”, “den”, “dem”, “des” is used more as a pronoun than as a determiner. To give an example, “das” can be used as a pronoun in the sentence “Das ist ein Buch” (That is a book) or as a determiner in the sentence “Das Buch ist interessant” (The book is interesting).
We can calculate this by storing the PoS tags of tokens that match “der”, “die”, “das”, “den”, “dem”, “des” and dividing the numbers by the occurrence of each article.
import spacy from tqdm import tqdm CORPUS = "corpus/easylang-de-corpus-2023-05.txt" # CORPUS = "corpus/10kGNAD_single_file.txt" ARTICLES = ["der", "die", "das", "den", "dem", "des"] MODEL = "de_dep_news_trf" nlp_spacy = spacy.load(MODEL) # This array will store the count of each POS tag for each article POS_COUNT_DICT = {i: {} for i in ARTICLES} corpus = open(CORPUS).read() texts = corpus.split("\n\n") for text in tqdm(texts): doc = nlp_spacy(text) for token in doc: success = True # Get token string token_str = token.text token_str_lower = token_str.lower() if token_str_lower not in ARTICLES: continue if token.pos_ not in POS_COUNT_DICT[token_str_lower]: POS_COUNT_DICT[token_str_lower][token.pos_] = 0 POS_COUNT_DICT[token_str_lower][token.pos_] += 1 print(POS_COUNT_DICT)For both corpora, the >99% of the PoS tags are either
DETorPRON. I have ignored the rest of the tags for simplicity.Article Pronoun % in spoken corpus Pronoun % in written corpus der 15.4 % (1734 out of 11242) 5.8 % (7125 out of 123442) die 29.3 % (6024 out of 20557) 11.6 % (14696 out of 126783) das 78.6 % (20941 out of 26638) 33.1 % (14439 out of 43673) den 11.3 % (602 out of 5332) 2.0 % (836 out of 41393) dem 12.2 % (360 out of 2962) 8.9 % (2060 out of 23060) des 0.6 % (3 out of 493) 0.0 % (8 out of 21548) 
Table and Figure 14: Percentage of usage of “der”, “die”, “das”, “den”, “dem”, “des” as pronouns versus determiners in the spoken and written corpora.
Observations:
The spoken corpus overall uses more pronouns than the written corpus. The most striking difference is in the usage of “das” as a pronoun, with the spoken corpus using it as a pronoun in ~45 pp more cases than the written corpus. This might be due to a bias at any point in the analysis pipeline, or it might be due to the nature of spoken versus written language.
Conclusion
I have already commented a great deal below each result above. I don’t want to speak in absolutes at this point, because the analysis might be biased due to the following factors:
- Corpus bias: Easy German is a YouTube channel for German learning, and despite having a diverse set of street interviews, there is also a lot of accompanying content that might skew the results. Similarly, the 10kGNAD dataset is a collection of news articles from an Austrian newspaper, which might also skew the results. There might be differences between Austrian German and German German. To overcome any corpus related biases, this work should be repeated with even more data.
- Transcription bias: I used OpenAI’s Whisper V2 in May 2023 to transcribe the spoken corpus. There might be a bias in Whisper that might show up in the results. Whisper is currently among state-of-the-art speech-to-text models. We will most likely get better, faster and cheaper models in the upcoming years, and we can then repeat this analysis with them.
- NLP bias: I used spaCy’s
de_dep_news_trfmodel for Part-of-Speech Tagging. There might be a bias in this model that might show up in the results. I might use another library in spaCy, or a different NLP library altogether, to see if the results change.
That being said, if I were to draw any conclusions from the results above, those would be:
Most frequent articles
For spoken German, the most frequently used definite articles (excluding pronouns) are in the order:
die>der>das>den>dem>des.For written German, the order is:
der>die>den>das>des>dem.dieis statistically the most used definite article with close to 40% usage in spoken German Moreover,der,dieanddascollectively make up ~80% of the definite articles used in spoken German. So if you never learn the rest, you would be speaking German correctly 80% of the time, assuming that you are using the cases correctly.Using das as pronoun in spoken German
dasis used as a pronoun much more frequently in spoken German than in written German.Most frequent genders
The most frequently used genders are in the order: feminine > masculine > neuter. This is widely known and has been recorded by many other studies as well.
Genitive on the fall, accusative (more so) and dative (less so) on the rise
Germans use genitive much less when speaking compared to writing. Surprisingly, this reflects in an increase more in the accusative case than in the dative case. This might point out to a trend where dative is falling out of favor as well. This is not to imply that accusative phrasing can be a substitute for genitive, like using “von” (of, which is dative) instead of the genitive case.
All of this point out to a trend of simplification in declension patterns of spoken German. Considering Old High German—the language German once—was even more complicated in that regard, the findings above don’t surprise me.
I might update this post with more findings or refutations of above conclusions later on, if future data shows that they are false.
-
Stripe Subscription States
This is a quick note on Subscription states on Stripe. Subscriptions are objects which track products with recurring payments. Stripe docs on Subscriptions are very comprehensive, but for some reason they don’t include a state diagram that shows the transitions between different states of a subscription. They do have one for Invoices, so maybe this post will inspire them to add one.
As of May 2024, the API has 8 values for
Subscription.status:incomplete: This is the initial state of a subscription. It means that the subscription has been created but the first payment has not been made yet.incomplete_expired: The first payment was not made within 23 hours of creating the subscription.trialing: The subscription is in a trial period.active: The subscription is active and the customer is being billed according to the subscription’s billing schedule.past_due: The subscription has unpaid invoices.unpaid: The subscription has been canceled due to non-payment.canceled: The subscription has been canceled by the customer or due to non-payment.paused: The subscription is paused and will not renew.
At any given time, a
Customer’s subscription can be in one of these states. The following diagram shows the transitions between these states.stateDiagram classDef alive fill:#28a745,color:white,font-weight:bold,stroke-width:2px classDef dead fill:#dc3545,color:white,font-weight:bold,stroke-width:2px classDef suspended fill:#ffc107,color:#343a40,font-weight:bold,stroke-width:2px active:::alive trialing:::alive incomplete:::suspended past_due:::suspended unpaid:::suspended paused:::suspended canceled:::dead incomplete_expired:::dead [*] --> incomplete: Create Subscription trialing --> active: Trial ended, first<br>payment succeeded incomplete --> trialing: Started trial incomplete --> incomplete_expired: Payment not made<br>within 23 hours incomplete --> active: Payment<br>succeeded active --> past_due: Automatic payment<br>failed trialing --> past_due: Trial ended<br>payment failed past_due --> unpaid: Retry limit<br>reached past_due --> canceled: Retry limit reached<br>or subscription canceled past_due --> active: Payment<br>succeeded trialing --> paused: Trial ended without<br>default payment method paused --> active: First payment<br>made active --> unpaid: Automatic payment disabled,<br>manual intervention required unpaid --> active: Payment<br>succeeded unpaid --> canceled: Subscription<br>canceled active --> canceled: Subscription<br>canceled paused --> canceled: Subscription<br>canceled trialing --> canceled: Subscription<br>canceled incomplete_expired --> [*] canceled --> [*]Stripe doesn’t comment on these states further and leaves their interpretation to the developer. This is probably because each company might interpret these states differently. For example, a user skipping a payment and becoming
past_duemight not warrant disabling a service for some companies, while others might want to disable services immediately. Stripe’s API is built to be agnostic of these decisions.Regardless of how you interpret these 8 states, you will most likely end up generalizing them into 3 categories:
ALIVE,SUSPENDED, andDEAD. The colors in the diagram above represent these categories:ALIVE: The subscription is active and payments are being made. States:active,trialing.SUSPENDED: The subscription is not active but can be reactivated. States:incomplete,past_due,unpaid,paused.DEAD: The subscription is not active and cannot be reactivated. Such subscriptions are effectively deleted. States:canceled,incomplete_expired.
While
DEADstates are unambiguous, your company might differ in what is consideredALIVEandSUSPENDED. For example, you might considerpast_dueasALIVEif you don’t want to disable services immediately after a payment failure.If you collapse the 8 states into these categories, you get the following diagram:
stateDiagram direction TB; classDef alive fill:#28a745,color:white,font-weight:bold,stroke-width:2px classDef dead fill:#dc3545,color:white,font-weight:bold,stroke-width:2px classDef suspended fill:#ffc107,color:#343a40,font-weight:bold,stroke-width:2px ALIVE:::alive SUSPENDED:::suspended DEAD:::dead state ALIVE { active trialing trialing-->active } state DEAD { canceled incomplete_expired } state SUSPENDED { incomplete past_due unpaid paused past_due-->unpaid } [*] --> SUSPENDED: Create<br>Subscription SUSPENDED --> ALIVE: Payment succeeded<br>or trial started ALIVE --> SUSPENDED: Payment<br>failed SUSPENDED --> DEAD: Subscription canceled<br>or checkout expired ALIVE --> DEAD: Subscription<br>canceled DEAD --> [*]The distinction is important, because Stripe doesn’t make it crystal clear what kind of subscriptions can come back from the dead and end up charging the customers multiple times. If you are not limiting the number of subscriptions per customer, this is something you should be aware of. Practically, this means that you block the customer from creating a new subscription if they already have an
ALIVEorSUSPENDEDsubscription.DEADsubscriptions can be ignored. -
Economic Burden of Language Complexity
Some languages are harder to learn compared to others. Difficulty can show up in different places. For example, English has a relatively easy grammar, but writing it can be challenging. Remember the first time you learned to write thorough, through, though, thought and tough.
Then take Chinese as an example. Its grammar is more simple than English—no verb conjugations, no tenses, no plurals, no articles. Its sounds and intonation are unusual for a westerner, but arguably not that difficult. The most difficult part might be the writing system, with thousands of characters that must be memorized before one can read and write fluently. A 7-year old primary schooler can learn to read and write English in 2 years, whereas for Chinese it takes at least 4 years. This is despite multiple simplifications in the Chinese writing system in the 20th century.
Now compare two adult workers of equal skill: a native Chinese emigrating to the US and learning English, versus a native American emigrating to China and learning Chinese. Which one will be able to start working and contributing to the economy faster? Extrapolating from the primary school example, the US adult could take at least twice as long to learn Chinese compared to their Chinese counterpart learning English—at least for reading and writing.
Time is money. It takes time to learn a language, and it takes more time to learn a “harder” one. Therefore, learning a complicated language has a cost. The cost of language complexity applies not only to native speakers, but also to foreign learners, which are the focus of this post:
The more complex the language of a country, the less attractive it is to foreign workers, skilled or otherwise.
This is because any worker who decides to move to a country with a more complex language will take longer to start contributing to the economy. This can be measured directly in terms of lost wages, taxes, and productivity.
Any such worker will also find it more difficult to integrate into the society, which can create indirect costs that are harder to measure, but are a burden nonetheless. For example, it could result in reduced upward mobility, decreased purchasing power, increased reliance on social services, and so on.
Here, I will focus on a cost that is one of the most tangible and easiest to quantify: wages that are lost due to language complexity. Doing that is relatively easy and gets my point across. I will then apply my calculation to a specific language, German, as a case study.
Wages lost while learning the local language
I will attempt a back-of-the-envelope calculation to estimate the total value of lost wages per year for all foreign workers in a country, while they are learning the local language. “Lost wages” mean the money that workers would have earned if they were working instead of learning the language, and the economic value that is not created as a result.
This is going to be a simplified model with many assumptions. For example, I assume that foreign workers do not know the local language when they arrive and spend a fixed amount of time per week learning the local language.
In the model, a given country receives foreign workers per year through migration. Each foreign worker takes years to learn the local language. Assuming that the rate of immigration stays constant (steady state), the number of foreign workers learning the local language at any given time is given by:
The average foreign worker dedicates hours per week to learning the local language. Most likely, only a percentage of will block actual work hours, for example in the form of an intensive language course, and the rest of the learning will take place during free time. If the average foreign worker works weeks per year, then the total number of hours per year that they spend learning the local language, that would otherwise be spent working, is given by:
Assuming that the average foreign worker earns units of currency per hour, the total value of lost wages per year and per foreign worker is given by:
We assume that for the given language, it takes hours of study to reach a certain level of proficiency necessary to communicate effectively in the workplace, say B2. Then we can calculate the number of years it takes to reach that level as:
Finally, the total value of lost wages per year for all foreign workers in a country is given by:
Put into words, the total value of lost wages per year for all foreign workers in a country is equal to the multiplication of the average hourly wage , the percentage of time spent learning the language that displaces work , the number of people immigrating per year , and the number of hours of study required to reach a certain level of proficiency .
If you could measure all these values accurately, you would have a good minimum estimate, a lower bound of the economic burden of teaching a language to foreign workers. The burden of complexity for any given language would then only be calculated by comparing its value to that of other languages.
Take Germany as an example. Given the values of , , for Germany, and the values for both German and English, you could calculate the money that the German economy is losing per year by German not being as easy to learn as English:
I attempt to calculate this below, with values I could find on the internet.
Case study: German
I live in Germany and I wrote this post with the German language in mind. Compared to other European languages like English or Spanish, German has certain features that makes it harder to learn. For example, it has a noun gender system where each noun can be one of three genders and each gender has to be inflected differently. These genders are random enough to cost a significant amount time while learning it as a second language.
Unfortunately, I haven’t found any authoritative data on how much harder German exactly is to learn, compared to other languages. It is not possible to exactly quantify language difficulty, because it not only depends on the language itself but also on the native language of the learner, their age, their motivation, and so on. Any data I present below are anecdotal and should be taken with a grain of salt.
That being said, the fact that German is harder to learn as a second language compared to, say, English, is self-evident to most people who have tried to learn both from the beginner level. So the data below is still useful, because it visually represents this difference in difficulty.
Hours required to reach B2 level
To begin with, Goethe Institut has put up the following values for German on the FAQ section of their website1:
As a rough guideline, we estimate it will take the following amount of instruction to complete each language level:
- A1 : approx. 60-150 hours (80-200 TU*)
- A2 : approx. 150-260 hours (200-350 TU*)
- B1 : approx. 260-490 hours (350-650 TU*)
- B2 : approx. 450-600 hours (600-800 TU*)
- C1 : approx. 600-750 hours (800-1000 TU*)
- C2 : approx. 750+ hours (1000+ TU*)
*TU = Teaching Unit; a teaching unit consists of 45 minutes of instruction.
The Goethe Institut website does not cite the study where these numbers come from. My guess is that they just published the number of hours spent for each level from their official curriculum.
Another low-reliability source that I found is the Babbel for Business Blog2. They have published the following values for German, English, Spanish, and French:
A1 A2 B1 B2 C1 C2 German 60-150 h 150-262 h 262-487 h 487-600 h 600-750 h 750-1050 h English 60-135 h 135-150 h 262-300 h 375-450 h 525-750 h 750-900 h Spanish 60-75 h 75-150 h 150-300 h 300-413 h 413-675 h 675-825 h French 60-135 h 135-263 h 263-368 h 368-548 h 548-788 h 788-1088 h Note that the values for German are very close to those on the Goethe Institut website, so they were either taken from the same source, or the Babbel blog borrowed them from Goethe Institut. I could not trace a source for the values for English, Spanish, and French.
Plotting the lower bounds of the hours required to reach each CEFR level for German, English, Spanish, and French gives the following graph:

This picture intuitively makes sense. Spanish and English are easier compared to German and French, though I doubt Spanish is that much easier than the rest.
I then plot the lower-upper bound range of hours only for German and English, to make the difference more visible:

If we were to trust the blog post, we would have the following values for German and English:
Lower bound 487 375 Upper bound 600 450 Average 543.5 412.5 I personally don’t trust these values, because they don’t come from any cited sources. However, I will use them simply because they reaffirm a well known fact, which I don’t have the resources to prove scientifically:
Average salary
German Federal Statistical Office (Destatis) publishes the average gross salary in Germany every year. The data from 20223 cites the average hourly wage in Germany as 24.77 euros, which I will round up to euros for simplicity. The average immigrant skilled worker most likely earns more than the average, but I will use this value as a lower bound.
Migration rate
Destatis also published a press release in 20234 that cites a sharp rise in labour migration in 2022. The number of foreign workers in Germany increased by 56,000 in 2022. I will round this up to foreign workers per year, since the trend is upwards.
Percentage of time spent learning the language
I could not find any data on this, so the best I can do is to assume a value that feels conservative enough not to be higher than the real value. I will assume that a quarter of the time spent learning the local language displaces work hours, i.e. .
Final calculation
To summarize, we have the following values:
- It takes around hours of study on average to reach B2 level in German, whereas it takes hours for English.
- The average foreign worker earns euros per hour.
- We assume that , i.e. quarter of the time spent learning the local language displaces work hours.
- The rate of immigration foreign workers per year.
Plugging these values into our formula, we calculate the total value of wages lost per year to language learning for all foreign workers in Germany:
That is, over 200 million euros worth of wages are lost to—or in another perspective, spent on—language education of foreign workers, every year in Germany.
We can then calculate the total value of wages lost per year due to the difference in language complexity between German and English, using the formula we derived earlier:
In other words, the German economy loses at least 49 million euros per year, just because German is harder to learn compared to English.
Conclusion
A lot of the assumptions I made in this case study are conservative:
- I assumed that the rate of immigration to Germany stays constant, whereas it is increasing year by year.
- I assumed that the average migrating skilled worker earns 25 euros per hour, whereas they most likely earn much more.
- I assumed that by the time you finish your B2 course, your German is good enough to start working, whereas it takes much longer to feel confident using the language in a professional setting.
The model further ignores the indirect costs of language complexity, such as not being able to integrate into the society, or even people not moving to Germany in the first place because of the language barrier. Considering those factors, how much higher would you expect the burden of language complexity to be? 100 million euros? 1 billion euros?
What is the cost of not being able to:
- communicate effectively with your colleagues, your boss, your customers?
- read the news, the laws, the contracts?
- understand the culture, the jokes, the idioms?
- express yourself, your ideas, your feelings?
But above all, what does it cost a country if it is unable to teach its language effectively or spread its culture?
Immeasurable.
Should an immigrant take a language curriculum at face value, if the majority of the people who take it after a certain age can never speak as perfect as native level, and end up speaking some simplified grammar at best?
No.
References
-
How long does it take to learn German?, FAQ Page, Goethe Institut ↩
-
How Long Does It Take to Learn a Language?, Anika Wegner, Babbel for Business Blog, 2023-09-01 ↩
-
Earnings by economic branch and occupation, German Federal Statistical Office (Destatis), 2023-06-21 ↩
-
Sharp rise in labour migration in 2022, German Federal Statistical Office (Destatis), 2023-04-27 ↩
-
Cognitive Biases Ranked by Popularity
If you have spent some time on rationalist forums, you might have come across images that try to visualize cognitive biases that humans are prone to:

This specific one has been created by John Manoogian III and Buster Benson, who compiled the list of biases from Wikipedia.
It is a great way to get a sense of the sheer number of biases that exist, but it doesn’t tell you much about how much of the popular mindshare each bias has. All the biases having the same size implies that they are all equally important, but that is obviously not the case. Arguably, for someone who has just started to learn about cognitive biases, confirmation bias should be more important than, say, the Peltzmann effect.
To measure and visualize the popularity of each bias, I…
- ran a Google search with the format
"<insert cognitive bias here>" cognitive biasusing a SERP API, - got the number of search results for each term,
- created a wordcloud using the wordcloud Python package,
- used logarithms of the search count for better scaling,
- used the same colors as the Cognitive Bias Codex for consistency,
- used a shape mask of a brain to make it look cool.
Here is the result:

The bigger the font, the more Google search results there are for that bias, the assumption being Google search results are a good measure of popularity.
Why should you care about the popularity of biases? The more popular or common a bias is, the more likely you are to be affected by it. So it makes sense to study them in decreasing order of popularity, to maximize the benefit to your own thinking. However, this is all statistics—you could still be impacted more by a bias that is smaller in the wordcloud. For example, there was a time when I was very prone to the sunk cost fallacy, even though it doesn’t show up so large in the wordcloud.
Below is a version of the image without the shape mask:

Below are the top 10 biases ranked by Google search result count:
Cognitive bias Search result count Prejudice 8,560,000 Anchoring 1,100,000 Stereotyping 1,080,000 Confirmation bias 992,000 Conservatism 610,000 Essentialism 436,000 Loss aversion 426,000 Attentional bias 374,000 Curse of knowledge 373,000 Social desirability bias 319,000 Click here to see the search result counts for each 188 biases included above.
I have also computed the average search result count for each category of biases, by dividing the total search result count for each category by the number of biases in that category:
Category Average count We discard specifics to form generalities 1,494,378 We notice when something has changed 237,141 We fill in characteristics from stereotypes, generalities, and prior histories 160,170 We are drawn to details that confirm our own existing beliefs 93,350 We think we know what other people are thinking 81,555 To act, we must be confident we can make an impact and feel what we do is important 72,435 We notice things already primed in memory or repeated often 70,835 To get things done, we tend to complete things we’ve invested time and energy in 65,822 To avoid mistakes, we aim to preserve autonomy and group status, and avoid irreversible decisions 65,750 We edit and reinforce some memories after the fact 59,503 We favor simple-looking options and complete information over complex, ambiguous options 52,491 We tend to find stories and patterns even when looking at sparse data 46,375 To stay focused, we favor the immediate, relatable thing in front of us 37,940 Bizarre, funny, visually striking, or anthropomorphic things stick out more than non-bizarre/unfunny things 37,081 We imagine things and people we’re familiar with or fond of as better 34,379 We simplify probabilities and numbers to make them easier to think about 33,881 We notice flaws in others more easily than we notice flaws in ourselves 31,390 We project our current mindset and assumptions onto the past and future 29,418 We reduce events and lists to their key elements 27,638 We store memories differently based on how they were experienced 20,440 Notice that the top few biases such as prejudice and anchoring highly skew the ranking.
Similarly, I have computed the average search result count for each top category of biases:
Top category Average count What Should We Remember? 316,297 Too Much Information 101,842 Need To Act Fast 64,568 Not Enough Meaning 64,134 You can see the code I used to create the figure here.
I will not try to reason as to why some biases are more popular than others, and instead leave that for another post.
- ran a Google search with the format
-
Code-Driven Videos
tl;dr I created Manim Voiceover, a plugin for the Python math animation library Manim that lets you add voiceovers to your Manim videos directly in Python, with both AI voices or actual recordings.
This makes it possible to create “fully code-driven” educational videos in pure Python. Videos can be developed like software, taking advantage of version controlled, git-based workflows (i.e. no more Final.final.final.mp4 :),
It also makes it possible to use AI to automate all sorts of things. For example, I have created a pipeline for translating videos into other languages automatically with i18n (gettext) and machine translation (DeepL).
Follow my Twitter to get updates on Manim Voiceover.
A little background
For those who are not familiar, Manim is a Python library that lets you create animations programmatically, created by Grant Sanderson, a.k.a. 3blue1brown. His visual explainers are highly acclaimed and breathtakingly good (to see an example, click here for his introduction to neural networks).
Manim was originally built for animating math, but you can already see it being used in other domains such as physics, chemistry, computer science, and so on.
Creating any video is a very time-consuming process. Creating an explainer that needs to be mathematically exact is even more so, because the visuals often need to be precise to convey knowledge efficiently. That is why Manim was created: to automate the animation process. It turns out programming mathematical structures is easier than trying to animate them in a video editor.
However, this results in a workflow that is part spent in the text editor (writing Python code), and part in the video editor (editing the final video), with a lot of back and forth in between. The main reason is that the animation needs to be synced with voiceovers, which are recorded separately.
In this post, I will try to demonstrate how we can take this even further by making voiceovers a part of the code itself with Manim Voiceover, and why this is so powerful.
The traditional workflow
Creating a video with Manim is very tedious. The steps involved are usually as follows:
- Plan: come up with a script and a screenplay.
- Record: Record the voiceover with a microphone.
- Animate: Write the Python code for each scene, that will generate the animation videos.
- Edit: Overlay and synchronize the voiceover and animations in a video editor, such as Adobe Premiere.
The workflow is often not linear. The average video requires you to rewrite, re-record, re-animate and re-sync multiple scenes:
The less experience you have making videos, the more takes you will need. Creating such an explainer has a very steep learning curve. It can take up to 1 month for a beginner to create their first few minutes of video.
Enter Manim Voiceover
I am a developer by trade, and when I first tried to create a video with the traditional workflow, I found it harder than it should be. We developers are spoiled, because we get to enjoy automating our work. Imagine that you had to manually compile your code using a hex editor every time you made a change. That is what it felt like to create a video using a video editor. The smallest change in the script meant that I had to re-animate, re-record and re-sync parts of the video, the main culprit being the voiceover.
To overcome this, I thought of a simple idea: Create an API that lets one to add voiceovers directly in Python. Manim Voiceover does exactly that and provides a comprehensive framework for automating voiceovers. Once the entire production can be done in Python, editing in the video editor becomes mostly unnecessary. The workflow becomes:
- Plan: Same as before.
- Animate: Develop the video with an AI-generated voiceover, all in Python.
- Record: When the final revision is ready, record the actual voiceover with Manim Voiceover’s recorder utility. The audio is transcribed with timestamps and inserted at the right times automatically.
A little demo—see how a video would look like at the end of step (2):
And watch below to see how it would look like at the end of step (3), with my own voice:
I explain why this is so powerful below:
Zero-cost revisions
In the previous method, making modifications to the script has a cost, because you need to re-record the voiceover and readjust the scenes in the video editor. Here, making modifications is as easy as renaming a variable, since the AI voiceover is generated from code automatically. This saves a lot of time in the production process:
This lets videos created with Manim to be “fully code-driven” and take advantage of open source, collaborative, git-based workflows. No manual video editing needed, and no need to pay for overpriced video editing software:
(Or at least drastically reduced need for them)
Increased production speed
From personal experience and talking to others who have used it, Manim Voiceover increases production speed by a factor of at least 2x, compared to manual recording and editing.
Note: The current major bottlenecks are developing the scene itself and waiting for the render. Regarding render speed: Manim CE’s Cairo renderer is much slower then ManimGL’s OpenGL renderer. Manim Voiceover currently only supports Manim CE, but it is on my roadmap to add support ManimGL.
The API in a nutshell
This all sounds great, but how does it look like in practice? Let’s take a look at the API. Here is a “Hello World” example for Manim, drawing a circle:
from manim import * class Example(Scene): def construct(self): circle = Circle() self.play(Create(circle))Here is the same scene, with a voiceover that uses Google Translate’s free text-to-speech service:
from manim import * from manim_voiceover import VoiceoverScene from manim_voiceover.services.gtts import GTTSService class VoiceoverExample(VoiceoverScene): def construct(self): self.set_speech_service(GTTSService(lang="en")) circle = Circle() with self.voiceover(text="This circle is drawn as I speak."): self.play(Create(circle))Notice the
withstatement. You can chain such blocks back to back, and Manim will vocalize them in sequence:with self.voiceover(text="This circle is drawn as I speak."): self.play(Create(circle)) with self.voiceover(text="Let's shift it to the left 2 units."): self.play(circle.animate.shift(2 * LEFT))The code for videos made with Manim Voiceover generally looks cleaner, since it is compartmentalized into blocks with voiceovers acting as annotations on top of each block.
See how this is rendered:
Record
To record an actual voiceover, you simply change a single line of code:
# self.set_speech_service(GTTSService(lang="en")) # Comment this out self.set_speech_service(RecorderService()) # Add this lineCurrently, rendering with
RecorderServicestarts up a voice recorder implemented as a command line utility. The recorder prompts you to record each voiceover in the scene one by one and inserts audio at appropriate times. In the future, a web app could make this process even more seamless.Check out the documentation for more examples and the API specification.
Auto-translating videos
Having a machine readable source for voiceovers unlocks another superpower: automatic translation. Manim Voiceover can automatically translate your videos to any language, and even generate subtitles in that language. This will let educational content creators reach a much wider audience.
Here is an example of the demo translated to Turkish and rendered with my own voice:
To create this video, I followed these steps:
- I wrapped transtable strings in my demo inside
_()per gettext convention. For example, I changedtext="Hey Manim Community!"totext=_("Hey Manim Community!"). - I ran
manim_translate blog-translation-demo.py -s en -t tr -d blog-translation-demo, which created thelocalefolder, called DeepL’s API to translate the strings, and saved them underlocale/tr/LC_MESSAGES/blog-translation-demo.po.
- Here,
-sstands for source language, -tstands for target language,- and
-dstands for the gettext domain.
- I edited the
.pofile manually, because the translation was still a bit off. - I ran
manim_render_translation blog-translation-demo.py -s BlogTranslationDemo -d blog-translation-demo -l tr -qh, which rendered the final video.
Check out the translation page in the docs for more details. You can also find the source code for this demo here.
Here is a Japanese translation, created the same way but with an AI voiceover:
Note that I have very little knowledge of Japanese so that the translation might be off, but I was still able to create it with services that are freely available online. This is to foreshadow how communities could create and translate educational videos in the future:
- Video is created using Manim/Manim Voiceover and is open-sourced.
- The repo is connected to a CI/CD service that tracks the latest changes, re-renders and deploys the video to a permalink.
- When a translation in a language is requested, said service automatically generates it using AI translation and voiceover.
- The community can then review the translation and voiceover, make changes if necessary, and record a human voiceover if they want to.
- All the different versions and translations of the video are seamlessly deployed, similar to how ReadTheDocs deploys software documentation.
That is the main idea of my next project, GitMovie. If this excites you, leave your email address on the form on the website to get notified when it launches.
Conclusion
While using Manim Voiceover might seem tedious to some who are already using Manim with a video editor, I guarantee that it is overall more convenient than using a video editor when it comes to adding voiceovers to scenes. Feel free to create an issue if you have a use case that is currently not covered by Manim Voiceover.
What is even more interesting, Manim Voiceover can provide AI models such as GPT-4 with a convenient way to generate mathematically precise videos. Khan Academy has recently debuted a private release of Khanmigo, their GPT-4 based AI teacher. Imagine that Khanmigo could create a 3blue1brown-level explainer in a matter of minutes, for any question you ask! (I already tried to make GPT-4 output Manim code, but it is not quite there yet.)
To see why this is powerful, check out my video rendering of Euclid’s Elements using Manim Voiceover (part 1):
This video itself is pedagogically not very effective because books do not necessarily translate into good video scripts. But it serves as preparation for the point that I wanted to make with this post:
Having a machine-readable source and being able to program voiceovers allowed me to generate over 10 hours of video in less than a few days. In a few years, AI models will make such approaches 1000 times easier, faster and cheaper for everyone.
Imagine being able to auto-generate the “perfect explainer” for every article on Wikipedia, every paper on arXiv, every technical specification that would otherwise be too dense. In every language, available instantly around the globe. Universal knowledge, accessible by anyone who is willing to learn. Thanks to 3blue1brown, Manim and similar open source projects, all of this will be just a click away!
-
Microtonal Piano
I built a web-based microtonal piano that lets you explore music beyond the standard 12-tone equal temperament.
Most Western music uses 12 equally spaced notes per octave. But this is just one of many possible tuning systems. Microtonal music explores the spaces between these notes, using tuning systems with different numbers of divisions per octave or entirely different mathematical relationships between pitches.
The app lets you:
- Play with different tuning systems (various equal temperaments, just intonation, etc.)
- Hear how the same melody sounds in different tunings
- Explore the mathematical relationships between pitches
Try it out: osolmaz.github.io/microtonal-piano
-
Take Control of Your Feeds
A digital feed is an online stream of content which gets updated as new content is pushed by the feed’s sources. Generally, content is created by users on the social media platform, to be consumed by their followers.
All popular social media platforms feature some type of feed: Twitter, Instagram, Reddit, Facebook. Operators of these platforms benefit from increased engagement by their users, so they employ techniques designed to achieve that end. Unfortunately, they often do so at the expense of their users’ well-being. Below are 7 rules to help you retain control over your screen time, without having to leave social media for good, ordered from most important to least important.
Rule #1: Avoid non-chronological feeds
On most online platforms, the order of content is determined by an algorithm designed to maximize user engagement, i.e. addict you and keep you looking at ads for as long as possible. Examples: Facebook news feed, Twitter “top tweets”, Instagram explore tab, Tiktok.
Rule #2: No feeds or social media apps on the phone
Your phone is always within your reach. Access feeds only on your laptop, in order not to condition yourself to constantly check it. Don’t install social media or video apps on your phone.
Rule #3: Follow with purpose
Your digital experience changes with each new person/source you follow. Be mindful about the utility of the information you would obtain before following a new source.
Rule #4: Limit the number of people/things you follow
The amount of content you will have to go through increases roughly linearly with the number of sources you follow. You probably won’t see everything your 500 followees share—maybe it’s time to unfollow some of them.
Rule #5: Schedule and limit your exposure
Your brain has a limited capacity to process and hold information. Schedule a certain hour of the day to receive it, and don’t surpass it. Example: No more than 30 minutes of social media, restricted to 10–11 am.
Rule #6: Block generously and ruthlessly
If you don’t like what you’re seeing, block or unfollow immediately. This is the hardest when someone posts content that is sometimes useful, but otherwise annoying too. Generally, we put up with it for too long until we block someone.
Rule #7: Mute words
Avoid toxic memes by muting related words, e.g. Trump, ISIS. This will filter out any post that contains that word. Click here to do it on Twitter now—it’s easy.
Follow these simple set of rules, and restore your control over social media and your digital experience in no time.
-
Blockchain Fee Volatility
Ethereum is a platform for distributed computing that uses a blockchain for data storage, thus inheriting the many benefits blockchain systems enjoy, such as decentralization and permissionlessness. It also inherited the idea of users paying nodes a fee to get their transactions included in the blockchain. After all, computation on the blockchain is not an infinite resource, and it should be allocated to users who actually find value in it. Otherwise, a feeless blockchain can easily be spammed and indefinitely suffer a denial-of-service attack.
Blockchain state advances on a block by block basis. On a smart contract platform, the quantity of computation as a resource is measured in terms of the following factors:
- Bandwidth: The number of bits per unit time that the network can achieve consensus on.
- Computing power: The average computing power of an individual node.
- Storage: The average storage capacity of an individual node.
The latter two are of secondary importance, because the bottleneck for the entire network is not the computing power or storage capacity of an individual node, but the overall speed of communicating the result of a computation to the entire network. In Bitcoin and Ethereum, that value is around 13 kbps1, calculated by dividing average full block size by average block time. Trying to increase that number, either by increasing the maximum block size or decreasing block time, indeed results in increased computational capacity. However it also increases the uncle rate2, thereby decreasing the quality of consensus—a blockchain’s main value proposition.
Moreover, users don’t just submit bits in their transactions. In Bitcoin, they submit inputs, outputs, amounts etc3. In Ethereum, they can just submit a sender and a receiver of an amount of ETH, or they can also submit data, which can be an arbitrary message, function call to a contract or code to create a contract. This data, which alters Ethereum’s world state, is permanently stored on the blockchain.
Ethereum is Turing complete, and users don’t know when and in which order miners will include their transactions. In other words, users have no way of predicting with 100% accuracy the total amount of computational resources their function call will consume, if that call depends on the state of other accounts or contracts4. Furthermore, even miners don’t know it up until the point they finish executing the function call. This makes it impractical for users to set a lump sum fee that they are willing to pay to have their transaction included, because a correlation between a transaction’s fee and its utilization of resources cannot be ensured.
To solve this problem, Ethereum introduced the concept of gas as a unit of account for the cost of resources utilized during transaction execution. Each instruction featured in the Ethereum Virtual Machine has a universally agreed cost in gas, proportional to the scarcity of the used resource5. Then instead of specifying a total fee, users submits a gas price in ETH and the maximum total gas they are willing to pay.
The costliest operations on Ethereum are those of non-volatile storage and access6, but these need not occupy space in a block. It’s the transactions themselves that are stored in the blocks and thus consume bandwidth. The gas corresponding to this consumption is called “intrinsic gas” (see the Yellow Paper), and it’s one of the reasons for the correlation between gas usage and block size:
The vertical clusterings at 4.7m, 6.7m and 8m gas correspond to current and previous block gas limits. Gas costs of instructions should indeed be set in such a way that the correlation between a resource and overall gas usage should increase with the degree of bottleneck.
Gas Supply and Demand
The demand for transacting/computing on creates its own market, both similar and dissimilar to the markets of tangible products that we are used to. What is more important to us is the supply characteristics of this market. Supplied quantities aren’t derived from individual capacities and decisions of the miners, but from network bottlenecks. A limit is set on maximum gas allowed per block.
Supplied quantity is measured in terms of gas supplied per unit time, similar to bandwidth. Individual miners contribute hashrate to the network, but this doesn’t affect throughput. The difficulty adjustment mechanism ensures that network throughput remains the same, unless universally agreed parameters are changed by collective decision.
Moreover, the expenditure of mining a block far exceeds the expenditure of executing a block. In other words, changes in overall block fullness doesn’t affect miner operating expenses. Therefore, marginal cost is roughly zero, up until the point supply hits maximum throughput—where blocks become 100% full. At that point, marginal cost becomes infinite. This is characterized by a vertical supply curve located at maximum throughput, preceded by a horizontal supply curve.
This means that given a generic monotonically decreasing demand curve and a certain shift in demand, we can predict the change in the gas price, and vice versa. The price is located at the point where the demand curve intersects the supply curve. Major shifts in price starts to occur only when blocks become full. Past that point, users are basically bidding higher and higher prices to get their transactions included. See the figure below for an illustration.

This sort of econometric analysis can be done simply by looking at block statistics. Doing so reveals 2 types of trends in terms of period:
- Intraday volatility: Caused by shifts in demand that repeat periodically every day.
- Long term shifts: Caused by increases or decreases in the level of adoption, and not periodic.
Note: This view of the market ignores block rewards, but that is OK in terms of analyzing gas price volatility, because block rewards remain constant for very long periods of time. However, a complete analysis would need to take block rewards into account, because they constitute the majority of miner revenue.
Daily Demand Cycle and Intraday Volatility
Demand for gas isn’t distributed equally around the globe. Ethereum users exist in every inhabited continent, with the highest demand seen in East Asia, primarily China. Europe+Africa and the Americas seem to be hand in hand in terms of demand. This results in predictable patterns that follow the peaks and troughs of human activity in each continent. The correlation between gas usage and price is immediately noticeable, demonstrated by a 5 day period from March 2019.

The grid marks the beginnings of the days in UTC, and the points in the graph correspond to hourly averages, calculated as:
- Average hourly gas usage per block = Total gas used in an hour / Number of blocks in an hour
- Average hourly gas price = Total fees collected in an hour / Total gas used in an hour
Averaging hourly gives us a useful benchmark to compare, because block-to-block variation in these attributes is too much for an econometric analysis.
One can see above that the average gas price can change up to 2 to 4 times in a day. This shows us that Ethereum has found real use around the world, but also that there exists a huge UX problem in terms of gas prices.
Dividing the maximum gas price in a day by the minimum, we obtain a factor of intraday volatility:

Ethereum has witnessed gas price increases of up to 100x in a day. Smoothing out the data, we can see that the gas price can change up to 4x daily on average.
To understand the effect of geographic distribution on demand, we can process the data above to obtain a daily profile for gas usage and price. We achieve this by dividing up the yearly data set into daily slices, and standardizing each slice in itself. Then the slices are superimposed and their mean is calculated. The mean curve, though not numerically accurate, makes sense in terms of ordinal difference between the hours of an average day.

One can clearly see that gas usage and price are directly correlated. At 00:00 UTC, it’s been one hour since midnight in Central Europe, but that’s no reason for a dip in demand—China just woke up. The first dip is seen at 03:00 when the US is about to go to sleep, but then Europe wakes up. The demand dips again after 09:00, but only briefly—the US just woke up. We then encounter the biggest dip from 15:00 to 23:00 as China goes to sleep.
Surely there must be a way to absorb this volatility! Solving this problem would greatly improve Ethereum’s UX and facilitate even greater mainstream adoption.
Long Term Shifts in Demand
The long term—i.e. 1 day—shifts in demand are unpredictable and non-periodic. They are caused by adoption or hype for certain applications or use cases on Ethereum, like
- ICOs,
- decentralized exchanges,
- DAI and CDPs,
- interest bearing Dapps,
- games such as Cryptokitties and FOMO3D,
- and so on.
These shifts in price generally mirror ETH’s own price. In fact, it’s not very objective to plot a long term gas price graph in terms of usual Gwei, because most people submit transactions considering ETH’s price in fiat. For that reason, we denote gas price in terms of USD per one million gas, and plot it on a logarithmic scale:

The price of gas has seen an increase of many orders of magnitude since the launch of the mainnet. The highest peak corresponds to the beginning of 2018 when the ICO bubble burst, similar to the price of ETH. Although highly critical for users and traders, this sort of price action is not very useful from a modeling perspective.
Conclusion
The volatility in gas price stems from the lack of scalability. In 2019 on Ethereum, daily gas price difference stayed over 2x on average. The cycle’s effect is high enough to consider it as a recurring phenomenon that requires its own solution.
I think the narrative that gas price volatility is caused only by the occasional game/scam hype is incomplete—in a blockchain that has gained mainstream adoption such as Ethereum, the daily cycle of demand by itself is enough to cause volatility that harms the UX for everyone around the globe.
While increasing scalability is the ultimate solution, users may still benefit from mechanisms that allow them to hedge themselves against price increases, like reserving gas on a range of block heights. This would make a good topic for a future post.
-
As of October 2019. ↩
-
The rate at which orphaned blocks show up. ↩
-
But in practice, they can estimate it reliably most of the time. ↩
-
See Appendix G (Fee Schedule) and H (Virtual Machine Specification) of the Ethereum Yellow Paper. ↩
-
https://medium.com/coinmonks/storing-on-ethereum-analyzing-the-costs-922d41d6b316 ↩
-
Equilibrium in Cryptoeconomic Networks
A cryptoeconomic network is a network where
- nodes perform tasks that are useful to the network,
- incur costs while doing so,
- and get compensated through fees paid by the network users, or rewards generated by the network’s protocol (usually in the form of a currency native to the network).
Reward generation causes the supply of network currency to increase, resulting in inflation. Potential nodes are incentivized to join the network because they see there is profit to be made, especially if they are one of the early adopters. This brings the notion of a “cake” being shared among nodes, where the shares get smaller as the number of nodes increases.
Since one of the basic properties of a currency is finite supply, a sane protocol cannot have the rewards increase arbitrarily with more nodes. Thus the possible number of nodes is finite, and can be calculated using costs and rewards, given that transaction fees are negligible. The rate by which rewards are generated determines the sensitivity of network size to changes in costs and other factors.
Let be the number of nodes in a network, which perform the same work during a given period. Then we can define a generalized reward per node, introduced by Buterin1:
where is a constant and is a parameter adjusting how the rewards scale with .
Then the total reward issued is equal to
The value of determines how the rewards scale with :
Range Per node reward Total reward Increase with increasing Increase with increasing Decrease with increasing Increase with increasing Decrease with increasing Decrease with increasing Below is a table showing how different values of corresponds to different rewarding schemes, given full participation.
Description Constant interest rate Middle ground between 0 and 1 (Ethereum 2.0) Constant total reward (Ethereum 1.0, Bitcoin in the short run) No reward (Bitcoin in the long run) The case results in unlimited network growth, causes runaway inflation and is not feasible. The case is also not feasible due to drastic reduction in rewards. The sensible range is , and we will explore the reasons below.
Estimating Network Size
We relax momentarily the assumption that nodes perform the same amount of work. The work mentioned here can be the hashing power contributed by a node in a PoW network, the amount staked in a PoS network, or the measure of dedication in any analogous system.
Let be the work performed by node . Assuming that costs are incurred in a currency other than the network’s—e.g. USD—we have to take the price of the network currency into account. The expected value of ‘s reward is calculated analogous to (1)
Introducing variable costs and fixed costs , we can calculate ‘s profit as
Assuming every node will perform work in a way to maximize profit, we can estimate given others’ effort:
In a network where nodes have identical costs and capacities to work, all converge to the same equilibrium value . Equating , we can solve for that value:
Plugging back above, we can calculate for the case of economic equilibrium where profits are reduced to zero due to perfect competition:
which yields the following implicit equation
It is a curious result that for the idealized model above, network size does not depend on variable costs. In reality, however, we have an uneven distribution of all costs and work capacities. Nevertheless, the idealized model can still yield rules of thumb that are useful in protocol design.
An explicit form for is not possible, but we can calculate it for different values of . For , we have
as demonstrated by Thum2.
For , the explicit forms would take too much space. For brevity’s sake, we can approximate by
given . The closer to zero, the better the approximation.
We also have
which shows that for , the network grows without bounds and render the network currency worthless by inflating it indefinitely. Therefore there is no equilibrium.
For , rewards and number of nodes decrease with increasing . Finally, we have
given that transaction fees are negligible.
 Number of nodes versus , on a log scale. The
straight lines were
solved for numerically, and corresponding approximations were overlaid with
markers, except for and .
Number of nodes versus , on a log scale. The
straight lines were
solved for numerically, and corresponding approximations were overlaid with
markers, except for and .For , a x change in underlying factors will result in x change in network size. For , the change will be x.
Let . Then a x increase in price or rewards will result in a x increase in network size. Conversely, a x increase in fixed costs will result in x decrease in network size. If we let , a x change to the factors result in x change in network size, and so on.
References
-
Buterin V., Discouragement Attacks, 16.12.2018. ↩
-
Thum M., The Economic Cost of Bitcoin Mining, 2018. ↩
-
Scalable Reward Distribution with Changing Stake Sizes
This post is an addendum to the excellent paper Scalable Reward Distribution on the Ethereum Blockchain by Batog et al.1 The outlined algorithm describes a pull-based approach to distributing rewards proportionally in a staking pool. In other words, instead of pushing rewards to each stakeholder in a for-loop with complexity, a mathematical trick enables keeping account of the rewards with complexity and distributing only when the stakeholders decide to pull them. This allows the distribution of things like rewards, dividends, Universal Basic Income, etc. with minimal resources and huge scalability.
The paper by Bogdan et al. assumes a model where stake size doesn’t change once it is deposited, presumably to explain the concept in the simplest way possible. After the deposit, a stakeholder can wait to collect rewards and then withdraw both the deposit and the accumulated rewards. This would rarely be the case in real applications, as participants would want to increase or decrease their stakes between reward distributions. To make this possible, we need to make modifications to the original formulation and algorithm. Note that the algorithm given below is already implemented in PoWH3D.
In the paper, the a is distributed to a participant with an associated as
where subscript denotes the values of quantities at distribution of reward and is the sum of all active stake deposits.
Since we relax the assumption of constant stake, we rewrite it for participant ‘s stake at reward :
Then the total reward participant receives is calculated as
Note that we can’t take stake out of the sum as the authors did, because it’s not constant. Instead, we introduce the following identity:
Identity: For two sequences and , we have
Proof: Substitute on the LHS. Distribute the multiplication. Modify the index on the first term. Separate the last element of the sum from the first term and combine the remaining sums since they have the same bounds.
We assume rewards represented by the indices , and apply the identity to total reward to obtain
We make the following definition:
and define the change in stake between rewards and :
Then, we can write
This result is similar to the one obtained by the authors in Equation 5. However, instead of keeping track of at times of deposit for each participant, we keep track of
In this case, positive corresponds to a deposit and negative corresponds to a withdrawal. is zero if the stake of participant remains constant between and . We have
The modified algorithm requires the same amount of memory, but has the advantage of participants being able to increase or decrease their stakes without withdrawing everything and depositing again.
Furthermore, a practical implementation should take into account that a participant can withdraw rewards at any time. Assuming is represented by a mapping
reward_tally[]which is updated with each change in stake sizereward_tally[address] = reward_tally[address] + change * reward_per_tokenwe can update
reward_tally[]upon a complete withdrawal of ‘s total accumulated rewards:reward_tally[address] = stake[address] * reward_per_tokenwhich sets ‘s rewards to zero.
A basic implementation of the modified algorithm in Python is given below. The following methods are exposed:
deposit_staketo deposit or increase a participant stake.distributeto fan out reward to all participants.withdraw_staketo withdraw a participant’s stake partly or completely.withdraw_rewardto withdraw all of a participant’s accumulated rewards.
Caveat: Smart contracts use integer arithmetic, so the algorithm needs to be modified to be used in production. The example does not provide a production ready code, but a minimal working example to understand the algorithm.
class PullBasedDistribution: "Constant Time Reward Distribution with Changing Stake Sizes" def __init__(self): self.total_stake = 0 self.reward_per_token = 0 self.stake = {} self.reward_tally = {} def deposit_stake(self, address, amount): "Increase the stake of `address` by `amount`" if address not in self.stake: self.stake[address] = 0 self.reward_tally[address] = 0 self.stake[address] = self.stake[address] + amount self.reward_tally[address] = self.reward_tally[address] + self.reward_per_token * amount self.total_stake = self.total_stake + amount def distribute(self, reward): "Distribute `reward` proportionally to active stakes" if self.total_stake == 0: raise Exception("Cannot distribute to staking pool with 0 stake") self.reward_per_token = self.reward_per_token + reward / self.total_stake def compute_reward(self, address): "Compute reward of `address`" return self.stake[address] * self.reward_per_token - self.reward_tally[address] def withdraw_stake(self, address, amount): "Decrease the stake of `address` by `amount`" if address not in self.stake: raise Exception("Stake not found for given address") if amount > self.stake[address]: raise Exception("Requested amount greater than staked amount") self.stake[address] = self.stake[address] - amount self.reward_tally[address] = self.reward_tally[address] - self.reward_per_token * amount self.total_stake = self.total_stake - amount return amount def withdraw_reward(self, address): "Withdraw rewards of `address`" reward = self.compute_reward(address) self.reward_tally[address] = self.stake[address] * self.reward_per_token return reward # A small example addr1 = 0x1 addr2 = 0x2 contract = PullBasedDistribution() contract.deposit_stake(addr1, 100) contract.distribute(10) contract.deposit_stake(addr2, 50) contract.distribute(10) print(contract.withdraw_reward(addr1)) print(contract.withdraw_reward(addr2))Conclusion
With a minor modification, we improved the user experience of the Constant Time Reward Distribution Algorithm first outlined in Batog et al., without changing the memory requirements.
-
Batog B., Boca L., Johnson N., Scalable Reward Distribution on the Ethereum Blockchain, 2018. ↩
-
Bitcoin's Inflation
New bitcoins are minted with every new block in the Bitcoin blockchain, called “block rewards”, in order to incentivize people to mine and increase the security of the network. This inflates Bitcoin’s supply in a predictable manner. The inflation rate halves every 4 years, decreasing geometrically.
There have been some confusion of the terminology, like people calling Bitcoin deflationary. Bitcoin is in fact not deflationary—that implies a negative inflation rate. Bitcoin rather has negative inflation curvature: Bitcoin’s inflation rate decreases monotonically.
An analogy from elementary physics should clear things up: Speaking strictly in terms of monetary inflation,
- displacement is analogous to inflation/deflation, as in total money minted/burned, without considering a time period. Dimensions: .
- Velocity is analogous to inflation rate, which defines total money minted/burned in a given period. Dimensions: .
- Acceleration is analogous to inflation curvature, which defines the total change in inflation rate in a given period. Dimensions: .
Given a supply function as a function of time, block height, or any variable signifying progress,
- inflation is a positive change in supply, , and deflation, .
- Inflation rate is the first derivative of supply, .
- Inflation curvature is the second derivative of supply, .
In Bitcoin, we have the supply as a function of block height: . But the function itself is defined by the arithmetic1 initial value problem
where is the initial inflation rate, is the rate by which the inflation rate will decrease, is the milestone number of blocks at which the decrease will take place, and is the floor function. In Bitcoin, we have , and . Here is what it looks like:
 Bitcoin inflation rate versus block height.
Bitcoin inflation rate versus block height.We can directly compute inflation curvature:
is nonzero only when is a multiple of . For , is either zero or negative, which is the case for Bitcoin.
Finally, we can come up with a closed-form by solving the initial value problem (1):
Here is what the supply function looks like for Bitcoin:
 Bitcoin supply versus block height.
Bitcoin supply versus block height.And the maximum number of Bitcoins to ever exist are calculated by taking the limit
Summary
The concept of inflation curvature was introduced. The confusion regarding Bitcoin’s inflation mechanism was cleared with an analogy. The IVP defining Bitcoin’s supply was introduced and solved to get a closed-form expression. Inflation curvature for Bitcoin was derived. The maximum number of Bitcoins to ever exist was derived and computed.
-
Because is defined over positive integers. ↩
-
The Anatomy of a Block Stuffing Attack
Block stuffing is a type of attack in blockchains where an attacker submits transactions that deliberately fill up the block’s gas limit and stall other transactions. To ensure inclusion of their transactions by miners, the attacker can choose to pay higher transaction fees. By controlling the amount of gas spent by their transactions, the attacker can influence the number of transactions that get to be included in the block.
To control the amount of gas spent by the transaction, the attacker utilizes a special contract. There is a function in the contract which takes as input the amount of gas that the attacker wants to burn. The function runs meaningless instructions in a loop, and either returns or throws an error when the desired amount is burned.
For example let’s say that the average gas price has been 5 Gwei in the last 10 blocks. In order to exert influence over the next block, the attacker needs to submit transactions with gas prices higher than that, say 100 Gwei. The higher the gas price, the higher the chance of inclusion by miners. The attacker can choose to divide the task of using 8,000,000 gas—current gas limit for blocks—into as many transactions as they want. This could be 80 transactions with 100,000 gas expenditure, or 4 transactions with 2,000,000 gas expenditure.
Deciding on how to divide the task is a matter of maximizing the chance of inclusion, and depends on the factors outline below.
Miners’ strategy for selecting transactions
Miners want to maximize their profit by including transactions with highest fees. In the current PoW implementation of Ethereum, mining the block takes significantly more time than executing the transactions. So let’s assume all transactions in the pool are trivially executed as soon as they arrive and miners know the amount of gas each one uses.
For miners, maximizing profit is an optimum packing problem. Miners want to choose a subset of the transaction pool that gives them maximum profit per block. Since there are at least tens of thousands of transactions in the pool at any given time, the problem can’t be solved by brute-forcing every combination. Miners use algorithms that test a feasible number of combinations and select the one giving the highest reward.
A block stuffer’s main goal is to target the selection process by crafting a set of transactions that has the highest chance of being picked up by miners in a way that will deplete blocks’ gas limits. They can’t devise a 100% guaranteed strategy since each miner can use a different algorithm, but they can find a sweet spot by testing out the whole network.
(In a PoS system, our assumptions would be wrong since executing transactions is not trivial compared to validating blocks. Validators would need to develop more complex strategies depending on the PoS implementation.)
The transactions the attacker wants to stall:
It could be so that the attacker wants to stall transactions with a specific contract. If the function calls to that contract use a distinctively high amount of gas, say between 300,000 and 500,000, then the attacker has to stuff the block in a way that targets that range.
For example, the attacker can periodically submit transactions with very high prices where
If the attacker is targeting transactions within a range of , they can choose the first transactions to deplete gas in short steps, and submit to deplete the remaining gas with a relatively higher price. Note that the revenue from including a single transaction is
As gas usage decreases, the probability of being picked up by miners decreases, so prices should increase to compensate.
Example: Fomo3D
Fomo3D is a gambling game where players buy keys from a contract and their money goes into a pot. At the beginning of each round, a time counter is initiated which starts counting back from 24 hours. Each bought key adds 30 seconds to the counter. When the counter hits 0, the last player to have bought a key wins the majority of the pot and the rest is distributed to others. The way the pot is distributed depends on the team that the winner belongs to.
Key price increases with increasing key supply, which makes it harder and harder to buy a key and ensures the round will end after some point. In time, the stakes increase and the counter reduces to a minimum, like 2 minutes. At this point, the players pay both high gas and key prices to be “it” and win the game. Players program bots to buy keys for them, and winning becomes a matter of coding the right strategy. As you can understand from the subject, the first round was won through a block stuffing attack.
On August 22 2018, the address 0xa16…f85 won 10,469 ETH from the first round by following the strategy I outlined above. The winner managed to be the last buyer in block 6191896 and managed to stall transactions with Fomo3D until block 6191909 for 175 seconds, ending the round. Some details:
-
Fomo3D Long contract address: 0xA62…Da1
-
Last transaction by the winner before the attack starts: 0x7a0…349
-
Transaction ending the round and firing the
onBuyAndDistributeevent which distributes the pot: 0xa14…012 -
Transaction where winner withdraws the prize: 0xe08…508
-
Contract used for block stuffing: 0x18e…801
-
Other addresses possibly belonging to the winner: 0x3c3…f27, 0xc6a…3e2, 0x81e…0ac, 0xc96…590, 0xd27…642, 0x18d…a9a, 0x87c…4ef, 0x9da…0cf, 0x7dd…c4c, 0xb1d…aef, 0x1a6…d56, 0xf6e…059, 0x1dd…a69, 0x061…63b, 0x00c…776, 0xa94…eb8, 0xf03…1f2
-
Other contracts possibly deployed by the winner for testing prior to the attack: 0xaf1…eae, 0x0c0…5ad, 0x88e…d04, 0x4f4…6f8, 0x487…4e5
The user addresses above were scraped from the Ethereum transaction graph as being linked to a primary account which supplied them with funds. The contract addresses were scraped from 0-valued transactions sent from user addresses. These have a distance of 1, there may be other addresses involved with greater distances.
Below are details of the last 4 blocks preceding the end of the round. The rows highlighted with yellow are transactions submitted by the attacker. The crossed out rows are failed transactions. All transactions by the attacker were submitted with a 501 Gwei gas price, and stuffing a single block costed around 4 ETH. The calls to buy keys generally spend around 300,000~500,000 gas, depending on which function was called. Below, you see the successfully stuffed block 6191906.
Block 6191906 Idx From To Hash ETH sent Gas Price
[Gwei]Gas Limit Gas Used ETH spent
on gas0 0xF03…1f2 0x18e…801 0xb97…8e4 0 501.0 4,200,000 4,200,000 2.1042 1 0x87C…4eF 0x18e…801 0x96f…1b0 0 501.0 3,600,000 3,600,000 1.8036 2 0xf6E…059 0x18e…801 0x897…2b3 0 501.0 200,000 200,000 0.1002 Sum 0 1503.01 8,000,000 8,000,000 4.0080 Block 6191907 was a close call for the winner, because their transactions picked up for the block did not amount up to 8,000,000 and the other transaction was a call to Fomo3D by an opponent to buy keys. Note that it has a gas price of 5559 Gwei, which means either the bot or person who submitted the transaction was presumably aware of the attack. The transaction failed due to low gas limit, presumably due to a miscalculation by the bot or the person.
Block 6191907 Idx From To Hash ETH sent Gas Price
[Gwei]Gas Limit Gas Used ETH spent
on gas0 0x32A…370 0xA62…Da1 0x5e7…be1 0.0056 5559.7 379,000 379,000 2.1071 1 0xC6A…3E2 0x18e…801 0xb8b…40c 0 501.0 3,900,000 3,900,000 1.9539 2 0xD27…642 0x18e…801 0xbcf…c62 0 501.0 3,300,000 3,300,000 1.6533 3 0x00c…776 0x18e…801 0xf30…337 0 501.0 400,000 400,000 0.2004 Sum 0.0056 7062.71 7,979,000 7,979,000 5.9147 Transactions in block 6191908 belonged to the attacker except for one irrelevant transfer. This block is also considered successfully stuffed, since the 7,970,000 gas usage by the attacker leaves no space for a call to buy keys.
Block 6191908 Idx From To Hash ETH sent Gas Price
[Gwei]Gas Limit Gas Used ETH spent
on gas0 0xD27…642 0x18e…801 0x74a…9b1 0 501.0 3,300,000 3,300,000 1.6533 1 0x7Dd…c4c 0x18e…801 0x48c…222 0 501.0 2,700,000 2,700,000 1.3527 2 0x3C3…f27 0x18e…801 0x01b…4aa 0 501.0 1,800,000 1,800,000 0.9018 3 0xa94…eb8 0x18e…801 0x776…d43 0 501.0 170,000 170,000 0.0851 4 0xbFd…1b4 0x663…d31 0x3a6…ba1 0.05 100.0 21,000 21,000 0.0021 Sum 0.05 2104.01 7,991,000 7,991,000 3.9950 By block 6191909, the counter has struck zero—more like current UTC time surpassed the round end variable stored in the contract—and any call to Fomo3D would be the one to end the round and distribute the pot. And the first transaction in the block is—wait for it—a call to Fomo3D to buy keys by the opponent whose transaction failed a few blocks earlier, submitted with 5562 Gwei. So the guy basically paid 1.7 ETH to declare the attacker the winner!
Block 6191909 Idx From To Hash ETH sent Gas Price
[Gwei]Gas Limit Gas Used ETH spent
on gas0 0x32A…370 0xA62…Da1 0xa14…012 0.0056 5562.2 379,000 304,750 1.6950 1 0xC96…590 0x18e…801 0xf47…9ca 0 501.0 2,200,000 37,633 0.0188 2 0xb1D…aEF 0x18e…801 0xe4c…edb 0 501.0 1,400,000 37,633 0.0188 3 0x18D…A9A 0x18e…801 0xf3a…995 0 501.0 800,000 37,633 0.0188 … … … … … … … … … Another thing to note is that the attacker probably crafted the spender contract to stop the attack when the round has ended, presumably to cut costs. So the 37,633 gas used by the contract are probably to call the Fomo3D contract to check round status. All these point out to the fact that the attacker is an experienced programmer who knows their way around Ethereum.
Here, you can see the details of the 100 blocks preceding the end of the round, with the additional information of ABI calls and events fired in transactions.
Since the end of the first round, 2 more rounds ended with attacks similar to this one. I didn’t analyze all of them because it’s too much for this post, but here are some details if you want to do it yourselves.
Round Address winning the pot Winner’s last tx before the end of the round Block containing that tx Tx ending the round Block containing that tx Tx where winner withdraws prize Amount won [ETH] Contract used for block stuffing 1 0xa169df5ed3363cfc4c92ac96c6c5f2a42fccbf85 0x7a06d9f11e650fbb2061b320442e26b4a704e1277547e943d73e5b67eb49c349 6191896 0xa143a1ee36e1065c3388440ef7e7b38ed41925ca4799c8a4d429fa3ee1966012 6191909 0xe08a519c03cb0aed0e04b33104112d65fa1d3a48cd3aeab65f047b2abce9d508 10,469 0x18e1b664c6a2e88b93c1b71f61cbf76a726b7801 2 0x18a0451ea56fd4ff58f59837e9ec30f346ffdca5 0x0437885fa741f93acfdcda9f5a2e673bb16d26dd22dfc4890775efb8a94fb583 6391537 0x87bf726bc60540c6b91cc013b48024a5b8c1431e0847aadecf0e92c56f8f46fd 6391548 0x4da4052d2baffdc9c0b82d628b87d2c76368914e33799032c6966ee8a3c216a0 3,264 0x705203fc06027379681AEf47c08fe679bc4A58e1 3 0xaf492045962428a15903625B1a9ECF438890eF92 0x88452b56e9aa58b70321ee8d5c9ac762a62509c98d9a29a4d64d6caae49ae757 6507761 0xe6a5a10ec91d12e3fec7e17b0dfbb983e00ffe93d61225735af2e1a8eabde003 6507774 0xd7e70fdf58aca40139246a324e871c84d988cfaff673c9e5f384315c91afa5e4 376 0xdcC655B2665A675B90ED2527354C18596276B0de A thing to note in the following rounds is that participation in the game and amount of pot gradually decreased, presumably owing to the fact that the way of beating the game has been systematized. Although anyone can attempt such an attack, knowing how it will be won takes the “fun” factor out of it.
Credit: Although I’ve found previous instances of the term “block stuffing” online, Nic Carter is the first one to use it in this context.
-
-
Mathematics of Bonding Curves
A bonding curve is a financial instrument proposed by Simon de la Rouviere in his Medium articles. ETH is bonded in a smart contract to mint tokens, and unbonded to burn them. Every bonding and unbonding changes the price of the token according to a predefined formula. The “curves” represent the relationship between the price of a single token and the token supply. The result is an ETH-backed token that rewards early adopters.
 An example supply versus price graph. The area below the curve is equal to the amount of ETH that must be spent to increase the supply from to , or that is going to be received when tokens are unbonded.
An example supply versus price graph. The area below the curve is equal to the amount of ETH that must be spent to increase the supply from to , or that is going to be received when tokens are unbonded.
Inside a transaction, the price paid/received per token is not constant and depends on the amount that is bonded or unbonded. This complicates the calculations.
Let’s say for an initial supply of , we want to bond tokens which are added to the new supply . The ETH that must be spent for this bonding is defined as
which is illustrated in the figure above. If one wanted to unbond tokens, the upper limit for the integral would be and the lower , with E corresponding to the amount of ETH received for the unbonding.
Linear Curves
A linear relationship for the bonding curves are defined as
where is the initial price of the token and is the price increment per token.
Bonding Tokens
Let us have ETH which we want to bond tokens with. Substituting into the integral above with the limits , we obtain in terms of the tokens that we want to bond:
where is the supply before the bonding. Solving this for , we obtain the tokens received in a bonding as a function of the supply and ETH spent:
Unbonding Tokens
Let us have T tokens which we want to unbond for ETH. Unbonding tokens decreases the supply from to , which we apply as limits for the above integral and obtain:
Breaking Even in PoWH3D
PoWH3D is one of the applications of bonding curves with a twist: 1/10th of every transaction is distributed among token holders as dividends. When you bond tokens with ETH, you receive worth of tokens and is distributed to everybody else in proportion to the amount they hold.
This means you are at a loss when you bond P3D (the token used by PoWH3D). If you were to unbond immediately, you would only receive 81% of your money. Given the situation, one wonders when exactly one can break even with their investment. The activity in PoWH3D isn’t deterministic; nonetheless we can deduce sufficient but not necessary conditions for breaking even in PoWH3D.
Sufficient Bonding
Let us spend ETH to bond tokens at supply . The following calculations are done with the assumption that the tokens received
are small enough to be neglected, that is and . In other words, this only holds for non-whale bondings.
Then let others spend ETH to bond tokens and raise the supply to . The objective is to find an large enough to earn us dividends and make us break even when we unbond our tokens at . We have
Our new share of the P3D pool is and the dividends we earn from the bonding is equal to
Then the condition for breaking even is
This inequality has a lengthy analytic solution which is impractical to typeset. The definition should be enough:
}\left\{\frac{9}{10} E(S_2, T_1) + \frac{1}{10}\frac{T_1}{S_2}E_2 = E_1\right\}and
can be obtained from the source of this page in JavaScript from the function
sufficient_bonding. The function involves many power and square operations and may yield inexact results for too high values of or too small values off , due to insufficient precision of the underlying math functions. For this reason, the calculator is disabled for sensitive input. versus for .
versus for .
The relationship between the initial supply and sufficient bonding is roughly quadratic, as seen from the graph above. This means that the difficulty of breaking even increases quadratically as more people bond into P3D. As interest in PoWH3D saturates, dividends received from the supply increase decreases quadratically.
 Logarithmic plot of versus for changing values of .
Logarithmic plot of versus for changing values of .
The relationship is not exactly quadratic, as seen from the graph above. The function is sensitive to for small values of .
Sufficient Unbonding
Let us spend ETH to bond tokens at supply and receive tokens.
Then let others unbond P3D to lower the supply to . The objective is to find a large enough to earn us dividends and make us break even when we unbond our tokens at . We have
Our new share of the P3D pool is and the dividends we earn from the bonding is equal to
Then the condition for breaking even is
Similar to the previous section, we have
}\left\{\frac{9}{10} E(S_2, T_1) + \frac{1}{10}\frac{T_1}{S_2} E(S_2, T_2) = E_1\right\}and
can be obtained from the function
sufficient_unbonding. versus for .
versus for .
The relationship between and is linear and insensitive to . Regardless of the ETH you invest, the amount of tokens that need to be unbonded to guarantee your break-even is roughly the same, depending on your entry point.
Calculator
Below is a calculator you can input and to calculate and .
For the default values above, we read this as:
For 100 ETH worth of P3D bonded at 3,500,000 supply, either a bonding of ~31715 ETH or an unbonding of ~3336785 P3D made by other people is sufficient to break even.
In order to follow these statistics, you can follow this site.
Conclusion
Bonding curve calculations can get complicated because the price paid per token depends on the amount of intended bonding/unbonding. With this work, I aimed to clarify the logic behind PoWH3D. Use the formulation and calculator at your own risk.
The above conditions are only sufficient and not necessary to break even. As PoWH3D becomes more popular, it gets quadratically more difficult to break even from a supply increase. PoWH3D itself doesn’t generate any value or promise long-term returns for its holders. However every bond, unbond and transfer deliver dividends. According to its creators, P3D is intended to become the base token for a number of games that will be built upon PoWH3D, like FOMO3D.
-
Lumped L2 Projection
When utilizing Galerkin-type solutions for IBVPs, we often have to compute integrals using numerical methods such as Gauss quadrature. In such a solution, we solve for the values of a function at mesh nodes, whereas the integration takes place at the quadrature points. Depending on the case, we may need to compute the values of a function at mesh nodes, given their values at quadrature points, e.g. stress recovery for mechanical problems.
There are many ways of achieving this, such as superconvergent patch recovery. In this post, I wanted to document a widely used solution which is easy to implement, and which is used in research oriented codebases such as FEAP.
L2 Projection
Given a function , its projection into a finite element space is defined through the following optimization problem:
Find such that
There is a unique solution to the problem since is convex. Taking its variation, we have $$
for all . Thus we have the following variational formulation
Find such that
for all .
Here,
are our bilinear and linear forms respectively. Substituting FE discretizations and , we have
for , where the FE matrix and vector are defined as
Thus L2 projection requires the solution of a linear system
which depending on the algorithm used, can have a complexity of at least and at most .
Lumped L2 Projection
The L2 projection requires the solution of a system which can be computationally expensive. It is possible to convert the matrix—called the mass matrix in literature—to a diagonal form through a procedure called lumping.
The operator for row summation is defined as
For the mass matrix, we have
since . Substituting the lumped mass matrix allows us to decouple the linear system of equations in (5) and instead write
for . The lumped L2 projection is then as simple as
This results in a very efficient algorithm with complexity.
Conclusion
Lumped L2 projection is a faster working approximation to L2 projection that is easy to implement for quick results. You can use it when developing a solution for an IBVP, and don’t want to wait too long when debugging, while not forgetting that it introduces some error.
-
Disadvantages of Engineering Notation in Finite Elements
Suppose we have the following stiffness matrix of linear elasticity:
where are the gradients of the shape functions and is the linear elasticity tensor (you see the contraction of their components in the equation).
Despite being of the most explicit form, these types of indicial expressions are avoided in most texts on finite elements. There are two reasons for this:
- Engineers are not taught the Einstein summation convention.
- The presence of indices result in a seemingly cluttered expression.
They avoid the indicial expression by reshaping it into matrix multiplications. In engineering notation, the left- and right-hand sides are reshaped as
which allows us to write
The matrices and are set on with tildes in order to differentiate them from the boldface symbols used in the previous sections. Here,
- is a matrix containing the unique components of the elasticity tensor , according to the Voigt notation. In this reshaping, only the minor symmetries are taken into account. If the dimension of the vectorial problem is , then is of the size . For example, if the problem is 3 dimensional, is of the size :
- is a matrix whose components are adjusted so that (2) is equivalent to (1). It has the components of for where is the number of basis functions. Since is adjusted to account for the reshaping of , it has many zero components. A 3d example:
Although (3) looks nice on paper, it is much less optimal for implementation. Implementing it requires the implementation of (5), which adds another layer of complexity to the algorithm. The same cannot be said for (4), because using Voigt notation might be more efficient in inelastic problems. In the most complex problems, the most efficient method is to implement (1) in conjunction with Voigt notation.
To prove the inefficiency of (3) we can readily compare it with (1) in terms of required number of iterations. Indices in (1) have the following ranges:
so iterations are required. Indices in (2) have the following ranges:
so
iterations are required. So engineering notation requires times more equations than index notation. For , engineering notation is times slower and for it is times slower. For example, calculation of a stiffness matrix for and requires iterations for engineering notation, whereas it only requires iterations for index notation.
Although (3) seems less cluttered, what actually happens is that one trades off complexity in one expression for a much increased complexity in another one, in this case (5). And to make it worse, it results in a slower algorithm.
The only obstacle to the widespread adoption of index notation seems to be its lack in undergraduate engineering curricula. If engineers were taught the index notation and summation convention as well as the formal notation, such expressions would not be as confusing at first sight. A good place would be in elementary calculus and physics courses, where one heavily uses vector calculus.
-
Variational Formulation of Elasticity
There are many books that give an outline of hyperelasticity, but there are few that try to help the reader implement solutions, and even fewer that manage to do it in a concise manner. Peter Wriggers’ Nonlinear Finite Element Methods is a great reference for those who like to roll up their sleeves and get lost in theory. It helped me understand a lot about how solutions to hyperelastic and inelastic problems are implemented.
One thing did not quite fit my taste though—it was very formal in the way that it didn’t give out indicial expressions. And if it wasn’t clear up until this point, I love indicial expressions, because they pack enough information to implement a solution in a single line. Almost all books skip these because they seem cluttered and the professors who wrote them think they’re trivial to derive. In fact, they are not. So below, I’ll try to derive indicial expressions for the update equations of hyperelasticity.
In the case of a hyperelastic material, there exists a strain energy function
which describes the elastic energy stored in the solid, i.e. energy density per unit mass of the reference configuration. The total energy stored in is described by the the stored energy functional
The loads acting on the body also form a potential:
where and are the prescribed body forces per unit mass and surface tractions respectively, where with Cauchy’s stress theorem.
The potential energy of for deformation is defined as
Thus the variational formulation reads
Find such that the functional
is minimized for on .
The solution is one that minimizes the potential energy:
A stationary point for means that its first variation vanishes: .
Using and ,
The symmetric part of the term on the right hand side of the contraction is equal to the variation of the Green-Lagrange strain tensor:
Substituting, we obtain the semilinear form in terms of the second Piola-Kirchhoff stress tensor:
We can write a Eulerian version of this form by pushing-forward the stresses and strains. The Almansi strain is the pull-back of the Green-Lagrange strain and vice versa:
 Commutative diagram for the pull-back and push-forward relationships of the Green-Lagrange and
Almansi strain tensors.
Commutative diagram for the pull-back and push-forward relationships of the Green-Lagrange and
Almansi strain tensors.
Thus we can deduce the variation of the Almansi strain
where we have used the identity
The second Piola-Kirchhoff stress is the pull-back of the Kirchhoff stress :
Then it is evident that
We can thus write the Eulerian version of (10):
Introducing the Cauchy stresses , we can also transport the integrals to the current configuration
Here, we substituted the following differential identities:
for the body forces, and
for the surface tractions, where we used the Piola identity.
Linearization of the Variational Formulation
We linearize :
Then we have the variational setting
where
 Commutative diagram of the linearized solution procedure. Each
iteration brings the current iterate closer to the optimum
value .
Commutative diagram of the linearized solution procedure. Each
iteration brings the current iterate closer to the optimum
value .
 Mappings between line elements belonging to the tangent spaces of
the linearization.
Mappings between line elements belonging to the tangent spaces of
the linearization.
The variation is calculated as
Consecutive variations of the Green-Lagrange strain tensor is calculated as
The term on the left is calculated as
where we substitute the Lagrangian elasticity tensor
and is calculated in the same manner as :
Then the variational forms of the linearized setting are
where the bars denote evaluation of dependent variables.
Eulerian Version of the Linearization
We also have the following relationship between the Lagrangian and Eulerian elasticity tensors
Substituting Eulerian expansions, we obtain the following identity:
Thus we have
With these results at hand, we can write the Eulerian version of our variational formulation:
If we introduce the Cauchy stress tensor and corresponding elasticity tensor , our variational formulation can be expressed completely in terms of Eulerian quantities:
We have the following relationships of the differential forms:
where and .
Discretization of the Lagrangian Form
We use the following FE discretization:
where is the number of element nodes and is the number of spatial dimensions.
We use the same discretization for and . Then the linear system at hand becomes
for and where the and are calculated from the variational forms as
For detailed derivation, see the post Vectorial Finite Elements.
For discretized gradients, we have the following relationship
where . For the first term in , we can get rid of the symmetries:
and for the second term, we have
where are the components of the Eulerian metric tensor.
For the first term in , we have
Remaining terms can be calculated in a straightforward manner. We then have for and :
The lowercase indices in and might be confusing, but in fact
The system is solved for at each Newton iteration with the following update equation:
Discretization of the Eulerian Form
Discretization of the Eulerian formulation parallels that of Lagrangian.
Here, denote the spatial gradients of the shape functions. One way of calculating is , similar to (13).
The update equation (44) holds for the Eulerian version.
Conclusion
The equations above in boxes contain all the information needed to implement the nonlinear solution scheme of hyperelasticity.
-
Discontinuous Divergence Theorem
In lecture notes related to the Discontinuous Galerkin method, there is mention of a magic formula which AFAIK first appeared on a paper1 by Douglas Arnold (at least in this context).
It has been proven and all, but it’s still called magic because its reasoning is not apparent at first glance. The magic formula is actually a superset of the divergence theorem, generalized to discontinuous fields. But to make that generalization, we need to abandon the standard formulation which starts by creating a triangular mesh, and consider arbitrary partitionings of a domain.
A domain is partitioned into parts , as follows:

We call the set of parts a partition of .
Broken Hilbert Spaces
We allow the vector field to be discontinuous at boundaries and continuous in , . To this end, we define the broken Hilbert space over partition
It can be seen that .
Part Boundaries
Topologically, a part may share boundary with , like . In that case, the boundary of the part is divided into an interior boundary and exterior boundary:
If a part has an exterior boundary, it is said to be an external part (, , , ). If it does not have any exterior boundary, it is said to be an internal part.(, ).

Divergence theorem over parts
For a vector field , , we can write the following integral as a sum and apply the divergence theorem afterward
We define the portion of the boundary that part shares with as the interface between and .
If and are not neighbors, we simply have .

Integrals over interior boundaries
For opposing parts and ,

we have different values of the function and conjugate normal vectors at the interface :
Since
we can rearrange the integral over interior boundaries as
The jump operator
Integrals over the same interface can be grouped together:
Defining the jump of across
The jump of a function measures its discontinuity across interfaces. We can write
We may drop the superscripts where there is no confusion.
Interfaces and external boundaries
It is convenient to group the interfaces:
which allows us to write
It’s obvious that the union of part external boundaries equals the domain boundary:
which allows us to write
With the results obtained, we put forward a generalized version of the divergence theorem: Let be a vector field. Then we have
Verbally, the integral of the divergence of a vector field over a domain equals its integral over the domain boundary , plus the integral of its jump over part interfaces .

In the case of a continuous field, the jumps vanish and this reduces to the regular divergence theorem.
The Magic Formula
There are different versions of the magic formula for scalar, vector and tensor fields, and for different IBVPs. I won’t try to derive them all, but give an example: If we were substitute a linear mapping instead of , we would have the jump on the right-hand side.
We introduce the vector and tensor average operator
and tensor jump operator
We also note the boundary jump/average property which is used on the integral over
(This property is used implicitly in many places, and often causes confusion).
These definitions allow us to write the identity
which is easily proven when expanded.
The different versions of the magic formula are obtained by substituting the identities above—or their analogs—in the discontinuous divergence theorem.
-
Douglas N. Arnold. An interior penalty finite element method with discontinuous elements. SIAM J. Numer. Anal., 19(4):742–760, 1982. ↩
-
-
Nonlinear Finite Elements
This post builds on the formulations I showed in my previous posts by introducing their nonlinear versions.
In a typical nonlinear problem, the variational setting leads to the weak formulation
Find such that
for all where the semilinear form is nonlinear in terms of and linear in terms of .
We linearize :
Equating (2) to zero yields a linear system in terms of
where
We can compute the components of the matrices and vectors according to (3)
Then the update vector is obtained by solving
Letting be the difference between consequent iterates, we obtain the update equation as
Example: Nonlinear Poisson’s Equation
Consider the following nonlinear Poisson’s equation
The weak formulation reads
Find such that
for all where .
Applying integration by parts and divergence theorem on the left-hand side
Thus we have the semilinear form
The linearized version of this problem is then with (4)
and the matrix and vector components are with (5)
where the previous solution and its gradient are computed as
Nonlinear Time-Dependent Problems
In the case of a nonlinear time-dependent problem, we have the following weak form:
Find such that
for all and where is a semilinear form.
Discretization yields the following nonlinear system of equations
where
Explicit Euler Scheme
We discretize in time with the finite difference and linearity allows us to write
\begin{equation} \boxed{ m(\dot{u}, v; t) \approx \frac{1}{\Delta t} [m(u_{n+1}, v; t_{n+1}) - m(u_n, v; t_n)] } \label{eq:discretetimedependent1} \end{equation}
We discretize the variational forms in time according to \eqref{eq:discretetimedependent1}, and evaluate the remaining terms at :
The corresponding system of equations is
where . This yields the following update equation
For a time-independent , this becomes
Implicit Euler Scheme
For the implicit scheme, we evaluate the remaining terms at and let the result be equal to
We will hereon replace with for brevity. The update of this nonlinear system requires the linearization of :
We thus have the following linear setting for the Newton update :
where
Discretization yields
where
The Newton update is rendered
which is repeated until the solution for the next timestep converges to a satisfactory value.
Nonlinear Coupled Problems
For a nonlinear coupled problem, the weak formulation is as follows
Find , such that
for all , where , are nonlinear in terms of and and linear in terms of and .
We linearize the semilinear forms about the nonlinear terms:
where the evaluations take place at and .
Equating the linearized residuals to zero, we obtain a linear system of the form
with the bilinear forms , , , and the linear forms , which are defined as
Discretizing as done in the previous section, we obtain the following linear system of equations
whose solution yields the update values and . Thus the Newton update equations are
Example: Cahn-Hilliard Equation
The Cahn-Hilliard equation describes the process of phase separation, by which the two components of a binary fluid spontaneously separate and form domains pure in each component. The problem is nonlinear, coupled and time-dependent. The IBVP reads
where
and . Here,
- is the scalar variable for concentration,
- is the scalar variable for the chemical potential,
- is the function representing chemical free energy,
- is a second-order tensor describing the mobility of the chemical,
- is a second-order tensor describing both the interface thickness and direction of phase transition.
The fourth-order PDE governing the problem can be formulated as a coupled system of two second-order PDEs with the variables and , as demonstrated in (35) and (36).
The weak formulation then reads
Find , such that
for all , and .
We discretize in time implicitly with . We also denote the values for the next timestep and as and for brevity. Using integration-by-parts, the divergence theorem, and the given boundary conditions, we arrive at the following nonlinear forms
which is a nonlinear coupled system of the form (29).
We linearize the forms according to (30) and obtain the following variations
We substitute basis functions and obtain our system matrix and vectors
which constitute the system
Solution yields the update values and . The Newton update equations are then
The system is solved for and at each to obtain the evolutions of the concentration and chemical potential.
-
Coupled Finite Elements
In this post, I’ll introduce the FE formulation of a generalized linear and coupled weak form. Said weak formulation has the form
Find , such that
for all , where , , , are bilinear forms and , are linear forms.
Here, the objective is to solve for the two unknown functions and . One can also imagine an arbitrary degree of coupling between variables with equations.
We introduce the following discretizations
where the corresponding number of shape functions are and , respectively.
Substituting the discretizations in (1), we obtain two linear systems of equations
for and .
We write this system as
where the components of given matrices and vectors are defined as
Solution of (4) yields the unknown vectors and .
-
Time-Dependent Finite Elements
Time dependent problems are commonplace in physics, chemistry and many other disciplines. In this post, I’ll introduce the FE formulation of linear time-dependent problems and derive formulas for explicit and implicit Euler integration.
The weak formulation of a first order time-dependent problem reads:
Find such that
for all and .
We can convert (1) into a system of equations
where the components of the matrices and vectors involved are calculated as
If we further discretize in time with the finite difference , linearity allows us to write
This reflects on the system as
Here, , and vice versa for and .
Explicit Euler Scheme
For the explicit Euler scheme, we substitute evaluate the remaining terms at
The corresponding system is
The update equation becomes
If is time-independent, that is , we have
Implicit Euler Scheme
For the implicit Euler scheme, we substitute evaluate the remaining terms at
The corresponding system is
The update equation becomes
If is time-independent, one can just substitute .
Example: Reaction-Advection-Diffusion Equation
The IBVP of a linear reaction-advection-diffusion problem reads
where ,
- is a second-order tensor describing the diffusivity of ,
- is a vector describing the velocity of advection,
- is a scalar describing the rate of reaction,
- and is a source term for .
The weak formulation is then
Find such that
for all and .
We have the following integration by parts relationships:
for the diffusive part and
for the advective part. The canceled terms are due to divergence theorem and the fact that on the boundary. Then our variational formulation is of the form (1) where
From these forms, we obtain the following system matrices and vector
where is constant through time.
-
Vectorial Finite Elements
Many initial boundary value problems require solving for unknown vector fields, such as solving for displacements in a mechanical problem. Discretization of weak forms of such problems leads to higher-order linear systems which need to be reshaped to be solved by regular linear solvers. There are also more indices involved than a scalar problem, which can be confusing. In this post, I’ll try to elucidate the procedure by deriving for a basic higher-order system and giving an example.
The weak formulation of a linear vectorial problem reads
Find such that
for all .
Discretizations of vectorial problems requires the expansion of vectorial quantities as linear combinations of the basis vectors :
where are the components corresponding to the basis vectors and . Here, we chose Cartesian basis vectors for simplicity.
We can therefore express its discretization as
Substituting discretized functions in the weak formulation, we obtain
and
We define the following arrays
Hence we can express the linear system
as
For arbitrary , this yields the following system of equations
for and .
We reshape this higher-order system as shown in the previous post Reshaping Higher Order Linear Systems:
by defining a map that maps original indices to the reshaped indices
where we used 1-based indexing of the arrays. We set
and write
The inverse index mapping can be obtained as shown in the previous post.
Example: Linear Elasticity
Our initial-boundary value problem is
The weak formulation reads
Find such that
for all where .
We apply integration by parts on the left-hand side
and apply the divergence theorem to the first resulting term:
Substituting the linear stress , we obtain the following variational forms:
We have the following discretizations of the unknown function and test function
With the given discretizations, the matrix corresponding to (18) can be calculated as
and finally obtain
The vector corresponding to (19) is calculated as
which yields
-
Reshaping Higher Order Linear Systems
In vectorial problems, we end up with linear systems of higher order, such as
for and .
These systems cannot be solved readily with existing software. In order to be able to solve them with existing software, we need to reshape them by defining a matrix of matrices and vector of vectors and :
This allows us to express the linear system as
Here, we reshape the system by defining a map that maps original indices to the reshaped indices
where we used 1-based indexing of the arrays. We set
and write
For reference, the inverse of the index mapping reads
Thus, we have for our reshaped indices,
Expressed as a regular linear system (3), the higher-order system (1) can be solved with a linear solver such as LAPACK.
-
Linear Finite Elements
Beginning with this post, I’ll be publishing about the basics of finite element formulations, from personal notes that accumulated over the years. This one is about linear and scalar problems which came to be the “Hello World” for FE. Details regarding spaces and discretization are omitted for the sake of brevity. For those who want to delve into theory, I recommend “The Finite Element Method: Theory, Implementation, and Applications” by Larson and Bengzon.
The weak formulation of a canonical linear problem reads
Find such that
for all where is a bilinear form and is a linear form.
We define the discretization of as
The discretization is a linear combination of basis functions and corresponding scalars , so that is a subset of . The discretization of (1) then reads
We then have
Using the linearity properties,
we obtain
For arbitrary test function values , we can express (6) as a system of equations
for . If we expand the summations as
we can see that the terms with constitute a matrix and the terms with constitute a vector , allowing us to write
where we chose to express the unknown coefficients as a vector .
\It can be seen that the components of the and are defined as
we can express the linear system as
Note that with the given definitions, (7) becomes
Example: Poisson’s Equation
In the weak form of Poisson’s equation
The weak formulation reads
Find such that
for all where .
Applying integration by parts and divergence theorem on the left-hand side
We have the following variational forms:
Following (7), we can calculate the stiffness matrix as
where we have defined the gradient of the basis functions as
Similarly, we integrate the force term into a vector as
-
Balance Laws
Calculus is all about relating the change in one quantity to another quantity.
Imagine it this way: You have a box full of marbles, and you decide to put some more in. is the variable representing the amount of marbles, while is the variable representing the amount of marbles that you put in. If you had marbles at the beginning, you have
marbles following your action. This is the most fundamental algebraic pattern that characterizes balance laws.
Take the first law of thermodynamics for example—a.k.a. balance of energy. We have
where is the internal energy of a closed system, is the amount of heat supplied to the system, and is the amount of work done on the system on its surroundings. Here, and . Despite having three quantities, it is the combined effect of two which is related to the remaining quantity. Balance laws derived by physicists and chemists can get quite complex and hard to understand.
It’s always that the change in one quantity is related to the combined effect of remaining quantities. Keeping separate track of your main variable and affecting variables that compose gives you a mental model which helps you remember and even build your own balance laws.
Introducing Time
Let be a function of time. We can rewrite the equation in terms of the change in in a time period :
where the new variable represents the change in quantity in amount of time. In our previous analogy, is the amount of marbles put in, say, a minute. As , we have
This prototypical balance law allows us to relate the rates of change of quantities.
Let’s introduce time into the balance of energy. The equation becomes
where the new quantities and are called thermal power and mechanical power, representing the thermal and mechanical work done on the system per unit time, respectively. Given power functions and initial conditions, integrating them would give us the evolution of the internal energy through time.
Introducing Space
Let’s say we are not satisfied with an abstract box where the amount of stuff that goes in is measured automatically. We want to write a balance law over different shapes of bodies and we need to specify exactly where the stuff goes in and out.
To do that, we need to rephrase our laws to work over a continuous domain. The branch of physics that focuses on such problems is called continuum mechanics.
We introduce our spatial domain and its boundary . Our quantities now vary over both space and time, so we need to integrate them over the whole domain in order to relate them:
where
- is the variable representing the main continuous quantity,
- is the variable representing the rate of change of the quantity inside the domain,
- and is the variable representing the negative rate of change of the quantity on the boundary of the domain—negative due to surface normals having outward direction by definition.
Notice that when we introduce space, our prototypical balance law needs an additional vectorial quantity, . In physical laws, one needs to differentiate actions inside a body from actions on the surface of the body. That’s because one is over a volume and the other over an area, and they have to be integrated separately.
The area integral is actually a flux where the vectorial quantity is penetrating the surface with a given direction. Given that it’s positive when stuff exits the domain, it’s called the efflux of the underlying quantity. Similarly, we name the rate of change field as the supply of the underlying quantity, because it being positive results in an increase.
The idea is to get rid of the integrals by a process called “localization”. In order to localize, we have to convert the surface integral into a volume integral using the divergence theorem:
Assuming doesn’t move, we can also write
Collecting the results, we have
Notice that all integrals are over now. This allows us to make the balance law more strict by enforcing it point-wise:
This is the localized version of the prototypical balance law that is used everywhere in continuum mechanics. Unfortunately, I can’t give the energy balance example, because it would require too many additional definitions. For that, I recommend the excellent Mathematical Foundations of Elasticity by Marsden and Hughes.
Conclusion
In physics and chemistry, one shouldn’t blindly memorize formulas, but try to see the underlying logic. In this case, I tried to elucidate balance laws, which all build upon the same algebraic and geometrical concepts. I went from discrete to continuous by introducing time and space to the equations, which became more complex but retained the same idea: putting things in a box and trying to calculate how that changes the contents.
-
Taylor and Volterra Series
In the theory of computational mechanics, there are a few operations used that are not taught in Calculus 101, which can be confusing without taking a lecture in calculus of variations. One of them is taking variations (a.k.a. Gateaux derivatives), akin to taking directional derivatives, but with functions of functions called functionals.
You need to take variations when you are linearizing a nonlinear problem for the purpose of solving with a numerical scheme. Linearization is the process of expanding a function or functional into a series, and discarding terms that are of order higher than linear—i.e. quadratic, cubic, quartic, etc. These expansions are called Taylor for functions, and Volterra for functionals.
Taylor Series
A function can be expanded about a point as a power series:
Letting be a perturbation from the expansion point , that is , the series can also be phrased as follows
This is what is taught in Calculus 101 and everyone knows. Now for the part that you may have missed:
Variation
Let be the space of functions . The variation of a functional is defined as
where is called the perturbation of the variation. This operation is analogous to taking the directional derivative of a function.
Shorthand notation
When working with variational formulations, writing out variations can be a bit of a hassle if there are many symbols involved. Therefore we use the following shorthand for variations:
Here, we assume that there is no chance of confusing the varied function or perturbation. We use this shorthand in contexts where the perturbation does not play an important role.
The shorthand for evaluation is
where there is no risk of confusion for .
Volterra Series
Let be the space of functions . Analogous to the Taylor series, a functional can be expanded about a point as a power series:
where is the perturbation of the expansion. This is called the Volterra series expansion of . Verbally, the Volterra series expansion of a functional about a function is the infinite sum of the variations of the functional with increasing degree, evaluated at that function, each divided by the factorial of the degree.
In shorthand notation, the expansion is rendered
To me, there is an elegance in (7) that is not reflected in (2) or (6).
-
Isomorphisms in Linear Mappings between Vector Spaces
Equipping a vector space with an inner product results in a natural isomorphism , where the metric tensor can be interpreted as the linear mapping and its inverse .
Notation: Given two real vector spaces and , we denote their inner products as and respectively. Given vectors and , we define their lengths as
Regarding and ,
- their bases are denoted and ,
- their dual bases are denoted and ,
- their metrics are denoted and with the components and ,
respectively. Here, the indices pertaining to are uppercase and the indices pertaining to are lowercase .
Definition: Let be a linear mapping. Then the transpose, or adjoint of , written , is the linear mapping
for all and . Carrying out the products,
For arbitrary and ,
from which we can obtain the components of the transpose as
If is a linear mapping, it is called symmetric if .
Definition: Let be a linear mapping. Then the dual of is a metric independent mapping
defined through natural pairings for all and . Carrying out the products,
For arbitrary and , we obtain the components of the dual mapping as
To fully appreciate the symmetry that originates from the duality, we can think of not just the mappings between and , but also between their dual spaces. To this end we can enumerate four mappings corresponding to and their duals, corresponding to . Their definitions can be found in the table below.
Mappings
Duals
Tensors , , and as linear mappings (top), and their duals , , and (bottom). In the respective tables, the first row displays the tensor spaces, basis vectors and components of the subsequent mappings, and the second and third row display the representations of the tensor as linear and bilinear mappings respectively. The results of the mappings are given in the mapping, matrix and index representations respectively. The mappings are over vectors , and one-forms , . The commutative diagrams pertaining to these mappings can be found in the figure below
 Commutative diagrams involving
the linear mappings and
their dual
based on the metrics and
of and .
Commutative diagrams involving
the linear mappings and
their dual
based on the metrics and
of and .
-
Metrics and Natural Isomorphisms
The assignment of an inner product to a non-degenerate and finite-dimensional vector space , results in emergence of the natural isomorphism to its dual , which means that the morphisms and are of the same structure and one is the inverse of the other. The notion of naturality (of an isomorphism) becomes most clear in the context of category theory; however it should be sufficient for now to say that a natural isomorphism between a vector space an its dual is one that is basis-independent. As the origin of the isomorphism, the inner product is encapsulated in an object called the metric, defined below, in order to make the resulting symmetry of the mappings more obvious.
In the context of differential geometry, the metric object is used synonymously with the inner product of a vector space. More specifically, the metric tensor
of a real vector space is an object whose components contain the information necessary to linearly transform a vector to its covector. This operation is denoted by the symbol and reads
We simply define the one-form as
We input the basis vectors
and define the components of the metric tensor as
We then simply say that the operator denotes an index lowering1 through
Moreover, we can define the inverse of the metric tensor as
The operation of transforming a covector to its corresponding vector is denoted by the symbol and reads
Here, the vector corresponding to the covector is denoted and reads
We input the dual basis vectors
and define the components of the inverse metric as
Then the operator denotes an index raising through
In some literature, the natural isomorphism is called the musical isomorphism—which is also the origin of the notation introduced above—because the process of transforming a vector to its dual space and a covector to the original space is analogous to lowering and raising notes.
With the given definition of the metric, we can elaborate on the advantage of denoting inner products of different objects with different symbols. Whereas always denotes a natural pairing between a vector space and its dual, one can write to denote an inner product of vectors and to denote an inner product of covectors. Using the metric, we can link these notations as
for all and . Similarly,
Despite the symmetricity of the inner product, we choose to think of the first operand as a vector and the second as a covector in a natural pairing, as a convention.
The metric tensor has the following properties:
- For orthonormal bases, the metric tensor equals the identity tensor, that is, .
- The diagonal terms equal to the square of the lengths of the basis vectors, that is, (no summation).
- The off-diagonal terms are zero if the basis vectors are orthogonal. Specifically, iff and are orthogonal.
-
In musical notation, the flat symbol is used to lower a note by one semitone, whereas the sharp symbol is used to raise a note by one semitone. It is recommended to pronounce as v-flat and alpha-sharp. ↩
-
Duality of Vector Spaces
When I was learning about Continuum Mechanics for the first time, the covariance and contravariance of vectors confused the hell out of me. The concepts gain meaning in the context of Riemannian Geometry, but it was surprising to find that one doesn’t need to learn an entire subject to grasp the logic behind co-/contravariance. An intermediate knowledge of linear algebra is enough—that is, one has to be acquainted with the concept of vector spaces and one-forms.
The duality of co-/contravariance arises when one has to define vectors in terms of a non-orthonormal basis. The reason such terminology doesn’t show up in engineering education is that Cartesian coordinates are enough for most engineering problems. But every now and then, a complex problem with funky geometrical requirements show up, like one that requires measuring distances and areas on non-flat surfaces. Then you end up with dual vector spaces. I’ll try to give the basics of duality below.
Definition: Let be a finite-dimensional real vector space. The space , defined as the the space of all one-forms , is called the dual space to .
Let be a basis of . Any vector can be written in terms of as
with the components . For any , we can define the -th component by a one-form as
These elements are linear and thus are in the space 1. Given any basis , we call the basis of dual to . The fact that really is a basis of can be proved by showing that are linearly independent. Then has the following representation
Instead of , it is practical to denote the components of as , lightface of the same symbol with a raised index corresponding to the raised index of the dual basis:
In fact, this convention is more compatible with the symmetry caused by the duality. This point will be more clear after the introduction of dual basis representation of one-forms.
Proposition: Each can be identified by its action on the basis :
Proof: For any , must give , the -th component of . Setting , one sees that when , and is zero otherwise.
Geometrically, (5) implies that a basis vector is perpendicular to all the dual basis vectors, except its own dual.
Dual Basis Representation of One-Forms
Let be a one form in with the corresponding dual basis . Then similar to a vector, has the following representation
where the components of the one-form are defined as
Proof: We substitute (3) and obtain
using ‘s linearity.
Notation: Let be a finite-dimensional real vector space. For and
denotes the action of on , and is called a natural pairing or dual pairing between a vector space and its dual. It is of the essence to understand that does not denote an inner product in ; that is, means .
With this notation, (3) can be written as
and (5) as
Using the convention that are column vectors and are row vectors, (11) can be rearranged in the following manner
which can be used to compute a dual basis.
Example: Given a two-dimensional vector space with a basis , , we use (12) to compute
and obtain the dual basis vectors as and . The result is given in the following figure,

where one can see that , .
 A body embedded in with curvilinear coordinates.
Every point at has an associated two-dimensional vector space,
called 's tangent space at , denoted . The basis
corresponding to coordinates are not necessarily
orthogonal and can admit corresponding duals , due to
curvilinearity.
The coordinates appear to be affine at the point's immediate vicinity,
and thus in the tangent space.
A body embedded in with curvilinear coordinates.
Every point at has an associated two-dimensional vector space,
called 's tangent space at , denoted . The basis
corresponding to coordinates are not necessarily
orthogonal and can admit corresponding duals , due to
curvilinearity.
The coordinates appear to be affine at the point's immediate vicinity,
and thus in the tangent space.
The introduction of the dual space allows us to reinterpret a one-form as an object residing in the dual space. In fact, the canonical duality states that every vector can be interpreted as a functional on the space via
-
Despite being denoted with bold letters, one-forms should not be confused with vectors. ↩
-
-
Solving Constrained Linear Systems
Constrained linear systems arise when Dirichlet boundary conditions are imposed on a variational formulation
Find such that
for all , where
where is the Dirichlet condition.
We additively decompose the solution into known and unknown parts:
and substitute into our variational formulation
We can take advantage of the linearity condition, and reformulate the variational formulation:
Find such that
for all .
The algorithmic analogue of this formulation will be developed in the following section Direct Modification Approach.
Static Condensation Approach
For a linear system
of size , we constrain the values of the solution or right-hand side at certain degrees of freedom. We sort the system so that these degrees of freedom are grouped together after the unconstrained degrees of freedom. The resulting system is,
Defining submatrices and vectors for the partitions, we can write
or
Let and have defined values. The objective is to solve for unknown and . We have
and
\begin{align} \Bb_2 = (\BA_{22}-\BA_{21}\BA_{11}\inv\BA_{12})\Bu_2 + \BA_{21}\BA_{11}\inv\Bb_1 \end{align}
In case , we have
and in case , we have
Example: Plane Stress and Strain in Linear Elasticity
The constitutive equation of isotropic linear elasticity reads
The plane stress condition reads . We group the constrained degrees of freedom together:
which we write as
The purpose is to obtain a reduced system without or . We substitute the plane stress condition , to obtain . Then we have
We define the plane stress version of the elasticity tensor as which results in
The plane strain condition reads . This simply results in
The plane strain version of the elasticity tensor is calculated as
The procedure defined above is called static condensation, named after its application in structural analysis. One impracticality of this formulation is that systems do not always exist with their constrained degrees of freedom grouped together. These are generally scattered arbitrarily throughout the solution vector, and grouping them manually is impractical with current data structure implementations.
Direct Modification Approach
Suppose we have a system where and are known and and are unknown:
We can modify the system so that it can be solved without separating the partitions
We can additively decompose both sides
Therefore, the following is equivalent to (10):
This is solved for :
The unknown right hand side can be obtained from the original matrix
Observe that the modifications on are symmetric, so we do not need the constrained degrees of freedom be grouped together. is obtained by zeroing out the rows and columns corresponding to constraints and setting the diagonal components to one. For , we do not need to extract ; we simply let
where
We then equate the constrained degrees of freedom to their specified values .
Below is a pseudocode outlining the algorithm.
fun solve_constrained_system(A, b_known, u_known, is_contrained): # A: unmodified matrix, size NxN # b_known: known values of the rhs, size N # u_known: known values of the solution, size N # is_constrained: bool array whether dof is constrained, size N N = length(b) A_mod = copy(A) b_mod = b_known - A_known*u_known # Calculate rhs vector for i=1 to N do: if is_constained[i] then: for j = 1 to N do: A_mod[i][j] = 0 # Set row to zero A_mod[j][i] = 0 # Set column to zero endfor A_mod[i][i] = 1 # Set diagonal to one b_mod[i] = u_known[i] endif endfor u = inverse(A_mod)*b_mod # Solve constrained system # Could also say solve(A_mod, b_mod) b = A*u # Substitute solution to get final rhs vector return u, b endfunConstrained Update Schemes
When using an iterative solution approach, one generally has an update equation of the form
where is the solution vector of the primary unknown. The update vector is obtained by solving a linear system and added to the solution vector in each iteration. This process is usually terminated when the approximation error drops below a threshold value.
\When the solution vector itself is constrained, the update system needs to be modified accordingly. Grouping the constrained degrees of freedom together,
Let be known and be unknown.
We can make the substitution :
This system can then be solved for the unknown and with the procedure defined in the previous section. The only difference is that,
-
Simple recursive implementation of deCasteljau's algorithm for Bezier curves in Python
I could not find a simple demonstrative example of *insert title here*. I am leaving this out here for future reference.
Note that a recursive implementation for deCasteljau’s is not efficient, since it results in unnecessary multiple computation of some intermediary points.
def deCasteljau(points, u, k = None, i = None, dim = None): """Return the evaluated point by a recursive deCasteljau call Keyword arguments aren't intended to be used, and only aid during recursion. Args: points -- list of list of floats, for the control point coordinates example: [[0.,0.], [7,4], [-5,3], [2.,0.]] u -- local coordinate on the curve: $u \in [0,1]$ Keyword args: k -- first parameter of the bernstein polynomial i -- second parameter of the bernstein polynomial dim -- the dimension, deduced by the length of the first point """ if k == None: # topmost call, k is supposed to be undefined # control variables are defined here, and passed down to recursions k = len(points)-1 i = 0 dim = len(points[0]) # return the point if downmost level is reached if k == 0: return points[i] # standard arithmetic operators cannot do vector operations in python, # so we break up the formula a = deCasteljau(points, u, k = k-1, i = i, dim = dim) b = deCasteljau(points, u, k = k-1, i = i+1, dim = dim) result = [] # finally, calculate the result for j in range(dim): result.append((1-u) * a[j] + u * b[j]) return resultA demonstration of the above function
import numpy as np import pylab as pl import math # insert deCasteljau function definition here points = [[0.,0.], [7,4], [-5,3], [2.,0.]] def plotPoints(b): x = [a[0] for a in b] y = [a[1] for a in b] pl.plot(x,y) curve = [] for i in np.linspace(0,1,100): curve.append(deCasteljau(points, i)) plotPoints(curve) pl.show()For Rational Bezier Curves
With a small modification, same function can be used for rational Bezier curves
def rationalDeCasteljau(points, u, k = None, i = None, dim = None): """Return the evaluated point by a recursive deCasteljau call Keyword arguments aren't intended to be used, and only aid during recursion. Args: points -- list of list of floats, for the control point coordinates example: [[1.,0.,1.], [1.,1.,1.], [0.,2.,2.]] u -- local coordinate on the curve: $u \in [0,1]$ Keyword args: k -- first parameter of the bernstein polynomial i -- second parameter of the bernstein polynomial dim -- the dimension, deduced by the length of the first point """ if k == None: # topmost call, k is supposed to be undefined # control variables are defined here, and passed down to recursions k = len(points)-1 i = 0 dim = len(points[0])-1 # return the point if downmost level is reached if k == 0: return points[i] # standard arithmetic operators cannot do vector operations in python, # so we break up the formula a = rationalDeCasteljau(points, u, k = k-1, i = i, dim = dim) b = rationalDeCasteljau(points, u, k = k-1, i = i+1, dim = dim) result = [] # finally, calculate the result for j in range(dim+1): result.append((1-u) * a[j] + u * b[j]) # at the end of first and topmost call, when the recursion is done, # normalize the result by dividing by the weight of that point if k == len(points)-1: for i in range(dim): result[i] /= result[dim] # dimension is also the index with the weight return resultWe can demonstrate by e.g. comparing the algorithm’s results with a circular arc
import numpy as np import pylab as pl import math # insert rationalDeCasteljau function definition here points = [[1.,0.,1.], [1.,1.,1.], [0.,2.,2.]] def plotPoints(b): x = [a[0] for a in b] y = [a[1] for a in b] pl.plot(x,y) curve = [] # limit to 5 points to show the difference with analytic solution for i in np.linspace(0,1,5): curve.append(rationalDeCasteljau(points, i)) plotPoints(curve) # plot the actual circular arc arc_x = np.linspace(0,1,100) arc_y = [] for i in arc_x: arc_y.append(math.sqrt(1-i*i)) pl.plot(arc_x, arc_y) pl.show()I am not actually working on Bezier curves, but NURBS. My reference for studying is The NURBS Book by Piegl and Tiller, which is excellent so far.